OpenACC ディレクティブによるプログラミング
3章 並列依存性とコンパイル・メッセージ
高速化のために並列処理を行う
現在のプラットフォーム環境で処理の高速化を行うための手段の一つは、並列処理である。すなわち、全体処理が終了するまでのスループットを改善するためには、プログラムの並列化を行うことが求められる。プログラムの並列化を手段とする高速化は、「アクセラレータ・プログラミングモデル」に限った話ではなく、マルチスレッドを使用した OpenMP や、マルチプロセスを使用した MPI 等の各プログラミングモデルにおいても同様な方法をとる。従って、プログラム内に並列化出来る部分がなければ、アクセラレータ上での高速化はできない。プログラムの並列化は必須事項となる。プログラム内で並列化を行う際のターゲットは、「ループ」である。シングルループよりも多重ループであれば、計算時間が多く掛かる部分(並列の粒度が大きいと表現する)が一つの並列化ターゲット(固まり)とすることができるため、効率の良い並列計算が可能と言うことになる。
並列化可能なループと並列化できないループ
並列化可能なループとは、ループ内処理の中で値の「定義」が行われる配列、変数の値が、並列処理した場合と逐次(シーケンシャル)に実行した結果と差異がないような形態を有するループを言う。並列処理では、複数の実行主体(スレッド)が存在するため、ループ計算の総量が分割(一般に「ループの長さ」を均等に分割する)され、各スレッドで分担して処理される。各スレッドは分割された「あるインデックス番号」から、受け持ちのインデックス数分を担当して個々に(並行に)処理する。このように並列処理においては、ループ増分インデックスが逐次処理のように始点から順番に増分し計算処理していく訳ではない。ループ内のインデックス(周回)がどのような順番で行われても「正しい結果」となるループ内処理が並列化可能と言うことになる。ここで言う「正しい結果」とは、「逐次」に実行した結果を意味する。別の表現方法を使うと、対象ループがその繰り返しを任意の順番で行った際にデータの依存性や制御依存性がない場合、並列化可能となる。また、同様にこうしたデータ依存性がないループは、ほとんどの場合、「ベクトル化も可能」であると言える。並列化を行わない場合は、コンパイラは明示的にベクトル化を行い SSE/AVX 命令を使用して高速なコードを生成する。それでは、「データ依存性」とはどのような状態を言うのか、概略を説明する。
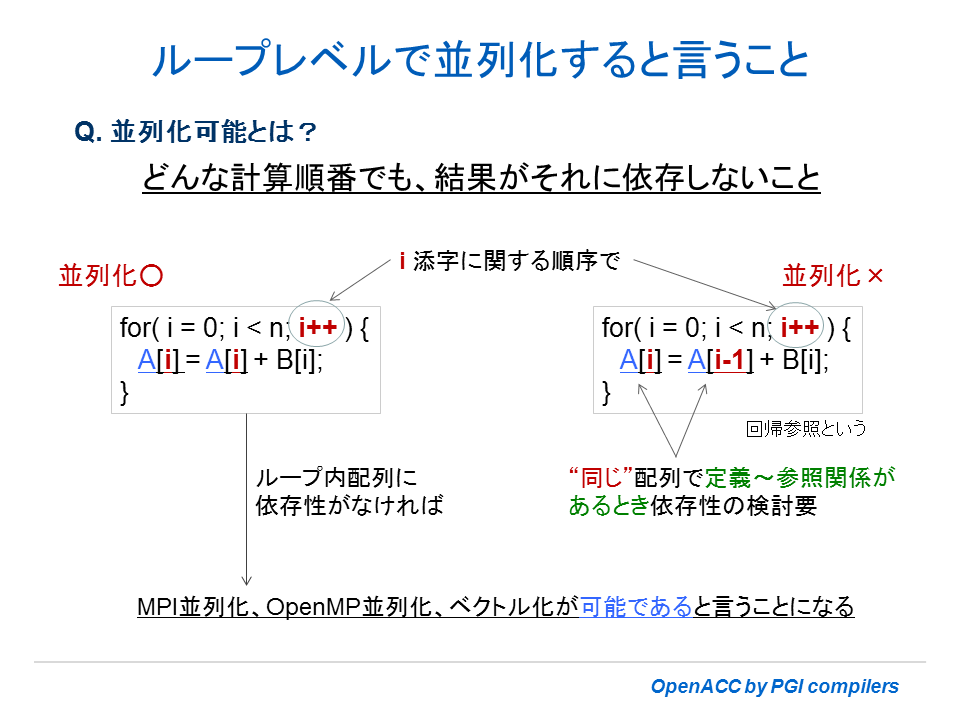
上図の右サイドに記したループ構成は i インデックスの繰り返しを行った際(インデックスの伝搬がなされた際)に「データ依存性」を有する。形としては、ループ内で配列 A[] が 2 個以上使用されて「定義-参照」の関係にある。以下に説明しているように、A[i]=A[i-1] の定義・参照関係があって複数のスレッドが並列実行した場合、A 配列の定義・参照のタイミングにおいて、loop carried dependency(ループ伝搬依存性)がある。「ループ伝搬依存性」を厳密に言い表すと、ループ実行において以前の周回の結果に依存して新たな周回の計算が行われる性質(依存状態)を言う。このため、こうした状態で任意の順番で周回実行を行う場合、並列化処理はできない。
逐次処理の場合と二つのスレッドで並列処理した場合の A 配列の定義-参照関係を以下に示す。
【逐次処理の場合】 || 【並列処理の場合】
逐次実行 (i=0,1,2,3,...) || 並列スレッド 1 (i=0,2,4,..)| 並列スレッド 2 (i=1,3,5,...)
|| |
(定義)=(参照) || |
A[0] = A[-1] || A[0] = A[-1] | A[1] = A[0]
A[1] = A[ 0] || A[2] = A[1] | A[3] = A[2]
A[2] = A[ 1] || ... ...
