PGI CUDA FortranからCUDA CUFFT ライブラリを呼ぶ
 GPGPU、CUDA、FFT、CUDA Fortran、CUFFT
GPGPU、CUDA、FFT、CUDA Fortran、CUFFT
NVIDIA CUDA が提供している CUFFT ライブラリを CUDA Fortran から call 方法を説明します。ご自身のプログラムな中でFFT 計算を行っている部分を以下の例に倣って置き換えることにより、 GPU 上での FFT 計算を可能とします。
2011年6月13日 Copyright © 株式会社ソフテック 加藤
CUFFTを使用するためのラッパープログラム
CUDA Fortran 上で、NVIDIAが提供する CUDA CUFFT ライブラリを使用するには、CUFFT 関数を呼び出すための wrapper ルーチンを Fortran 2003 の iso_c_binding を用いて書くことが最も簡単な方法です。これは、CUBLAS の使用の場合と同じ方法です。PGI CUDA Fortran を用いた CUFFT を利用するためのサンプルプログラムは、PGI 11.0 以降の PGI Acceleratorコンパイラ製品の中に、cudaFortranSDK として提供されています。具体的には、Linux 版の場合は、$PGI/linux86(-64)/2011/cuda/cudaFortranSDK、Windows 版の場合には、C:\Program files\PGI\win64(win32)\2011\cuda\cudaFortranSDK 配下にインストールされています。この中のプログラムファイルを各自のホーム領域配下にコピーして使用して下さい。実装されている Makefile は Linux を想定したものですので、Windows環境では、Makefile の内容を変更する必要があります。これに関しては後述します。
以下の例は、cudaFortranSDK 内に付属しているプログラムとは異なり、理解しやすくするためにもっと簡単にしたものです。なお、CUFFT ライブラリは、PGI 11.5 リリース以降に PGI のソフトウェアの中に実装されたものを使用しているため、以下の Mekfile とソースファイルは、PGI 11.5 以降のリリースで使用できます。(以前のリビジョンには、CUFFT ライブラリが同梱されていません)
Fortran上で cufft 関数との interface を実現するラッパールーチンの作成
CUFFT は、変換に関する情報や一時的な配列エリアの情報等をストアしておくためのオブジェクト "plan" を使用します。Fortran言語では、この plan を整数として扱います。CUFFT 関数を使用するためには plan を初期化し、また、その使用を終了する際には、plan を destroy する必要があります。この plan の整数値は、CUFFT 関数の内部で適切な情報オブジェクトへ指し示すポインタとして使用されます。
次に、CUFFT はいくつかの定数を使用します。以下のような FFT変換方法の属性を指示する、CUFFT_FORWARD、CUFFT_INVERSE、CUFFT_*2* と言った定数です。特に、CUFFT_*2* は、当該変換の型を指示するものですが、CUFFT の場合は、これを 16進数で定義します。Fortran では、16進数は Z で始まる16進数定義を行います。
integer, parameter, public :: CUFFT_FORWARD = -1 integer, parameter, public :: CUFFT_INVERSE = 1 integer, parameter, public :: CUFFT_R2C = Z'2a' ! Real to Complex (interleaved) integer, parameter, public :: CUFFT_C2R = Z'2c' ! Complex (interleaved) to Real integer, parameter, public :: CUFFT_C2C = Z'29' ! Complex to Complex, interleaved integer, parameter, public :: CUFFT_D2Z = Z'6a' ! Double to Double-Complex integer, parameter, public :: CUFFT_Z2D = Z'6c' ! Double-Complex to Double integer, parameter, public :: CUFFT_Z2Z = Z'69' ! Double-Complex to Double-Complex
さて、次に準備することとして、C 言語用に提供されている CUFFT 関数を Fortran で使用できるようにインタフェースを構築します。これは、Fortran 2003 機能である、iso_c_binding 構文を利用して、そのインタフェースを定義します。このページでは、簡単に理解するために、1次元 FFT を実行する場合の例を説明します。
