マルチコアCPU上の並列化手法、その並列性能と問題点
PGIコンパイラによる GPU Computing シリーズ (1)
GPU を使用した並列計算環境が一般的になりつつあります。ユーザサイド立ってみれば、「並列化適用方法の種類とその効果」をもう一度整理して考え、自分に合った手法を選択しなければいけないと思っている方も多いことでしょう。並列計算と言っても、プロセッサ・コア自体が自動的にSIMD(ベクトル処理)実行するものから、マルチコアを利用した自動並列、OpenMPによるスレッドレベルの並列実行、さらにプログラムを改造してマルチプロセスによる MPI 並列実行と様々な手法が用意されています。さらに、今、GPUを利用した many cores 並列を利用した並列実行も加わり、ユーザにとっては、自分でも手軽にできる方法の判断やその性能効果に関する一つの判断基準を持っておくことが必要でしょう。また、簡単な並列実行の原理等の知識があるだけでも、今後の many cores 並列時代に向けて、合理的な並列化のための指針や性能に関する判断を行うこともできます。このコラムは、現在のマルチコア・プロセッサ(IntelやAMDのMPU)に焦点を当て、そのプロセッサ上で実現できている並列化手法とその並列性能に関する知見、現在のプロセッサ技術の問題点等を簡単に整理することを目的として説明します。そして、GPU並列の話につなげていきます。
2010年2月16日 Copyright © 株式会社ソフテック 加藤
まず、最初の疑問:4コア上で、OpenMPスレッド並列の効果が思った程、上がらない!なぜなの?
最初に、現在の x64 系プロセッサ技術の問題となる大きなポイントを理解することから始めます。例えば、OpenMPで完璧に並列化してあるはずなのに、マルチコア上の並列のスケーラビリティ(性能向上の度合い)が、あまり良くないと言うことは、多くの方が経験しているのではないでしょうか?この答えは、ずばり、「メモリからプロセッサまでのデータ供給能力(データ転送速度だけでなく、キャッシュ等の周辺メカニズムを含めた能力)が、プロセッサ自体の処理能力に較べて劣っている」ことに尽きます(詳細は後述します)。この問題は、今までのプロセッサ技術における究極の課題なのです。そうとは言え、この課題を克服するために、キャッシュメカニズムの向上や AMD の Opeteron やIntel®の Nehalemプロセッサが採用する NUMA メモリアーキテクチャの採用、さらに本質的なメモリ部材の高速化等、いろいろな技術が現在のプロセッサには適用されています。それでもなお、メモリ転送性能は、現在のマルチコア時代のプロセッサの処理能力から比べれば、絶対的に低いと言う状況になっています。これは、メモリ性能が高速であると言われている Nehalem のプロセッサ構造であっても同様です。いかに「頭となる演算処理能力」があっても、その足回りとなる「データのロードとストア」処理が追いつかなければ、全ての処理は完成しません。すなわち、プロセッサの演算器がデータを待つ状況が生まれ、結果的に性能が遅くなると言う構図になってる訳です。
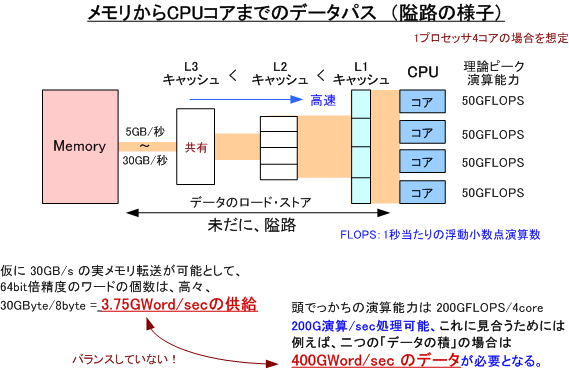
もちろん、プロセッサ側もこのメモリ性能の弱点を補うために、「キャッシュ」というメカニズムを採用しています。今では、L1/L2/L3 等の階層型のキャッシュ構造となっています。キャッシュは、低速なメモリ素子とプロセッサとの間に介在する高速なバッファーとなりますが、これがまた、マルチコアでスレッド並列処理するようになってくると、プログラムで使用する「共有データ」のキャッシュ上の内容の同一性を維持するために余計なコストが掛かってくるようになります。マルチコアを使ってマルチスレッド並列を行う時には、より顕著に並列実行を阻害する要因が現れてきます。(昔のような1コアしかないプロセッサの時代は、こうした現象に関してはまだ単純でした。)ここでは、マイクロ・アーキテクチャ的な専門的な説明はしませんが、現在、「速い」と称されているプロセッサであっても、そのプロセッサとメモリとの間の道は、未だに「隘路」であり、これに伴う様々な要因がプログラムの性能を落とす原因となっていることを理解してください。ましてや、HPC分野のシミュレーションプログラムは、大きなメモリ領域の「全てのデータをアクセスする」と言う特性を持ちます。これは、キャッシュを有効利用することが難しい側面があると言うことでもあり、結局、実効メモリ性能が、全体性能を決め得る律速ポイントとなると言うことになります。