... || ※ 並列実行では、スレッド 1 の A[0] の定義と
... || スレッド 2 の A[0] 参照のタイミングが合う確証はない。
正しく処理される左サイドに描いた「逐次処理の場合」の A[0] の定義(ストア)~参照(レファレンス)関係を追って欲しい。A[0]の値をストアした後に、再度、参照されてこの値を A[1] にストアしていると言う順番である。この順番で参照と定義が繰り返されていくのが正しい結果である。一方、二つのスレッドが i ループ長を分割し、各々受け持つ。それぞれが独立に処理すると、スレッド 1 で行う A[0] のストアとスレッド 2 で行う A[0] の参照のタイミングが合わない可能性がある。同様に、スレッド 2 で A[1] の定義をした結果をスレッド 1 で参照するタイミングも同期されるわけではない。逐次処理のように、定義~参照の順番が保証されるわけではないからである。こうした状態を「データ依存性」が存在すると言う。その結果、並列実行した結果と逐次処理した正しい結果とが異なる。一方、データ依存性がない場合は、並列実行した結果と逐次処理した結果が数値的に一致する。
一般に、ループ内で「一つの配列が2個以上」使用されている場合、並列化における「データ依存性の存在」の可能性がある。ループ内で一つの配列が「参照-参照」の関係であれば依存性は全く存在しないが、「参照-定義」、「定義-定義」の関係であれば依存性の可能性が存在する。
ユーザにとっては、少なくとも依存性が存在する場合の定義~参照時の配列の添字関係の典型的なパターンを理解しておけば良いであろう。また、ループ構成が多重ループの場合は、使用する配列も多次元配列となっているのが一般的である。その場合は、並列化対象となるループ「次元」のインデックスに関して、当該配列の定義~参照時の添字関係を調べれば良い。
以上、ループ内における依存性の説明を行ったが、その他に「並列化可能とするための条件」があるので、以下にその概要を纏めておく。
- ループ内にデータ依存性がないこと(上述)
- ループ内の途中で、ループ外へジャンプすることを含めて、exit しないこと。すなわち、ループは「構造化ブロック」であること。構造化ブロックとは、Cプログラムであれ、Fortranプログラムであれ、複数の実行文の固まりを有し、そのブロックの始めの部分は、単一の入り口(single entry)であり、かつ、ブロックの終わりでは、単一の出口(single exit)である構造を持つものである。プログラムのフローが、この構造化ブロックの途中から入り込んだり、あるいは、ブロックの途中で外に抜け出す(GOTO outside)ような構成は、「構造化ブロック」とは定義されない。
- ファイル I/O (write文)がループ内にないこと
- ループ内に Procedure call がないこと。もし存在するのであれば予めインライン展開しておくこと(この制約は、OpenACC 2.0 規約に準拠する 2014 年 Q1 にリリースされるコンパイラバージョンで解消される)
データ依存性を調べる一つの方法
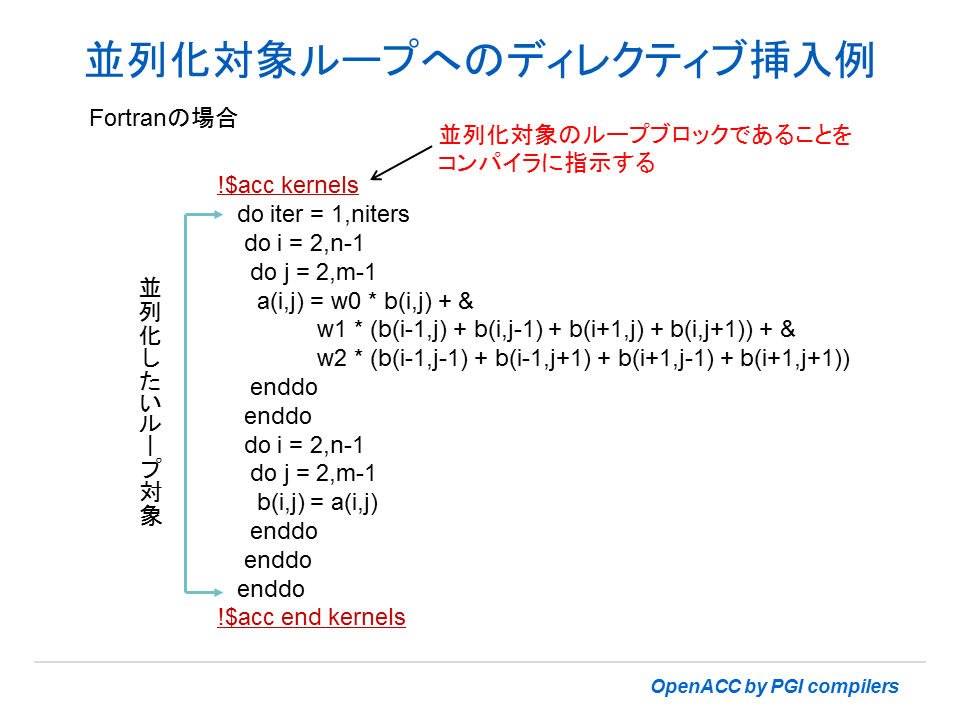
普通、ユーザは「データ依存性」を厳密に調べることは行わなくても良い。コンパイラがループ内の依存性の有無を判別する。OpenACC を適用してアクセラレータ上で並列実行を行うためには、少なくともプログラムの中に、明示的に OpenACC ディレクティブの挿入が必要となる。現段階ではディレクティブの細かな詳細を分からずとも、並列化対象となるループ・ブロックへの並列化指示のためのディレクティブである #pragma acc kernels (C/C++) あるいは、!$acc kernels ~ !$acc end kernels (Fortran) をだけ使って並列化が可能かどうかの確認を行ってみよう。以下に示した例のように、並列化対象となる(外側)ループ・ステートメントの前に、このディレクティブ行を挿入する。これは、コンパイラに対して、アクセラレータ上の並列化コードを生成するように指示するものである。これを受けてコンパイラは、当該ループの並列時のデータ依存性を調べて並列化が可能な場合に限り、並列化コードの生成を行う。並列化出来ない場合は、アクセラレータ用のスカラコードを生成する。これは非常に遅いコードのため、一般には並列化出来ない問題を排除するか、あるいは、OpenACC 化の対象としない対策が必要となる。また、コンパイル・オプション -Minfo=accel を指定してコンパイルを行うと、並列化の可否に関するコンパイル・メッセージも出力する。このメッセージを見て、対象となるループの並列化可否を判断することができる。
当該ループの並列化が可能でない場合、コンパイラはそのループの行番号と共に依存性がある旨のメッセージを出力する。もちろん、並列化が可能な場合もそのメッセージを出力する。このメッセージの例に関しては次の項で説明する。

-Minfo=accel オプションでコンパイル・メッセージを見る
以下の Cプログラムを例として、コンパイル・メッセージの表示方法とその意味を説明しよう。i と j の 2 重ループの中で、2次元の a 配列の「定義-参照」関係が存在する。そのデータ依存性があるかどうかを調べる。始めに、プログラム上で並列化対象と考えるループ構造に対して OpenACC のディレクティブ(赤字)を挿入する。次に、このソースファイルを c1.c として、コンパイルを行う。この際のコンパイル・オプションには、少なくとも -acc と -Minfo=accel(あるいは-Minfo) の二つを指定する。-acc は、OpenACC ディレクティブを認識してアクセラレータ用コードを生成することを指示するもの、-Minfo=accel は、コンパイル・メッセージを出力することを指示するものである。特にアクセラレータ関係のみを出力する場合は、-Minfo に =accel(アクセラレータ用メッセージ)を付加する。
typedef float *restrict *restrict MAT;
void
test( MAT a, MAT b, float w0, float w1, float w2, int n, int m )
{
int i, j;
#pragma acc kernels
{
for( i = 1; i < n-1; ++i ) // 行番号 34 ループ
for( j = 1; j < m-1; ++j ) // 行番号 35 ループ
a[i][j] = w0 * a[i][j] +
w1*(a[i-1][j] + a[i+1][j] + a[i][j-1] + a[i][j+1]);
}
}
$ pgcc -fastsse -acc -Minfo=accel c1.c
(一部のメッセージを抜粋)
34, Loop carried dependence of '*(*(a))' prevents parallelization (並列化不可)
Loop carried backward dependence of '*(*(a))' prevents vectorization
Accelerator scalar kernel generated(並列化出来ずにスカラコードを生成、これは遅いコード!)