まず、当該実行を行う FFT の plan の生成とその dstroy関数のインタフェースを定義します。use文で iso_c_binding モジュールを呼び、C関数とのバインドを行う宣言を行います。NVIDIA の CUFFT 関数名 'cufftPlan1d' と Fortran 上での関数名は同じ名前で定義します。しかし、Fortran では大文字小文字の区別がないため、CUFFT(C言語)で定義されている関数名と忠実にインタフェースをとるために、明示的に bind(C,name='cufftPlan1d') と言った C 関数上での大文字小文字を区別した名前をシンボル名として定義します。後は、各関数の C 言語上での引数とタイアップするための変数の宣言を fortran の interface ブロックで行います。plan に関しては、C言語上でもポインタとして扱うために、integer(c_int):: plan のように定義し、他の整数引数は「値渡し」とするため、integer(c_int),value:: ... と言った形で定義します。このページでは、CUFFT の中の一部の関数の iso_c_binding interface の取り方を例示していますが、プログラム実行で必要となる cufft ルーチンの全てを同じような方法で定義しておく必要があります。
! -----------------
! cufftPlan1d ! cufftPlan[1|2|3}d 関数(Planの生成)へのインタフェース
! -----------------
interface cufftPlan1d
subroutine cufftPlan1d(plan, nx, type, batch) bind(C,name='cufftPlan1d')
use iso_c_binding
integer(c_int):: plan
integer(c_int),value:: nx, batch,type
end subroutine cufftPlan1d
end interface
! ------------
! cufftDestroy ! cufftDestroy 関数(Planの終了)へのインタフェース
! ------------
interface cufftDestroy
subroutine cufftDestroy(plan) bind(C,name='cufftDestroy')
use iso_c_binding
integer(c_int),value:: plan
end subroutine cufftDestroy
end interface
次に、FFTの実行ルーチンのインタフェースを定義します。CUFFTの cufftExec[C2C|R2C|C2R|Z2Z|Z2D|D2Z] 関数のインタフェースです。以下の例では、C2C と Z2Z 関数のインタフェースの MODULE 定義を記載しています。この記述の中で use precision_m と言う指定があります。この precision_m モジュールで、singlePrecision、doublePrecision 変数の kind 型が定義されており、このモジュール内の定義を変更することで単精度か倍精度の計算を行うか切り替えることができます。
! ----------------------------------
! cufftExec[C2C|R2C|C2R|Z2Z|Z2D|D2Z]
! ----------------------------------
! Complex to Complex(単精度版)
interface cufftExecC2C
subroutine cufftExecC2C(plan, idata, odata, direction) &
bind(C,name='cufftExecC2C')
use iso_c_binding
use precision_m
integer(c_int), value:: plan
complex(singlePrecision), device :: idata(*), odata(*)
integer(c_int), value:: direction
end subroutine cufftExecC2C
end interface
! Double-Complex to Double-Complex(倍精度版)
interface cufftExecZ2Z
subroutine cufftExecZ2Z(plan, idata, odata, direction) &
bind(C,name='cufftExecZ2Z')
use iso_c_binding
use precision_m
integer(c_int),value:: plan
complex(doublePrecision), device:: idata(*), odata(*)