こうした事実を捉えれば、マルチコアのCPU計算においても、あるいはGPU計算においても、現存のプロセッサ技術の上では、「メモリアクセス(方法等)を何らかの方法で高速化(最適化)すること」が、最大の「全体性能高速化手法」であることが言えます。今後のコラムで説明する GPU 並列計算の場合においても、同様なことが言えます。また、GPUのメモリアーキテクチャは、こうした従来のプロセッサのキャッシュをベースとした構造から大きく変革し、いわゆる「ベクトル・スパコン」のミニチュア版のようなデータ・ストリームを採用した(具体的に言えば、コアレッシング・アクセス等)と考えれば、なぜ「GPU演算が速いのか」と言う問いに対する答えになるでしょう。これは、今後のGPU特集のコラムで説明します。
それでは、実メモリ性能が実際のスレッド並列の性能や、プロセッサコア内の SSE 処理(SIMD、ベクトル処理)等に影響する様子を性能実測ベースで見てもらうことにします。この体感は、これから連載する予定の「様々な並列性能」の定量的な判断の一助となることでしょう。さらに、皆さんは、もっと大きなことに気づくかもしれません。購入プロセッサの選択においては、クロック値の高い、別の言葉で言えば、「市場価格が高い」プロセッサ・モデルをメーカーの思惑通りに購入することよりは、価格の妥当な、クロック値のやや低いプロセッサ・モデルを使う方が合理性があると言うことです。特に、マルチコアによるスレッド並列処理をする場合は、一番価格が妥当なプロセッサ・モデルを選ぶべきでしょう。そして、メモリ部材の足回りは、お金をかけても強化するべきと思います。
性能実測するシステム環境について
まず始めに、性能実測に使用する私のテストマシン環境について説明します
| ホスト側プロセッサ | Intel(R) Core(TM) i7 CPU 920 @ 2.67GHz x 1 プロセッサ |
| ホスト側メモリ | PC3-10600(DDR3-1333)2GB x 2 枚 |
| ホスト側 OS | Cent OS 5.4、カーネル 2.6.18-164.el5 |
| PGI コンパイラ | PGI 10.2 (PGI 2010) |
Core i7 のプロセッサ(4コア)を1個積んでいる単純な 4GBメモリの CentOS 5.4 の Linux マシンです。問題は、メモリ性能が理想的なものよりやや悪く、さらに2枚のメモリモジュールしか実装していないため、最適なメモリモジュール配置構成を有していないと言うことです。実際のメモリ帯域(転送速度)を STREAM ベンチマークの triad 性能で示すと以下のようになります。それでも、16GB/sec を超えるメモリバンド幅の4コアマシンを10万円台で手に入れることができるとは、従来の感覚から言うとすばらしい変化と言えるでしょう。
褒め言葉で言うと確かにインテル社のプロセッサに関しては Nehalem になってから大きな変化を遂げたと言うことはできますが、プロセッサ内のコア数の増加に伴うだけのメモリ帯域の向上を成し遂げているわけではありません。このシステムだけで言うと、 2スレッドも 4 スレッドの並列メモリバンド幅が 16GB/sec 程度と同じであり、帯域が飽和していることが分かります。こうした状況が、現在の x64 系のプロセッサのメモリ・アーキテクチャの限界と言うことができます。
| 1 OpenMP スレッド | Triad: 14780.6029 (MB/s) |
| 2 OpenMP スレッド | Triad: 16612.4756 (MB/s) |
| 4 OpenMP スレッド | Triad: 15955.8867 (MB/s) |