35, Loop carried dependence of '*(*(a))' prevents parallelization (並列化不可)
Loop carried backward dependence of '*(*(a))' prevents vectorization(ベクトル化不可)コンパイル・コマンドを実行すると、その後にメッセージが現れる。これはコンパイラが行った最適化や並列化に関する説明を示したものである。最初にソース文の行番号を示し、その後、その最適化、並列化を実施した際の情報が記される。上記の例では、行番号 34 と 35 に関する情報を記している。行番号 34 は外側 i ループで、35 は内側の j ループに関しての並列化、ベクトル化の可否に関するメッセージが記録されている。
Loop carried dependence of '*(*(a))' prevents parallelization
このメッセージは、行番号 34 における外側 i ループ内の a[i][j] = ... a[i-1][j] + a[i+1][j] ... 式において、a[i]に関しての並列実行時のデータ依存性が存在することを伝えている。左辺 a[i] に対して、右辺の a[i-1] も a[i+1] のどちらも「ループ伝搬依存性」が存在する。左辺、右辺の i 添え字の関係に着目して欲しい。一方、行番号 35 でも j ループ内の j インデックスだけに着目し、依存性のチェックを行うと全く同様な構図が見られる。従って、これも並列時のデータ依存性が存在する。従って、このメッセージは当該ループが並列化出来ない場合に出力される。並列化するには、プログラムを変更してこうした依存性を排除する必要がある。
Loop carried backward dependence of '*(*(a))' prevents vectorization
さて、もう一つのメッセージ行として「ベクトル化できない」と言うメッセージも現れている。なぜ、並列化の議論の中にベクトル化の話が出てくるのかと疑問をお持ちの方もいるかと思う。実は、アクセラレータ・デバイスのアーキテクチャにも依存することではあるが、例えば、NVIDIA の GPU を想定した場合、この GPU システムは「ベクトル処理」と「並列処理」の両方を行うようにした構造となっている。warp と言う基本動作単位の中でベクトル(SIMD)処理を行い、この処理単位の固まりを並列処理すると言った構成となっている。従って、ループ内構造としてベクトル化可能なものは、さらに高速化手段の自由度が出てくると言うことになる。一つのループを「ベクトル化」して、かつ、「並列化」処理を行うと言うことは、こうしたデバイスでは一般的なことであり、インテルの Xeon Phi や AMD Radeon なども同じ構図と見て良い。
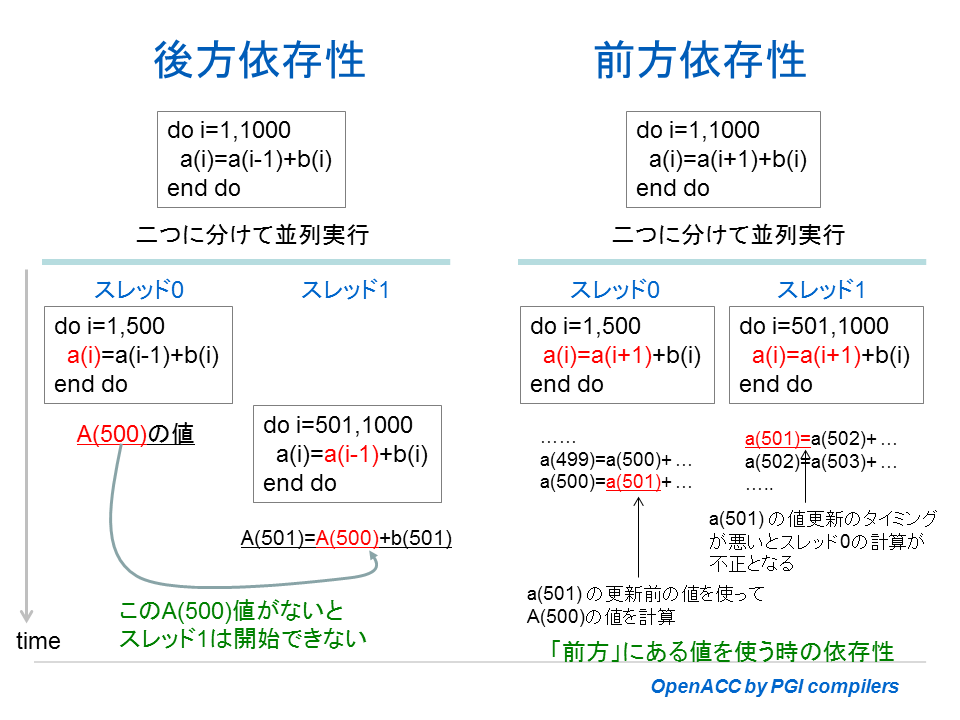
さて、上記のメッセージの中で「Loop carried backward dependence」と言う、日本語では「後方依存性」と言う言葉が出てきた。これは、今まで説明してきた a[i] = a[i-1] + b[i] と言った形での依存性を言うが、「後方」とは、一つ前の値がなければ、これを参照しているため計算できないと言う意味で、「前の値(後方)に依存する」と言うことである。一つ前の値がないと計算できないと言うことは、必ず「逐次処理」にならざるを得ないと言うことになる。「後方依存性」がある場合は、基本的にコンパイラは並列化もベクトル化も出来ないと言うことを覚えておく必要がある。
後方依存性と前方依存性、その他の依存性
ループ内の伝搬におけるデータ依存性について、もう少し説明する。この場合の依存性は、下図に示すように「後方依存性」と「前方依存性」の二つに大別される。「後方依存性」に関しては、前項で説明したとおり、ソースプログラムを抜本的に別のロジックに変更しない限り、並列化もベクトル化もできない。もう一つの「前方依存性」に関して説明しよう。左辺、右辺の配列添え字の形としては、Fortran で書くと a(i)=a(i+1)+b(i) と言った形態となる。下図に説明しているように、スレッド 0 と 1 の実行の順番によって、正しく計算の場合もあれば不正の場合もあり得る演算となる。こうした場合もやはり、依存性があるため、何も手を施さなければ並列化はできない。しかし、一時配列を活用してループの分割を行えば並列化が可能となる。「前方依存性」はソースの修正を行うことで並列化が可能となる。一方、「前方依存性」におけるベクトル化に関しては、コンパイラ自体がベクトル化出来るように内部的に最適化により変更できる場合がある。こうした場合は暗黙にベクトル化可能としてコード生成することができる。なお、英語では、「後方依存性」を flow dependency と言い、「前方依存性」を anti-dependency と言う言葉を使用している。
依存性の形として、もう一つ、「Output dependency」と言うものがある。これは以下のように、一つのループ・ブロックの中に、同一配列で添え字の異なる配列が二つ以上「定義」されている場合である。以下のような依存性を有するループをベクトル化あるいは並列化するための方法は、単に、一つのループ内の処理ではなく、二つのループ・ブロックに分けることによって依存性が排除できる。
// Output dependency
void out_dep(double A[], double B[], double C[])
{
for (int j=1; j<1024; j++) {
A[j] =B[j];
A[j+1]=C[j];
}
}
基本的には、データ依存性のある演算であるが、コンパイラレベルで、ベクトル化、あるいは並列化コードを生成する形もある。これは、一般に「リダクション(Reduction)」と呼ばれている演算形態である。線形計算においては、頻繁に出現する形式である。この形式は、ほとんどの場合、コンパイラが自動的に認識し並列化が行う。
! Reduction
sum=0.0
do i = 1, N
sum = sum + a(i)
end do
次に、以下の Fortran ループを見てみよう。このままの形だと並列化はできない。スカラ変数 d を一時変数として使用しているが、これは並列時の依存するデータとなる。この場合は、d をスカラ変数ではなく、配列 d(:) として配列に置き換えることで、各並列スレッド独立の配列要素(スレッド・プライベート)として使用できるので並列化が出来るようになる。
do i = 1, N
d = b(i) * 1.9
a(i) = d + c(i)
end do
(並列化する方法)
do i = 1, N
d(i) = b(i) * 1.9
a(i) = d(i) + c(i)
end do
前方依存性の回避例
データ依存性を回避することができれば、ベクトル化や並列化が可能となる。全ての依存性が回避出来るわけではないが、上記で述べた「前方依存性」を回避する例を示す。実行時のコストが増すが、一般にはスカラ実行時よりベクトル化あるいは並列化の性能効果の方が優位となるため、こうしたデータ依存性の排除を行う。
[Fortran] [C]
do i = 1, N-1 for (int i=1; i<1024; i++)
a(i) = a(i+1) + b(i) a[i] = a[i+1] + b[i];
end do
-------- 変更例 ---------- -------- 変更例 -------------
do i = 1, N-1 for (int i=1; i<1024; i++)
temp(i) = a(i+1) + b(i) temp[i] = a[i+1] + b[i];
end do
do i = 1, N-1 for (int i=1; i<1024; i++)
a(i) = temp(i) a[i] = temp[i];
end do
依存性が存在する Fortran プログラム例
以下のプログラムリストは、上記で述べたデータ依存性のパターンをコーディングしたものである。実際のプログラムは、より複雑な演算式となっているはずだが、その使用している配列の「定義~参照」関係が以下のような形態になっているものが一組でも存在する場合は、コンパイラはベクトル化も並列化も出来ない。行番号 13 と 20 の loop 1 と loop 2 は、後方依存性を有するループである。これは、ベクトル化も並列化も不可能である。行番号 27 と 44 の loop 3 と loop 4 は、前方依存性を有するループである。 プログラムを変更すれば、この依存性は回避出来る。この例を行番号 27 の loop 3-1 に示した。行番号 51 の loop 5 は、Output Dependency の例である。また、行番号 59 の loop 6 は、リダクションを含んだループの例である。こうしたループ対して、コンパイラのメッセージがどのような内容で出力されるかを見ていただきたい。 以下のソースプログラム deptest.f90 は、こちらから取得できる。なお、以下のような行番号入りの「リスティングファイル」を作成するためのオプションは、-Mlist をコンパイル時に付加する。これによって ****.lst ファイル 生成される。