integer(c_int),value:: direction
end subroutine cufftExecZ2Z
end interface
precision_m モジュールの定義は、以下のような定義を行っています。単精度宣言を行うか、倍精度宣言を行うかを決定するモジュールです。fp_kind と言う変数の浮動小数点の kind を予め定義しておくものです。もし、倍精度の FFT を行いたい場合は、fp_kind を kind(0.0d0) で定義する(以下のルーチンでは、doublePrecision パラメータにその定義をしてある)
! This module provides a simple facility for changing between single ! and double precision module precision_m integer, parameter, public :: singlePrecision = kind(0.0) ! Single precision integer, parameter, public :: doublePrecision = kind(0.0d0) ! Double precision ! Comment out one of the lines below (切り替え、ここでは fp_kind に倍精度を定義する) !integer, parameter, public :: fp_kind = singlePrecision integer, parameter, public :: fp_kind = doublePrecision end module precision_m
Fortran から cufft ルーチンを使用する(ドライバ)プログラム
CUDA Fortran で CUFFT ルーチンを使うためのプログラムは特別なことはなく、以下のように一般的にコーディングする形と同じです。GPU デバイス側で使用する配列を割付さえすれば、後は cufft 関数を call すれば良いだけです。以下の例は、1次元の cufft関数を使用する例です。プログラムの中に、簡単にコメントしてあります。
program cufftTest use precision_m use cufft_m implicit none ! precision_m module で定義された fp_kind の精度で宣言する ! a, b 配列はホスト側、a_d, b_d 配列は GPU デバイス側 complex(fp_kind), allocatable :: a(:),b(:) complex(fp_kind), device, allocatable :: a_d(:), b_d(:) integer i ! N=32 の FFT 計算 integer :: n=32 integer :: plan, planType ! allocate arrays on the host(配列割付) allocate(a(n), b(n)) ! allocate arrays on the device allocate(a_d(n), b_d(n)) !initialize arrays on host(初期値セット) do i = 1, n a(i) = cmplx(cos((i-1) * atan2(0.0,-1.0) / n), 0.0) end do !copy arrays to device (ホスト配列の内容をデバイス配列へコピー) a_d = a ! Print initial array print *, "Array A:" write (*,"(8('(',f6.3,',',f6.3,')',1x))") a ! set planType to either single or double precision ! This is a double precision. (ここでは倍精度のFFTを行う) PlanType = CUFFT_Z2Z ! initialize the plan and execute the FFTs.(CUFFTのplanの作成) call cufftPlan1D(plan,n,planType,1) ! 1次元 Forward FFT の実行, 結果を b_d 配列へ call cufftExecZ2Z(plan,a_d,b_d,CUFFT_FORWARD) ! Copy results back to host (b_d 配列の内容をホスト側 b 配列へコピー) b = b_d print *, "Forward B" write (*,"(8('(',f6.3,',',f6.3,')',1x))") b ! 