ちなみに、Core i7 の前のマイクロアーキテクチャである Core 2 600@ 2.40GHz のプロセッサ(2コア)の場合のメモリバンド幅はどの程度でしょうか? 以下のように大体 5GB/sec 程度の帯域を有しています。Core i7 の 1/3 程度しかメモリの帯域を有していないことが分かります。
| 1 OpenMP スレッド | Triad: 5366.3622 (MB/s) |
| 2 OpenMP スレッド | Triad: 5099.2253 (MB/s) |
性能評価のために使用するプログラムについて
ここでの説明に用いる OpenMP プログラムは、OpenMP.org で提供している Fortran サンプル・プログラム(オリジナル・ソース)を使用します。これは、今後説明する PGI Accelerator による GPU 並列の説明のページでも使用します。 このプログラムは、ヘルムホルツ式を差分で離散化したものをヤコビ反復法で解くものです。普通のユーザが、特殊なソースレベル最適化(キャッシュ最適化等の技法)を施さないでコーディングした一般的なプログラムです。本プログラムの計算で使用するデータのサイズは、プロセッサ内のキャッシュに入りきらない大きなデータの計算を行います。これは、HPCの一般的なシミュレーションでは、そのデータサイズが大きいためキャッシュ効果は期待できないことを想定したものであり、こうした場合の性能等の知見を得るためです。今回の性能評価の目的で、オリジナルのソースに一部改変を行っています。入力データを性能評価用に特定の入力値をセットし、オリジナルは配列の割り当てに危ないコーディングをしているため、動的アロケーションするように変更しています。なお、ベンチマークのため収束条件は考慮せず、常に100回のヤコビ反復を処理します。 また、時間計測のルーチンを追加しています。
最適化レベルを変えた場合のPGIコンパイラのオプションの設定方法 $ pgf95 -O1 -Minfo -mp jacobi.f(最適化レベル-O1) $ pgf95 -O2 -Minfo -mp jacobi.f(最適化レベル-O2) $ pgf95 -fastsse -Minfo -mp jacobi.f(最適化レベル-O2 + SSEベクトル化) (-mp は、OpenMPディレクティブを解釈し並列コードを生成する)
実測したスレッド並列性能の傾向から、メモリ性能が飽和している状況を知る!
さて、今回の試みは、最適化レベルの異なる実測性能値から、プロセッサとメモリ間で何が起きているかを推測する方法をとります。すなわち、並列化した性能が飽和していると言う状況が存在した場合、メモリのデータ転送能力を使い切っていると言う判断をします。もちろん、マイクロアーキテクチャ的に見れば、他にも性能が飽和する要因が多数あるのですが、しかし、マクロ的な意味での主な原因はこのメモリ性能が起因したものと判断して良いでしょう。
倍精度版プログラムの最適化レベルの違いによる性能の変化
まず、以下の表を見ていただきましょう。これは、jacobi.f をコンパイラの最適化レベルを変えてコンパイルしたときの計算時間結果を表したものです。さらに、OpenMP並列で、最大4並列スレッドを使用して計算した結果でもあります。ここで注目する数値は、各最適化のレベルで、計算スレッド数を増加したときの並列効果の変化です。その傾向を見ると、最適化のレベルが高度になるほど、並列化の効果が鈍っていく様子が見られます。特に、-fastsse と言うオプションを指定した時の4つのコアによる並列時の性能効果は、1スレッドに対して高々 1.46倍にしかなりません。これは、ソフトウェア的な OpenMP 並列化に問題があるのではなく、メモリ帯域の不足による性能低下と見ることができます。もちろん、この根本的な原因は、メモリモジュールの性能やその実装構成等に強く影響を受けるものであり、私のテスト機のメモリ構成がもう少し良いものであれば、並列性能もさらに良くなることでしょう。一方、-O1 レベルでの4スレッドの並列効果は 3.08 倍ありますので、それなりの並列化が達成されていると見ることができ、並列粒度的にも十分と判断されます。CPU内部の演算量に対して、相対的にメモリからのデータの供給が十分にできていると見ることができます。一般に、並列効果が期待されたものになっていない場合、ソフトウェア実装における「並列化」方法に問題の焦点を向けがちですが、その場合の検証方法としては、最適化レベルを落としたときにも並列化効果が良くないかどうかを検証することをお勧めします。