Filename: deptest.f90 ( 1) program DepTest ( 2) implicit none ( 3) integer,parameter :: n=10000 ( 4) integer(4) :: i ( 5) real(8) :: a(n), b(n), c(n), tmp(n) ( 6) real(8) :: s ( 7) ( 8) ! Initialize ( 9) a(:) = 1.0d0 ( 10) b(:) = 2.0d0 ( 11) c(:) = 5.0d0 ( 12) ( 13) ! -- loop 1 -- Flow dependency ( 14) !$acc kernels ( 15) do i = 2, n ( 16) a(i) = a(i-1) + b(i) ( 17) end do ( 18) !$acc end kernels ( 19) ( 20) ! -- loop 2 -- Flow dependency ( 21) !$acc kernels ( 22) do i = 1, n-1 ( 23) a(i+1) = a(i) + b(i) ( 24) end do ( 25) !$acc end kernels ( 26) ( 27) ! -- loop 3 -- Anti-dependency ( 28) !$acc kernels ( 29) do i = 2, n ( 30) a(i-1) = a(i) + b(i) ( 31) end do ( 32) !$acc end kernels ( 33) ( 34) ! -- loop 3-1 -- Vecotorized/Parallelized ( 35) !$acc kernels ( 36) do i = 1, n ( 37) tmp(i) = a(i) + b(i) ( 38) end do ( 39) do i = 2, n ( 40) a(i-1) = tmp(i) ( 41) end do ( 42) !$acc end kernels ( 43) ( 44) ! -- loop 4 -- Anti-dependency ( 45) !$acc kernels ( 46) do i = 1, n-1 ( 47) a(i) = a(i+1) + b(i) ( 48) end do ( 49) !$acc end kernels ( 50) ( 51) ! -- loop 5 -- Output Dependency ( 52) !$acc kernels ( 53) do i = 1, n ( 54) a(i) = b(i) ( 55) a(i+2) = c(i) ( 56) end do ( 57) !$acc end kernels ( 58) ( 59) ! -- loop 6 -- Reduction ( 60) s=0.0 ( 61) !$acc kernels ( 62) do i = 1, n ( 63) a(i) = b(i) + c(i) ( 64) s = s + a(i) ( 65) end do ( 66) !$acc end kernels ( 67) ( 68) ! ( 69) print *, "a()=", a(n-1) ( 70) end program
-Minfo オプションでベクトル化、並列化の状態を読む
コンパイラオプションである -Minfo は、開発者にとって有益な情報をもたらす。プログラムのどこが「ベクトル化されたか」、「スレッド並列化されたか」、あるいは「他の最適化処理を行ったか」などの情報をプログラムの行番号と共に記してくれる。アクセラレータに関するコンパイル情報としては、データ配列のコピーに関する情報やアクセラレータ用に SIMD/並列化した際の情報等を知ることが出来る。このメッセージで、自分が思った形で並列化されているか等を確認することが出来る。
以下の例は、-Minfo=vec (CPU上のベクトル化情報のみを表示)を指定した際のメッセージ情報の例である。プログラムは、上述したdeptest.f90 を使用した。ベクトル化できたプログラム部分には「vector sse code を生成した」と言うメッセージを記す。一方、データ依存性でベクトル化出来ないものに関しても知らせてくれる。なお、この場合の最適化オプションは、ベクトル最適化を行うための -fastsse あるいは、-O2 のどちらかを併せて指定することが必要である。
$ pgfortran -fastsse -Minfo=vec deptest.f90
deptest:
9, Generated vector sse code for the loop
15, Loop not vectorized: data dependency
22, Loop not vectorized: data dependency
36, Generated vector sse code for the loop
46, Generated vector sse code for the loop
53, Loop not vectorized: data dependency
62, Generated vector sse code for the loop
以下の例は、-Minfo=par (CPU上における自動並列化情報のみを表示)を指定した際のメッセージ情報の例である。これは、CPU上のスレッド並列が可能なループをコンパイラが見いだした部分をメッセージとして出力する。並列化が可能なソース・ブロックを確認する場合に有益である。これを行うためには、-Minfo=par の他に自動並列化オプションの -Mconcur を指定することが必須である。確認のための用途であるため、ループ構造として一番内側のループ構造まで並列化対象としてチェックするようにコンパイラに指示する、-Mconcur=innermost のサブオプションを指定する(自動並列化では、デフォルトで最内側のループは並列化の対象としないため)。これによって、プログラムの全てのループを対象に並列化可能かどうか確認が出来る。このプログラムでは、行番号 9 と 36 のループが並列化可能なループとしてコンパイラは認識した。なお、コンパイラによる自動並列化では、例えば a() = b() と言った単純なデータコピーのループはあえて並列化は行わず、idiom パターンを使って高速な処理をおこなうため、並列化可能といったメッセージは出力しない。
$ pgfortran -fastsse -Minfo=par -Mconcur=innermost deptest.f90
deptest:
9, Parallel code generated with block distribution for inner loop
36, Parallel code generated with block distribution for inner loop
62, Loop not parallelized: may not be beneficial
以下の例は、-Minfo=accel (アクセラレータ用のコード生成情報のみを表示)を指定した際のメッセージ情報の例である。OpenACC プログラムをコンパイルする際には、必ず、このオプションを入れてコンパイルすることをお勧めする。その際には、OpenACC ディレクティブを認識するようにコンパイラに指示するために、-acc オプションも併せて指定する必要がある。ここでは詳細は説明しないが、ホストとデバイス間のデータ配列のコピーの状況を表すメッセージの他、アクセラレータ用に並列化を行ったことを示すメッセージも出力される。なお、以下のメッセージの中で、データ依存性で並列化出来ない部分は、15行目のループに対して「Accelerator scalar kernel generated」というメッセージを出力している。アクセラレータ内の「スカラコードを生成した」と言うことであるが、これは、並列化を行っていない非常に遅いコードであり、本来、OpenACC の対象とすべきループではないことを伝えている。OpenACC でコンパイルしたら、性能が逆に遅くなったと言った場合は、まずは、コンパイルメッセージから当該ループが「並列化」されているかどうかを確認する必要がある。
一方、「36, Loop is parallelizable」のメッセージは、36行目のループに対してアクセラレータ・デバイス用に並列化を行ったことを伝えている。さらに、「Accelerator kernel generated」とあり、NVIDIA のカーネルコードを生成したことを示している。「36, !$acc loop gang, vector(128) ! blockidx%x threadidx%x」は、並列化を行った際の並列マッピングの状況を説明している。36行目のループを gang 並列分割をし、128 SIMD 長でベクトル化を行ったと言う意味となる。