1次元 Inverse FFT の実行, 結果を b_d 配列へ call cufftExecZ2Z(plan,b_d,b_d,CUFFT_INVERSE) ! Copy results back to host (b_d 配列の内容をホスト側 b 配列へコピー) b = b_d print *, "Inverse B" write (*,"(8('(',f6.3,',',f6.3,')',1x))") b ! Scale b_d 配列の内容は normalize されていないため、サンプル数で normalize b = b / n print *, "Scaled B" write (*,"(8('(',f6.3,',',f6.3,')',1x))") b !release memory on the host and device deallocate(a, b, a_d, b_d) ! Destroy the plan (CUFFTのplanの destroy ) call cufftDestroy(plan) end program cufftTest
以下に、Linux 上で動作する source ファイルと Makefile のアーカイブを置きました。
コンパイルと実行
PGI CUDA Fortran コンパイラを使用してコンパイルし、Linux 上ではライブラリ・リンクのための -lcufft オプションを付加して CUFFT ライブラリをリンクします。
● コンパイルとリンク
[kato@photon29 FFT]$ make
pgfortran -Mcuda=cc20 -fast -Minfo -c precision_m.cuf
pgfortran -Mcuda=cc20 -fast -Minfo -c cufft_m.cuf
pgfortran -Mcuda=3.2 -Mcuda=cc20 -fast -Minfo -o cufftTest cufftTest.cuf precision_m.o cufft_m.o -lcufft
cufftTest.cuf:
cuffttest:
21, Loop not vectorized: mixed data types
54, Generated vector sse code for the loop
Generated a prefetch instruction for the loop
● 実行
[kato@photon29 FFT]$ ./cufftTest
Array A:
( 1.000, 0.000) ( 0.995, 0.000) ( 0.981, 0.000) ( 0.957, 0.000) 紙面の都合で、右横部分省略
( 0.707, 0.000) ( 0.634, 0.000) ( 0.556, 0.000) ( 0.471, 0.000)
( 0.000, 0.000) (-0.098, 0.000) (-0.195, 0.000) (-0.290, 0.000)
(-0.707, 0.000) (-0.773, 0.000) (-0.831, 0.000) (-0.882, 0.000)
Forward B
( 1.000, 0.000) ( 1.000,******) ( 1.000,-5.367) ( 1.000,-3.394) *の表示は書式のカラム数が
( 1.000,-1.005) ( 1.000,-0.824) ( 1.000,-0.671) ( 1.000,-0.536) 足りないためです。
( 1.000, 0.000) ( 1.000, 0.099) ( 1.000, 0.199) ( 1.000, 0.304)
( 1.000, 1.005) ( 1.000, 1.226) ( 1.000, 1.508) ( 1.000, 1.891)
Inverse B
(32.000, 0.000) (31.846, 0.000) (31.385, 0.000) (30.622, 0.000)
(22.627, 0.000) (20.301, 0.000) (17.778, 0.000) (15.085, 0.000)
( 0.000, 0.000) (-3.137, 0.000) (-6.243, 0.000) (-9.289, 0.000)
(******, 0.000) (******, 0.000) (******, 0.000) (******, 0.000)
Scaled B
( 1.000, 0.000) ( 0.995, 0.000) ( 0.981, 0.000) ( 0.957, 0.000)
( 0.707, 0.000) ( 0.634, 0.000) ( 0.556, 0.000) ( 0.471, 0.000)
( 0.000, 0.000) (-0.098, 0.000) (-0.195, 0.000) (-0.290, 0.000)
(-0.707, 0.000) (-0.773, 0.000) (-0.831, 0.000) (-0.882, 0.000)
PGI Workstation for Windows 用のソースファイル(PGIコマンドプロンプト使用)
Windows上の PGI コマンドプロンプト上で使用する場合も、上記の Linux 上での場合と同じMakefile、ソースファイルを使用できますが、Makefile と Win32 上で使用する際のソースファイルに、一部変更する部分があります。