| 最適化オプション | 1スレッド | 2スレッド | 4スレッド |
|---|---|---|---|
| -O1 | 66.75 | 37.54 | 21.67 |
| 並列効果 | 1.00 | 1.78 | 3.08 |
| -O2 | 53.83 | 30.92 | 20.12 |
| 並列効果 | 1.00 | 1.74 | 2.67 |
| -fastsse | 23.06 | 16.66 | 15.84 |
| 並列効果 | 1.00 | 1.38 | 1.46 |
単精度版プログラムの最適化レベルの違いによる性能の変化
| 最適化オプション | 1スレッド | 2スレッド | 4スレッド |
|---|---|---|---|
| -O1 | 61.02 | 31.59 | 16.57 |
| 並列効果 | 1.00 | 1.93 | 3.68 |
| -O2 | 34.70 | 19.85 | 11.76 |
| 並列効果 | 1.00 | 1.75 | 2.95 |
| -fastsse | 11.86 | 8.58 | 7.93 |
| 並列効果 | 1.00 | 1.39 | 1.49 |
プログラムを単精度(single-jacobi.f)に変更して、最適化レベルとスレッド並列数の変化で性能がどのように変わるか確認してみました。浮動小数点演算量は倍精度版と全く同じですが、メモリからプロセッサへのデータのロード・ストアの総量(バイト数)は、倍精度計算に較べ半分になります(これは、計算時間の減少にも繋がります。メモリのロード・ストアの時間は、かなり大きなウエイトを占めることが分かると思います)。外形的にみれば、メモリアクセスの負荷が小さくなったと言うことになります。倍精度計算の時と同じ視点で、各最適化のレベル並びに計算スレッド数を増加したときの並列効果の変化を見てください。各最適化レベル同士で見比べた場合、単精度版の計算の方が、並列の効果が良くなっていることが分かります。当然なことですが、これは実際のメモリ負荷が倍精度計算に較べて軽いと言うことを意味しています。-O1最適化の4スレッド並列計算では、3.68倍の理想的な並列効果を出しています。
コンパイラ最適化レベルとプロセッサ内部のSSEによるSIMD並列の利用
最適化オプションのレベルとプロセッサコア内部の演算量の関係をもう少し詳しく説明しましょう。プロセッサ内での演算器がうまく働けば、単位時間あたりの演算量が多くなります。その結果、実効性能も速くなります。演算量が多くなると言うことは、そのために必要なメモリからのデータ供給(あるいはストア)が増加すると言うことでもあります。すなわち、プロセッサ処理は存在するメモリの帯域を限界になるまで使おうとします。真に限界になった時点で、実効的な性能が向上しなくなります。この考え方を持って、プロセッサ自体が持つSSE(SIMD, ベクトル演算とも言う)並列演算の特性やマルチコアを利用したスレッド並列特性を見れば、メモリ帯域・性能の影響の度合いが理解できます。
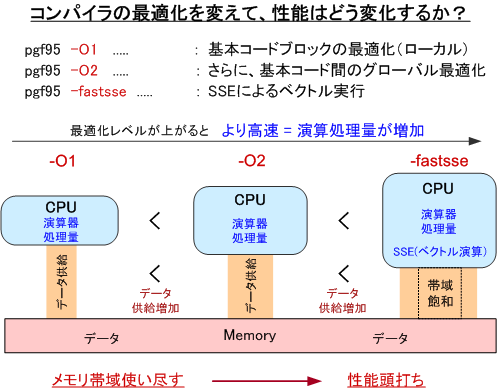