$ pgfortran -fastsse -Minfo=accel -acc deptest.f90
deptest:
14, Generating allocate(a(:))
Generating copyin(a(:9999))
Generating copyout(a(2:))
Generating present_or_copyin(b(2:))
Generating NVIDIA code
Generating compute capability 1.3 binary
Generating compute capability 2.0 binary
Generating compute capability 3.0 binary
15, Loop carried dependence of 'a' prevents parallelization
Loop carried backward dependence of 'a' prevents vectorization
Accelerator scalar kernel generated(並列化できなくて、スカラカーネルを生成した)
21, Generating allocate(a(:))
Generating copyin(a(:9999))
Generating copyout(a(2:))
Generating present_or_copyin(b(:9999))
Generating NVIDIA code
Generating compute capability 1.3 binary
Generating compute capability 2.0 binary
Generating compute capability 3.0 binary
22, Loop carried dependence of 'a' prevents parallelization
Loop carried backward dependence of 'a' prevents vectorization
Accelerator scalar kernel generated
28, Generating allocate(a(:))
Generating copyin(a(2:))
Generating copyout(a(:9999))
Generating present_or_copyin(b(2:))
Generating NVIDIA code
Generating compute capability 1.3 binary
Generating compute capability 2.0 binary
Generating compute capability 3.0 binary
29, Loop carried dependence of 'a' prevents parallelization
Loop carried backward dependence of 'a' prevents vectorization
Accelerator scalar kernel generated
35, Generating present_or_copyout(tmp(:))
Generating copyin(a(:))
Generating copyout(a(:9999))
Generating present_or_copyin(b(:))
Generating NVIDIA code
Generating compute capability 1.3 binary
Generating compute capability 2.0 binary
Generating compute capability 3.0 binary
36, Loop is parallelizable
Accelerator kernel generated
36, !$acc loop gang, vector(128) ! blockidx%x threadidx%x
39, Loop is parallelizable
Accelerator kernel generated (並列化して、GPUの並列構造にmappingした)
39, !$acc loop gang, vector(128) ! blockidx%x threadidx%x
45, Generating allocate(a(:))
Generating copyin(a(2:))
Generating copyout(a(:9999))
Generating present_or_copyin(b(:9999))
Generating NVIDIA code
Generating compute capability 1.3 binary
Generating compute capability 2.0 binary
Generating compute capability 3.0 binary
46, Loop carried dependence of 'a' prevents parallelization
Loop carried backward dependence of 'a' prevents vectorization
Accelerator scalar kernel generated
52, Generating present_or_copyin(c(:9998))
Generating present_or_copy(a(:))
Generating present_or_copyin(b(:9998))
Generating NVIDIA code
Generating compute capability 1.3 binary
Generating compute capability 2.0 binary
Generating compute capability 3.0 binary
53, Loop carried dependence of 'a' prevents parallelization
Loop carried backward dependence of 'a' prevents vectorization
Accelerator scalar kernel generated
61, Generating present_or_copyout(a(:))
Generating present_or_copyin(c(:))
Generating present_or_copyin(b(:))
Generating NVIDIA code
Generating compute capability 1.3 binary
Generating compute capability 2.0 binary
Generating compute capability 3.0 binary
62, Loop is parallelizable
Accelerator kernel generated
62, !$acc loop gang, vector(128) ! blockidx%x threadidx%x
64, Sum reduction generated for s (リダクションを並列化した)
Cプログラムでの restrict 修飾子
C 言語は ポインタを駆使してハンドリングする機会が多い。複数のポインタ変数を引数として関数へ渡すと、関数側ではこれら複数のポインタが示すそれぞれのオブジェクトが、メモリ上で全く異なる場所のものかをコンパイラは判断出来ない。コンパイラは、ポインタ変数が引数として渡された場合、同じメモリロケーションに存在する可能性があるとして、これらの変数を使うループに関してベクトル化や並列化の最適化を行わない。これがコンパイラのデフォルトの挙動である。一方、Fortran 言語は、関数の引数の管理は厳密に管理できるようにした言語体系のため、こうしたことはない。C 言語プログラムにおいては、C11 から restrict 修飾子が提供された。ポインタ変数の alias が存在しないと仮定し、コンパイラの最適化を許すものだ。ポインタ変数の alias の存在はプログラマが理解していることなので、こうした恐れがない場合は、必ずポインタ引数に restrict 修飾子を指定することをお勧めする。 restrict で修飾されたポインターが意図されたとおりに使用されるようにするのはプログラマの責任であるため、もし、誤った使い方をした場合でもコンパイラはそれを認識できないことに注意して欲しい。