Windows 64bit 上での Makefile とソースファイル
Windows 64bit 上で bash 環境(PGIコマンドプロンプト環境)を使用する場合は、ほぼ Linux 上の Makefile と ソースファイルと同じものが使用できます。ただ、一点だけ、Makefile の「オブジェクトファイルの suffix 名」を *.obj と言う名前に変更する必要があります。Windows の世界では、慣用的にオブジェクトの suffix として obj が使用されています(Linux では、*.o となります)。これに関する説明は、過去のコラムでも説明しておりますのでご参照ください。以下の Makefile では、Linux Makefile で *.o としている部分を *.obj に変更しています。
以下に、PGI Workstation for Windows 64bit 上で動作する source ファイルと Makefile のアーカイブを置きました。
# All these examples can run with various pgfortran options. -fast is fine. F90FLAGS = -fast -Minfo # Uncomment the CUDAFLAGS line if you have hardware requirements that require # a specific compute capability CUDAFLAGS = -Mcuda=cc20 OBJS = cufftTest all: $(OBJS) # cufftTest # PGI only ships the cufft library beginning with cuda 3.2 cufftTest: cufftTest.cuf precision_m.obj cufft_m.obj pgfortran -Mcuda=3.2 $(CUDAFLAGS) $(F90FLAGS) -o $@ $^ -defaultlib:cufft cufft_m.obj: cufft_m.cuf precision_m.mod pgfortran $(CUDAFLAGS) $(F90FLAGS) -c $< # auxiliary modules precision_m.obj: precision_m.cuf pgfortran $(CUDAFLAGS) $(F90FLAGS) -c $< clean: rm -rf *.obj *.mod $(OBJS) *.dwf *.pdb *~
Windows 32bit 上での Makefile とソースファイル
Microsoft Windows の 32bit の世界では、プログラムのソースに変更すべき点があります。Win32 の環境で、メインプログラムとは別に提供される「CUFFTライブラリ」のルーチンを call するときに使用される「呼び出し規約」に関する点です。Win32 環境における「呼び出し規約(calling conventions)」は、様々なルールが存在します。これが曲者で、当該ライブラリを生成したときの呼び出し規約のルールが明確でないと使用する際に問題が出ます。なお、Win64 では、これは統一されておりますので、こうした問題が起きません。古いコンパイラの実装では、「呼び出し規約」に関して様々な種類が存在し、過去に作成したライブラリセットを異なるコンパイラ製品からリンクできないということもよく見られる現象です。これはさておき、NVIDIA 社の CUFFT では、stdcall と言う規約でライブラリを作成しています。この規約に従った CUFFT ルーチンの呼び出し記述を行わなければなりません。例えば、stdcall ルールにおいては、cufftPlan1dと言うルーチンの内部的なシンボル名は、cufftPlan1d@16 と言う形で作成されています。@16 の意味は、cufftPlan1d ルーチンの仮引数の長さ(バイト数)を表し、その総数として16バイト長を有するルーチンであるという意味となります。Win32上の NVIDIA CUFFT 提供の各ルーチンの内部シンボル名は、全てこういう形で実装されています。以下にその例を示します。iso_c_binding で CUFFT ルーチン名をバインディングする際にその指定を行います。なお、Makefile の中の オブジェクト名は、上記 Win64 の場合と同様 *.obj がデフォルトの suffix となります。
# interface cufftPlan1d
subroutine cufftPlan1d(plan, nx, type, batch) bind(C,name='cufftPlan1d@16')
use iso_c_binding
integer(c_int):: plan
integer(c_int),value:: nx, batch,type