上記の表-1で性能効果を測定する際に用いた、プロセッサ内の演算器を効率的に動かす方法を説明しましょう。これは、単純に、コンパイラの「最適化のレベル」を変えることで、演算処理方法を最適化し、その結果CPU内の処理量が増加することで行います。PGIの場合、コンパイラの基本最適化方法の違いにより、最適化用のオプションは、-O0, -O1, -O2, -O3, -O4 まであります。一般的には、-O2 を使用します。さらに、現在のプロセッサは、SSEと言うハードウェア命令があります。この命令は、簡単に言えば、「複数の浮動小数点数演算を同時に実行する命令」です。昔からの言葉で言うと、演算に関してベクトル処理することができる命令です。また、今後の話に出てくる用語ですが、SIMD(Single Instruction Multiple Data) の処理形態であるとも言います。一つの CPU instruction(命令)で、複数のデータを演算処理することができるものです。現在のIntel(R)やAMDの x64 プロセッサは、単精度の場合は、4つの浮動小数点データを「一つのパック」として、一度に処理できます(現実的には無理ですが全てが理想的に動作した場合、4倍速くなります)。倍精度演算であれば、二つの浮動小数点データをパッキングして処理します。今後のインテルプロセッサでは、SSEの次の技術であるAVX(Advanced Vector Extensions)拡張命令を備えます。これは、SSEで実現しているベクトル処理の2倍の同時演算が可能な命令を提供します。なお、PGIコンパイラでも、AVX命令を使用したコードを作成できます。いわゆる、スカラ処理とベクトル処理(SIMD)の違いとそれに伴う処理時間の違いを模した図を以下に示しました。歴然として、ベクトル処理の方が速いことが分かると思います。もちろん、ベクトル処理には、それに伴うデータの供給が必要となります。データの供給が滞るとベクトル処理と言えども理想性能には届きません。
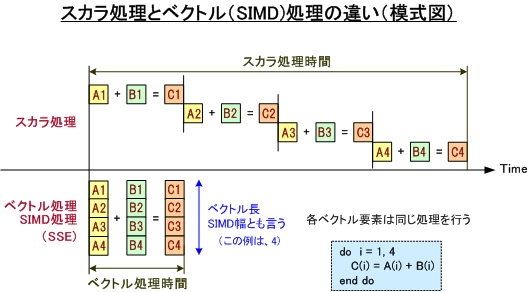
表-1 の中で、ベクトル(SSE)処理が行われる最適化モードは、-fastsse (これは -O2 最適化も含むオプション)です。この 1 スレッド計算時の性能値 (23.06秒)を -O2 の性能値(53.83秒)と較べて見てください。倍精度 SSE 命令ですので2つのデータを一度に処理するベクトル化(理想的に2倍速い)を行います。この実測データでは、約2.3倍の向上が見られますが、これは演算部の SSE 処理の最適化だけではなく、それに伴うデータのプリフェッチ処理等の様々な他の最適化も施されてなし得る複合的な性能向上と見ることができます。また、表-2の単精度計算では、同様に性能比率を求めると 11.86秒:34.70秒 で、単精度 SSE で2.9倍程度の向上が見られます。理論的な 4 倍にはなりませんが、SSEベクトル処理の効果が現れていることが分かります。
以下の例は、-fastsse オプションでコンパイルしたときのメッセージを表示しました。この中に、 Generated vector sse code と言うメッセージが SSE ベクトル化を行ったと言う意味になります。また、下記のメッセージでは、Generated 4 prefetch instructionsと言うメッセージがありますが、これは、ループ内で、演算前にメモリから必要とされるデータを先読み(プリフェッチ)しておき、そのデータに対する SSE ベクトル命令の処理パイプラインの流れを止めないようにするための最適化手法です。ここで、理解していただきたいことは、インテル(R)や AMD の x64 プロセッサ・コア内部の演算器には、SSEベクトル演算機構が備わっており、コンパイラがSIMD並列機構を使用できるようにコード生成していると言うことです。要は、知らず知らずのうちに、SIMD並列を使用して計算していると言うことですね。 (NIVIDIAのGPUの計算においても、SIMDと言う概念が必要になります)
【SSEベクトル化コード生成用のオプションとコンパイルメッセージ】
$ pgf95 -fastsse -Minfo -mp jacobi.f
jacobi:
195, Parallel region activated
198, Parallel loop activated with static block schedule
199, Memory copy idiom, loop replaced by call to __c_mcopy8
206, Barrier
207, Parallel loop activated with static block schedule