以下に示す関数 test0 を見て欲しい。引数として *a と *b ポインタが指定されている。これをコンパイルすると、以下のようなメッセージが出力される。行番号32 のループにおいて、データ依存性(の可能性)があるため並列化を行っていない。「Accelerator scalar kernel generated」というスカラコードのみを生成している。
( 26) void
( 27) test0( float * a, float * b, int n )
( 28) {
( 29) int i;
( 30) #pragma acc kernels
( 31) {
( 32) for( i = 1; i < n; ++i ){
( 33) a[i] = b[i];
( 34) }
( 35) }
$ pgcc -acc -Minfo =accel c13-part.c
test0:
30, Generating present_or_copyout(a[1:n-1])
Generating present_or_copyin(b[1:n-1])
Generating NVIDIA code
32, Complex loop carried dependence of '*(b)' prevents parallelization 並列化不可能
Loop carried dependence of '*(a)' prevents parallelization
Loop carried backward dependence of '*(a)' prevents vectorization
Accelerator scalar kernel generatedコンパイラオプション -Msafeptr を付けてコンパイルすると、restrict 修飾子を指定しなくても、プログラムで使用されているポインタ変数に alias が存在していないことを明示的に指示してコンパイルすることが出来る。この場合は下記のようにコンパイラは並列化を行い、アクセラレータのカーネルコードを生成する。但し、-Msafeptr オプションはプログラム全体に波及する危険なオプションであり、プログラマがポインタの alias がないことを保証しない限り使うべきではない。
$ pgcc -acc -Minfo =accel c13-part.c -Msafeptr
test0:
30, Generating present_or_copyout(a[1:n-1])
Generating present_or_copyin(b[1:n-1])
Generating NVIDIA code
32, Loop is parallelizable
Accelerator kernel generated
32, #pragma acc loop gang, vector(128) /* blockIdx.x threadIdx.x */
さて、実際に restrict 修飾子を実際に付加してみよう。関数 test0 の引数に、*restrict a と指定を行うと alias が存在していないことを指示しているため、コンパイラは並列化を行う。ここでは、データの依存性に関わる「定義」を行っている配列 a にのみ、restrict 修飾を行っている。コンパイル・メッセージから「Accelerator kernel generated」によって、カーネルコードが生成されたことが分かる。
( 26) void
( 27) test0( float *restrict a, float * b, int* ndx, int n )
( 28) {
( 29) int i;
( 30) #pragma acc kernels
( 31) {
( 32) for( i = 1; i < n; ++i ){
( 33) a[i] = b[i];
( 34) }
( 35) }
$ pgcc -acc -Minfo =accel c13-part.c
test0:
30, Generating present_or_copyout(a[1:n-1])
Generating present_or_copyin(b[1:n-1])
Generating NVIDIA code
32, Loop is parallelizable 並列化可能
Accelerator kernel generated
32, #pragma acc loop gang, vector(128) /* blockIdx.x threadIdx.x */並列化を阻害する他の例
並列化を阻害するループ内の「配列添字に係わる依存性」に関しては上述した通りであるが、その他に、どのような場合に並列性を阻害するか、C プログラムを例にしていくつか取り上げてみる。
並列ループ内のスカラ変数が live-out の状態である場合
以下の test0、test1のルーチンのループは、いずれも並列化できない。ループ内で一時変数として使われている x と y は、逐次処理においては、ループ終了後、必ずループの終端の処理で定義された x, y の値となる。これがスカラ処理での正しい結果であるが、並列処理した場合は、ループが分割して順不同で実行されるため、x と y の値は、ループ・インデックスの終端における値であるとは限らない。そして、これらが並列領域の外で使用される変数値の場合、このループは並列化出来ない。こうした状況のことを live-out 変数が存在すると言う。別の言葉では、並列領域を出た後でも使用している(生きている)スカラ変数のことを言う。一般に、こうした live-out 変数は排除出来る場合が多いため、プログラムを変更して並列化を行うことができるものが多い。こうした状況の場合、以下のようなコンパイル・メッセージが出力される。live-out はよくあるパターンであるため、知っておく必要がある。
Accelerator restriction: scalar variable live-out from loop: x
( 26) float
( 27) test0( float *restrict a, float *restrict b, float *restrict c, float w, int n )
( 28) {
( 29) int i;
( 30) float x;
( 31) /* this region will fail to parallelize successfully,
( 32) * x is 'live' after the loop */
( 33) #pragma acc kernels
( 34) {
( 35) for( i = 0; i < n; ++i ){
( 36) x = b[i] * w;
( 37) if( x != 0 ) c[i] = x*a[i];
( 38) }
( 39) } // 並列化ループ内では、 x は単なる一時変数にも拘わらず、
( 40) if( x > 0 ){ // 並列化処理が終了した後に、x の値を使用している
( 41) return c[0];
( 42) }
( 43) return 1.0;
( 44) }
( 45)
( 46) float y; // y はグローバル変数であるため問題が起こる
( 47)
( 48) float
( 49) test1( float *restrict a, float *restrict b, float *restrict c, float w, int n )
( 50) {
( 51) int i;
( 52) /* this region will fail to parallelize successfully,
( 53) * y is 'live' after the loop, because 'y' is a global variable */
( 54) #pragma acc kernels
( 55) {
( 56) for( i = 0; i < n; ++i ){
( 57) y = b[i] * w;
( 58) if( y != 0 ) c[i] = y*a[i];
( 59) }
( 60) }
( 61) return 1.0; // 並列ループが終了した後、一時変数であった y はグローバル変数であるため
( 62) } // 使用される可能性がある(live-outの状態という)
( 63)
$ pgcc -o c10.exe c10.c -Minfo=accel -fast -acc
test0:
35, Scalar last value needed after loop for 'x' at line 40
Accelerator restriction: scalar variable live-out from loop: x 並列化不可能
Accelerator scalar kernel generated
test1:
56, Accelerator restriction: scalar variable live-out from loop: y 並列化不可能