end subroutine cufftPlan1d
end interface
以下に、PGI Workstation for Windows 32bit 上で動作する source ファイルと Makefile のアーカイブを置きました。
PGI Visual Fortran for Windows 用のソースファイル(Visual Studio 上の PGI Fortran使用)
PGI Visual Fortran で使用する場合も、上述した 各 Win64 用、あるいは Win32 用のソースファイルを使用できます。ここでは、Visual Studio 2010 で使用できる Visual Studio プロジェクトのサンプルをアーカイブしましたので、これを提供します。
PGI Visual Fortran 64bit for Visual Studio 2010 用のサンプルプロジェクト
PVF の以下のサンプルプロジェクトをダウンロードして展開します。なお、このプロジェクトは、PVF 11.5 で Visual Studio 2010 上で作成されたものであり、Visual Studio 2008 上では、ソースファイルだけをコピーし、以下に述べるプロパティの設定方法を参考に、ご自身でプロジェクトを作成して下さい。展開したフォルダーの 1 階層目に CUFFT64bit.sln ファイルをダブルクリックして起動して下さい。もし、これで Visual Studio を起動できない場合は、2階層目の CUFFT64bit.pvfproj ファイルをダブルクリックして起動して下さい。
以下に、Win64 用の Visual Studio 2010 用のサンプルプロジェクトのアーカイブを用意しました。
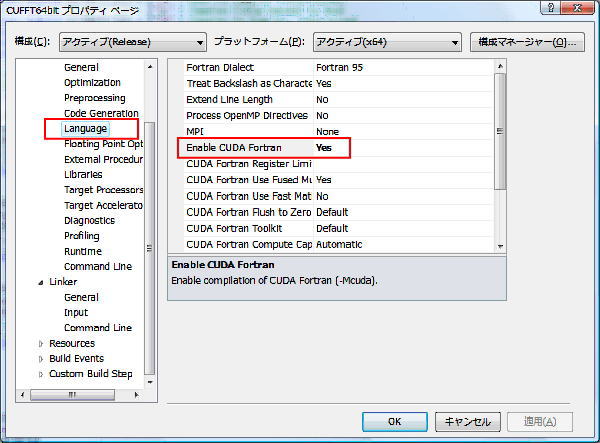
CUFFT ライブラリを使用する上で、Visual Studio 上で設定が必要な主な「ソリューション・プロパティ」の一例を以下に説明します。本プログラム・サンプルは、CUDA Fortran で記述されたプログラムですので、プロパティの Fortran ブロックの中の「Language」で「Enable CUDA Fortran」を Yes とします。ここで「適用ボタン」を押すと、CUDA Fortran の詳細設定のプロパティが現れます。ここはデフォルトの設定のままで構いません(あるいは、CUDA toolkit は 3.2 以上にします)。その他の Fortran 関係のプロパティはデフォルトのままで構いません。
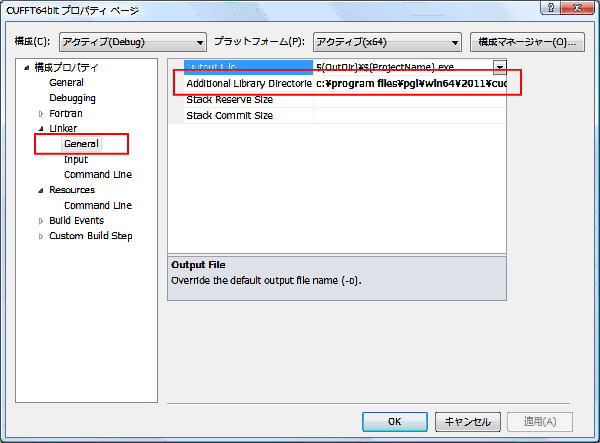
次に、「Linker」の設定を行います。PVF上では、CUFFTライブラリのPATH を設定しなければなりません。PGI 11.5 以降にバンドルされた CUFFT ライブラリを指定する場合は、そのライブラリが置かれている場所をフルパス名で下記のように指定します。Windows 64bit 上の x64プラットフォーム・ビルドの場合の一例は、C:\Program Files\PGI\win64\2011\cuda\3.2\lib64 の場所(この場所は、PGIのバージョンによっても異なりますので、必ずエクスプローラ等で実装フォルダを確認して下さい。)を指定します(PGIソフトウェアのインストール実装場所に依存します)。Windows 64bit 環境の中で、win32 プラットフォームのビルドの場合は、C:\Program Files (x86)\PGI\win64\2011\cuda\3.2\lib を指定します。なお、NVIDIA提供の CUDA Toolkit を別に実装している場合は、その cufft.lib の実装場所を指定しても構いません。
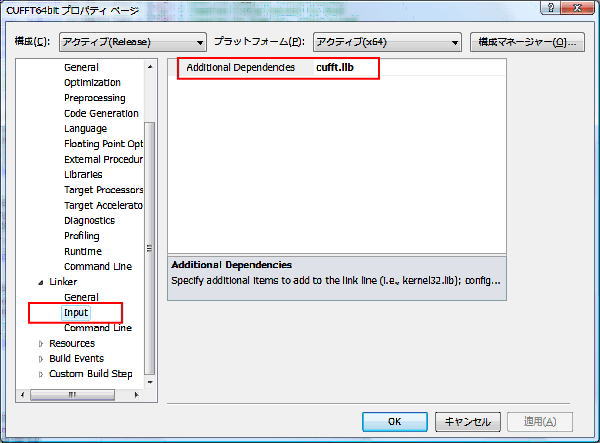
次に、「Linker-->input」の設定を行います。この中の「Additional Dependencies」に CUFFTライブラリのファイル名 cufft.lib を指定します。
PGI Visual Fortran 32bit for Visual Studio 2010 用のサンプルプロジェクト
以下の Windows 32bit 上の PVF 用サンプルプロジェクトの説明は、上記の Windows 64bit 上で説明した内容を踏襲します。64bit のプロジェクトと内容が変わっているのは、PVFプロジェクトの中の「Linker」プロパティ設定で cufft.lib のPATHのフォルダ名(一例:C:\Program Files\PGI\win64\2011\cuda\3.2\lib64)が異なっているところです。また、上記 Windows 32bit のところで説明した「呼び出し規約」に伴いソース変更がなされているところです。
以下に、Win32 用の Visual Studio 2010 用のサンプルプロジェクトのアーカイブを用意しました。