208, Generated 4 alternate loops for the loop
Generated vector sse code for the loop
Generated 4 prefetch instructions for the loop
218, Begin critical section
End critical section
Parallel region terminated
シミュレーション・プログラムにおける二つの並列性
一般的なシミュレーション・プログラムでは、3次元空間(あるいは2次元平面)を離散化する過程で、プログラムの構造が多重ループで構成されます。HPC Computing における並列化計算では、こうした「多重ループ・ブロック」が、コンパイラレベルで最も簡単に並列性を見出すことができる対象(昔はマイクロ並列化と称した。)とされてきました。この概念は現在でも同じです。一方、それより上位の並列性(マクロ並列性とかタスク並列性と言う。MPIによる並列化も含む)に対しては、ユーザ自身が並列化を施すためのコーディングを行うか、コンパイラに指示を与える必要があります。コンパイラの機能を使って並列化を行う場合は、前者の「多重ループ・ブロック」が対象となります。こう言ったブロックを「構造化ブロック(Structured block)」と言います。「構造化ブロック」を厳密に定義すると、Cプログラムであれ、Fortranプログラムであれ、複数の実行文の固まりを有し、そのブロックの始めの部分は、単一の入り口(single entry)であり、かつ、ブロックの終わりでは、単一の出口(single exit)である構造を持ったものとなります。プログラムのフローが、この構造化ブロックの途中から入り込んだり、あるいは、ブロックの途中で外に抜け出す(GOTO outside)ような構成は、「構造化ブロック」と定義されません。こうした複数の入り口や出口のあるブロックは、OpenMP並列でも、今後説明するディレクティブ指示の「PGIアクセラレータ・コンパイル機能」においても、並列化の対象とはなりませんのでご注意ください。
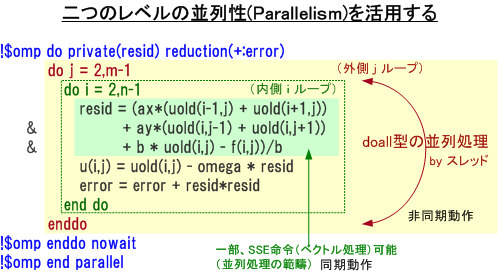
以下の図は、二重ループ構成の場合の二つの並列性が存在する例を示したものです。外側の j ループの単位で、複数のスレッドを利用した並列化(「doall型の並列」と言う。)が行うことができます。もちろん、これは配列データの添字間の依存性がない場合です。また、最内側の i ループの一部の処理では、従来からのベクトル化(SIMD)と言う方法で、同時に複数のデータ要素の演算処理が可能となっています。x64プロセッサの場合は、倍精度 SSE2 命令で同時に2つのデータ処理が可能です。ここで注意点は、後者の最内側のループに適用される SSEによるベクトル化はユーザの意識なく、コンパイラが自動的に行っている処理となっていることです。実は知らないうちに、最もプリミティブな並列演算処理を使用していると言うことになります。ここまでの整理として、一般的なプログラムの並列化には、多重ループを対象として、「二つの並列性」を見出す必要があると言うことを覚えておいてください。
マルチコア・プロセッサに備わる「並列実行手法」の整理とGPU特性との比較
現在のインテル(R)や AMD の x64 マルチコア・プロセッサは、以下の二つの並列機構を利用できると言うことになります。このことはGPU上での並列化の理解においても大事なことであり、実は、NVIDIA の GPU の並列演算機構もこの二つの典型的な「並列演算機構」、すなわち「ベクトル化(SIMD)」と「doall型の並列化」を利用していることを今後のコラムで説明します。ここで、二つの並列機構の動作特性に関して纏めておきます。GPUの場合についても対比のため纏めました。
インテル(R)や AMDのマルチコア・プロセッサは、以下の並列機構とメモリ帯域を使用することができます。

-
SIMD並列(ベクトル実行)による並列実行処理 (1プロセッサ)