Accelerator scalar kernel generated並列ループ内にスカラ変数の依存性がある場合
以下の test0、test1のルーチンは、ループ内に live-out の状態ではないスカラ変数 x があり、その値が条件文で変化しうる状態にある構造となっている。live-out の状態でないと言うことは、x は反復における一時変数として扱うことができ、コンパイラも並列化するために各反復でプライベートなコピーを作るが、それでいても x の値は逐次処理で実行する場合と同じ状況を作らなくてはならない。test0 と test1 はループ内の一文を除いて同じ内容であるが、test0 は完全に並列化可能であるが、test1 は、並列化が出来ない。詳細は、以下のソースの中にコメントしてあるが、test1 の場合のコンパイル・メッセージとして、以下の内容が出力される。ループ伝搬において x スカラ変数の依存性が発生していると言う内容である。この問題は、test1 のループの中の x の値は、条件文を満たさない場合は「不定」(逐次処理では前の反復で設定された x の値となる)になるため、並列処理で順不同で実行した場合、逐次処理の場合と異なることが想定されるため、並列化ができない。
51, Loop carried scalar dependence for 'x' at line 53
( 26) void
( 27) test0( float *restrict a, float *restrict b, float *restrict c, float w, int n )
( 28) {
( 29) int i;
( 30) float x;
( 31) /* this region will parallelize successfully */
( 32) #pragma acc kernels // 以下の場合は並列可能、但し、x は live-out の状態ではないことが条件
( 33) {
( 34) for( i = 0; i < n; ++i ){
( 35) x = 1.0; // x の値は常に反復毎に初期化される
( 36) if( a[i] < 0 ) x = b[i] * w; // 条件による x の変更があったとしても値が常に特定される
( 37) c[i] = x * a[i]; // 逐次処理の場合と同じ x の値となる
( 38) }
( 39) }
( 40) }
( 41)
( 42) void
( 43) test1( float *restrict a, float *restrict b, float *restrict c, float w, int n )
( 44) {
( 45) int i;
( 46) float x;
( 47) /* this region will fail to parallelize because 'x' is assigned
( 48) * conditionally, but used unconditionally */
( 49) #pragma acc kernels // 以下の場合は並列不可能、スカラ x の依存性に因る
( 50) {
( 51) for( i = 0; i < n; ++i ){
( 52) if( a[i] < 0 ) x = b[i] * w; // スカラ変数 x は条件付きで値が変化する
( 53) c[i] = x * a[i];
( 54) } // 並列に順不同で実行される場合、逐次処理の場合とは異なる x の値となる可能性あり
( 55) }
( 56) }
$ pgcc -o c7.exe c7.c -Minfo=accel -fast -acc
test0:
34, Loop is parallelizable 並列化可能
Accelerator kernel generated
34, #pragma acc loop gang, vector(128) /* blockIdx.x threadIdx.x */
test1:
51, Loop carried scalar dependence for 'x' at line 53 並列化不可能
Accelerator scalar kernel generatedループ内に「間接参照」の配列が存在する場合
以下のプログラムは、間接参照配列がループ内に存在する例を示したものである。ループ内で使用している配列 a, b 等には、いずれも *restrict 修飾子を付しており、配列要素のポインターの相互干渉はないものとして定義されている。a、b 共に、そのインデックスが間接参照形式であるが、*restrict修飾子で alias がないことを指示しているため、コンパイラはこれらのループを並列化しようとする。
test1 から説明しよう。test1 のループは、a 配列の「定義」があるため並列時の依存性を考慮しなければならない。問題は、a[ndx[i]] のインデックスは、間接的に ndx[i] から得られるため、並列時の増分インデックス i で変化するものではない。 ndx[i] の値によっては、当該値をストアする場所の干渉が起こりうる。従って、このループは本質的に並列化できない。
ところで、コンパイラがホストとアクセラレータ間のデータコピーのコードを生成するに当たって、a[ndx[i]]配列は間接参照であるため、a[] 配列の添字データ範囲がコンパイラには分からない。こうした場合、プログラマは明示的に #pragma acc data copy(a[0:n]) ディレクティブを使って a[] のデータ範囲を指示する必要がある。もし、このディレクティブを指定しない場合は、以下のようなメッセージを出し、警告する。
51, Accelerator restriction: size of the GPU copy of 'a' is unknown
データコピーに関する不明点について acc data ディレクティブを使って指示することにより、コンパイラはループの並列依存性解析を行う。 行番号 51 のループは、a[] 配列の定義(ストア)において、並列ループ・インデックス i で増分するのではなく、コンパイラが予測不能な ndx[i] の値をそのインデックスとして使用する。こう言った場合、コンパイラは並列化できず、以下のようなメッセージを出す。並列化するためには、a[] 配列を並列時の「プライベート」な配列、例えば aa[0:n] として一時保存し、何らかの対応しなければならない。あるいは、プログラマがこのループの並列依存性がないことを明示的にディレクティブ(#pragma acc kernels loop independent)で指示する方法をとる。
51, Parallelization would require privatization of array 'a[0:n]'
test3 の関数では、ループ内の演算式の右辺の参照側に間接参照する形式 b[rndx[i]] が置かれている。参照側に、間接参照型の配列があっても、並列化は常に可能であるためこのループは並列化できる。但し、b[] 配列の添字データ範囲がコンパイラには分からないため、 #pragma acc data copy(b[]) を使って b 配列の範囲を明示する必要がある。
( 41) void
( 42) test1( float *restrict a, float *restrict b, int *restrict ndx, int n )
( 43) {
( 44) int i;
( 45) /* Here, we've told the compiler how big 'a' is.
( 46) * Still, this region will fail to parallelize successfully,
( 47) * because of the index array on the left hand side */
( 48) #pragma acc data copy(a[0:n]) // 明示的にa[0:n]配列の添字範囲指定してデータコピーを指示
( 49) #pragma acc kernels // コンパイラは、a[]の大きさを把握できる
( 50) {
( 51) for( i = 1; i < n; ++i ){
( 52) a[ndx[i]] = b[i]; // a[]のindexの干渉が起こりうるとして、
( 53) } // コンパイラは並列化を行わない。
( 54) } // a[]が i のループと認識できないことも問題
( 55) }
( 71) void
( 72) test3( float *restrict a, float *restrict b, int *restrict rndx, int n )
( 73) {
( 74) int i;
( 75) /* Here, we've told the compiler how big 'b' is.
( 76) * Now if finally parallelizes */
( 77) #pragma acc data copyin(b[0:n]) // 明示的にb[0:n]配列の添字範囲指定してデータコピーを指示
( 78) #pragma acc kernels
( 79) {
( 80) for( i = 1; i < n; ++i ){
( 81) a[i] = b[rndx[i]]; // 間接参照 b[] 配列は「参照のみ」のため依存性なし
( 82) }
( 83) }
( 84) }
$ pgcc -o c13.exe c13.c -Minfo=accel -fast -acc
test1:
51, Parallelization would require privatization of array 'a[0:n]' 並列化不可能
Accelerator scalar kernel generated
test3:
80, Loop is parallelizable
Accelerator kernel generated
80, #pragma acc loop gang, vector(128) /* blockIdx.x threadIdx.x */ 並列化可能test1 ループにおいて、a[ndx[i]]の並列依存性がないことをが予め分かっている場合は、明示的に以下のように #pragma loop independent)節を指示すると、コンパイラは依存性解析を行わず並列化を行う。loop independent 節は、強制的に並列化を行うように指示するものであり、依存性の解析はユーザの責に負うこととなるので注意が必要である。
void
test1( float *restrict a, float *restrict b, int *restrict ndx, int n )
{
int i;
#pragma acc data copy(a[0:n])
#pragma acc kernels loop independent
{
for( i = 1; i < n; ++i ){
a[ndx[i]] = b[i];
}
}
}
$ pgcc -o c13.exe c13.c -Minfo=accel -fast -acc
test1:
51, Loop is parallelizable
Accelerator kernel generated
51, #pragma acc loop gang, vector(128) /* blockIdx.x threadIdx.x */配列添字が並列ループのインデックスと異なる場合
以下の test0 プログラムの2重ループは、外側に i ループ、内側に j ループという構造である。内側の j ループ内の演算で定義配列 a の添字が、j ではなく、i となっているため j ループ次元による並列化はできない。この場合は、外側のループのみ並列化可能であるが、内側ループが逐次処理となるため、性能の加速性はよくない。
( 26) void
( 27) test0( float *restrict a, float **restrict b, int n )
( 28) {
( 29) int i, j;
( 30) /* The inner loop will not parallelize because of the array
( 31) * a[i] on the left hand side, with no 'j' subscript */
( 32) #pragma acc kernels
( 33) {
( 34) for( i = 0; i < n; ++i ){ // iループは並列化可能、
( 35) a[i] = 0.0;
( 36) for( j = 0; j < n; ++j ){ // jループでありながら、
( 37) if( b[i][j] > 0.0 ) a[i] += b[i][j]; // 定義配列a[i]の添字がiとなっている
( 38) }
( 39) }
( 40) }
( 41) }
$ pgcc -o c14.exe c14.c -Minfo=accel -fast -acc
test0:
32, Generating present_or_copyin(b[0:n][0:n])
Generating present_or_copyout(a[0:n])
Generating NVIDIA code
Generating compute capability 1.0 binary
Generating compute capability 2.0 binary
Generating compute capability 3.0 binary
34, Loop is parallelizable (外側ループは並列処理可能)
Accelerator kernel generated
34, #pragma acc loop gang, vector(128) /* blockIdx.x threadIdx.x */
36, Complex loop carried dependence of '*(a)' prevents parallelization
Loop carried reuse of '*(a)' prevents parallelization
Inner sequential loop scheduled on accelerator (内側ループは遅い逐次処理)後方依存性のあるループの場合
1行のプログラム文の中で配列の後方依存性がある場合は一般に並列化はできないが、複数行の実行文の中で後方依存性がある場合は、並列化は出来なくともベクトル化がコンパイラ最適化によって可能となることがある。その例が test0 である。35行目のループは、ベクトル化のみ実施できたことを伝えている。しかし、アクセラレータの性能を享受するには並列実行することが必要なため、ベクトル化だけでは本来の性能を得ることができない。この問題を回避する方法として、ループを二つに分割して、a 配列の依存性を分断することにより並列化が可能となる。その例が test1 である。
( 26) void
( 27) test0( float *restrict a, float *restrict b, float *restrict c, float *restrict d, int n )
( 28) {
( 29) int i;
( 30) /* this region will fail to parallelize successfully,
( 31) * because there is a loop-carried dependence from the first
( 32) * assignment to a[i] to the use of a[i-1] in the next statement */
( 33) #pragma acc kernels
( 34) {
( 35) for( i = 1; i < n; ++i ){ // iループは並列化不可能
( 36) a[i] = b[i] + c[i]; // a[i]とa[i-1] の関係で後方依存性あり
( 37) d[i] = a[i-1] + 2*a[i];
( 38) }
( 39) }
( 40) }
( 41)
( 42) void
( 43) test1( float *restrict a, float *restrict b, float *restrict c, float *restrict d, int n )
( 44) {
( 45) int i;
( 46) /* this region does parallelize because the two loops turn into
( 47) * two kernels which execute in order */
( 48) #pragma acc kernels
( 49) {
( 50) for( i = 1; i < n; ++i ) // ループを二つに分割すると並列化可能となる
( 51) a[i] = b[i] + c[i];
( 52) for( i = 1; i < n; ++i )
( 53) d[i] = a[i-1] + 2*a[i];
( 54) }
( 55) }
$ pgcc -o c12.exe c12.c -Minfo=accel -fast -acc
test0:
35, Loop carried dependence of '*(a)' prevents parallelization 並列化不可能
Loop is vectorizable 最適化によるベクトル化は実施された
Accelerator kernel generated
35, #pragma acc loop vector(128) /* threadIdx.x */
test1:
50, Loop is parallelizable
Accelerator kernel generated 並列化可能
50, #pragma acc loop gang, vector(128) /* blockIdx.x threadIdx.x */
52, Loop is parallelizable
Accelerator kernel generated 並列化可能
52, #pragma acc loop gang, vector(128) /* blockIdx.x threadIdx.x */ループ自体を条件実行する場合
以下の例は、二重ループの内側ループが条件により実行制御されている場合の例である。test0 は、内側 j ループが、c[i] > 0 と言う条件判断で実行の有無が決まる。こうした構造の場合、外側 i ループは並列化出来るが、内側ループは条件依存のため、並列化できない。コンパイラメッセージによると、当該 j ループに関してはベクトル化だけが施されている。アクセラレータ上の並列化においては、出来るだけ並列実行の単位を増やすことが性能を向上させるコツである。従って、二重ループがある場合は、そのどちらのループも並列化可能となるようにするのがよい。こうしたことを踏まえて、test1 関数の場合は、条件文を内側ループ内に移動することにより、二つのループをそれぞれ並列化出来るようにしている。アクセラレータ用の並列化においては、このように出来るだけ並列実行単位を増やす工夫が必要となる。
( 26) void
( 27) test0( float **restrict a, float **restrict b, float *restrict c, int n )
( 28) {
( 29) int i, j;
( 30) /* this region will parallelize the outer 'i' loop, but not the 'j' loop
( 31) * because of the conditional around the loop */
( 32) #pragma acc kernels
( 33) {
( 34) for( i = 0; i < n; ++i ) // このiループのみ並列化可能
( 35) if( c[i] > 0 )
( 36) for( j = 0; j < n; ++j ) // 上記の条件で変化するため、並列化できず
( 37) a[i][j] += b[i][j] * c[i]; // ベクトル化のみ実施できる
( 38) }
( 39) }
( 40)
( 41) void
( 42) test1( float **restrict a, float **restrict b, float *restrict c, int n )
( 43) {
( 44) int i, j;
( 45) /* this region will parallelize both loops, because the conditional
( 46) * is inside the kernel loop */
( 47) #pragma acc kernels
( 48) {
( 49) for( i = 0; i < n; ++i )
( 50) for( j = 0; j < n; ++j )
( 51) if( c[i] > 0 ) // 条件を内側ループ内に移動すると、i と j ループが並列化可能
( 52) a[i][j] += b[i][j] * c[i];
( 53) }
( 54) }
$ pgcc -o c16.exe c16.c -Minfo=accel -fast -acc
test0:
34, Loop is parallelizable 34行の i ループのみ並列化可能
Accelerator kernel generated
34, #pragma acc loop gang /* blockIdx.x */
36, #pragma acc loop vector(128) /* threadIdx.x */
Loop is parallelizable
test1:
49, Loop is parallelizable 二つのループが並列化可能
50, Loop is parallelizable
Accelerator kernel generated
49, #pragma acc loop gang /* blockIdx.y */
50, #pragma acc loop gang, vector(128) /* blockIdx.x threadIdx.x */[Reference]
- Michael Wolfe,The Portland Group, Inc., The PGI Accelerator Programming Model on NVIDIA GPUs
Part 2 Performance Tuning