プロセッサコア内部の演算器で実行。コンパイラがSSEベクトルコードを自動生成。ベクトル長は、固定で高々、2~4。
-
doall型の並列実行処理 (1プロセッサ)
コンパイラによる自動並列、OpenMP並列、明示的なPthread並列手法による並列スレッドで実装。但し、そのスレッド並列度は、高々、実マルチコア数(2010年時点で2~8)に制約される。
利用可能な実効メモリ帯域 5GB/sec ~35GB/sec (1プロセッサ)。ハードウェア制御のキャッシュ機構が介在する。
NVIDIA社の GPU の場合は、以下の並列機構とメモリ帯域を使用することができます。

-
SIMD並列(ベクトル実行)による並列実行処理
ユーザコード制御可能。PGI Accelerator Compiler ではディレクティブ指示が可能。ベクトル(SIMD)長は、Warpサイズ32、論理的には512まで可能。
-
doall型の並列実行処理
「グリッド」「ブロック」という概念でスレッド実行単位をユーザコードで指定。最大65535 x 65535 x 512 スレッド実行命令可能。
利用可能な実効メモリ帯域 160GB/sec (GTX-285)。メモリ種別の階層を利用し、ソフトウェアでキャッシュ管理を行う。
上記のように、x64 マルチコア・プロセッサの並列実行性とNVIDIA GPU の並列実行性の違いは、使用される並列実行実体(スレッド等)の数が大きく異なっていることが分かるでしょう。いわゆる並列分割処理可能となる数が絶対的にGPUの方が大きいと言うことです。また、それに伴い利用可能な実効メモリ帯域もGPUの方が大きな帯域を使用できるアーキテクチャとなっています。本コラムの前段で述べたように、いわゆる「足回り」となるメモリからのデータ供給能力が性能を決める要素ですので、GPUのアーキテクチャは、ある程度の、その必要条件を備えていることになります。もう一つ大事な点は、現時点ではハードウェア制御のキャッシュ機構を持たない GPU は、そのデータ・フローを考えたときにGPUメモリへのアクセス方法を単純化できます。その分、プログラムで使用するメモリ階層(シェアードメモリ等)をソフトウェアでうまく使うように制御する必要がありますが、メモリへのアクセスをユーザレベルで高速化することが可能です。x64プロセッサのように、ハードウェアがキャッシュを制御して、ユーザが細かなデータフローの制御ができない環境とは大きな違いです。(別の視点では、逆に現在の x64 プロセッサはハードウェアによるキャッシュ機構を有するため、人の手が介在しない意味で、そのメリットを享受できていると言うことも言えます。)
プログラムからNVIDIA GPUハードウェアを使うには、CUDA C(C言語)と言うプログラミング環境が用意されています。また、PGI は、PGI 2010 リリースから、NVIDIA GPU に対応する PGI CUDA Fortran と言う Fortran 言語環境を提供しました。これらの言語と CUDA が提供する API を用いてプログラムを組むと、細かなメモリアクセスの制御やメモリ階層の有効利用、スレッドの制御等のコーディングが可能となります。しかし、多くのユーザは、いきなり、こうしたプリミティブな言語体系を使うには、荷が重すぎると感じるに違いありません。一般ユーザの「プログラムの並列化は難しい」と言う言葉は、どの時代でも聞こえてきます。当然のことと思います。こうしたニーズに応えるため、PGI では、PGI Accelerator Programming Model と言うプログラミング仕様を策定し、スレッド並列化の世界で成功を収めた OpenMP のディレクティブ(プラグマ)方式と同じ方法で、GPUへ計算を処理させるためのバイナリを生成するコンパイラを提供しました。当然ながら、CUDA CやCUDA Fortran で直接プログラムするよりは性能は劣りますが、ディレクティブだけで重い計算部分をGPUに計算処理をオフロードすることが可能ですので、最初の移行ステップで使用してみる価値があります。次回以降では、このPGIアクセラレータコンパイラの使用法について説明していきます。