NVIDIA GPU の構造と CUDA スレッディングモデル
PGIコンパイラによる GPU Computing シリーズ (4)
NVIDIA社の GPU 上で演算可能とするコードを生成するPGI アクセラレータコンパイラや PGI CUDA Fortran を使って、実際のプログラムを GPU 上で計算させる方法を説明する前に、やはり NVIDIA GPU と CUDA スレッディングについて説明した方が良いだろうと言うことで、このコラムを急きょ追加しました。実は、GPU 上での性能は、チューニングのためのパラメータを変えると大きく性能が向上したり、あるいは遅くなったりすることが普通です。性能に関わってくる CUDA の技術的な事柄やスレッドの概念等を何も分からず、がむしゃらにチューニングしてみると言うのも、やはりいただけないと思い、GPU と CUDA の中身を分解して説明することにしました。ここでは、NVIDIA の GPU の構造をハードウェア的な観点で説明してから、CUDAソフトウェア環境の技術的な事柄にマッチングさせ、GPUが高速演算できる理由を理解してもらいます。この理解が今後、最適化を行うための基礎知識となります。
2010年6月16日 Copyright © 株式会社ソフテック 加藤
NVIDIA GPU の構造と CUDA スレッディングモデル
GPUを利用して一般的な並列プログラミングを行う手法は、HPC(High Performance Computing) の現場で、最近よく見られる現象です。GPU は本来、画像(グラフィックス)系の最適化処理のためのハードウェアでした。最近は、GPU を直接プログラミングで操作できるようになったことにより、画像の最適化処理だけではなく、一般の計算用途に活用する道が開けました。こうした計算用途にタスクを生成しスレッド実行できる環境を単純化するためのプログラミング言語として、NVIDIA 社は 2006年後半に CUDA アーキテクチャを提唱し、そのツール群を提供しました。CUDAの目的は、直接、GPU上で「データ並列」型の計算を行なえるようにすることです。「データ並列」型とは、単純に言えば、多くの演算器で異なるデータ要素の計算を同時に行うと言うことです。GPU上では多くの「演算器(スレッドプロセッサ)」が搭載されていますので、その上で「データ並列」型の並列化を実現することは理に適っていますし、実際のシミュレーション・プログラムもそうした特性を有しているものが多いです。このようなモデルを、ここでは「CUDAデータ並列・スレッディングモデル」と称することにします。
PGIのユーザは、こうしたCUDAデータ並列モデルと NVIDIA GPU の動作アーキテクチャに関する知識があれば、PGIアクセラレータ・プログラミングモデルでGPU並列化を行うにせよ、CUDA Fortran で直接、CUDA kernel を記述するにせよ、プログラムチューニングする際の助けになることと思います。コンパイラ・ディレクティブで GPU 並列化を行う「PGIアクセラレータ・プログラミングモデル」では、コンパイル時のフィードバック・メッセージを出すオプション -Minfo を付すると、様々な GPU 用コンパイル時の情報が出力できます。例えば、ループをパラレル・モードで実行するのか、SIMD(ベクトル)モードで実行するのか等の情報を得ることでき、GPU性能チューニング方法の一つであるループ・スケジューリングに関するヒントが得られます。こう言ったことを理解するには、GPU の構造と CUDA モデルに関する多少の知識が必要です。ここでは、NVIDIA の GPU の構造をハードウェア的な観点で説明してから、CUDAソフトウェア環境の技術的な事柄にマッチングさせ、GPUが高速演算できる理由を理解してもらいます。この理解が今後、最適化を行うための基礎知識となります。もし、ハードウェアに関しては難しいという方は読み飛ばしても良いですが、いずれ性能最適化を行う際に、CUDA スレッディングモデルの知識が必要となりますので、その際にお読みいただければ幸いです。
NVIDIA GPU のハードウェア・スペック
NVIDIA GPU の説明の前に、その主たるハードウェア・スペックを以下の表-1に纏めました。以下の説明の中で、これらのスペック値は参照されます。
| ハードウェア仕様 | Tesla (GT200) | Fermi (GF100) | |
|---|---|---|---|
| Compute Capability | Compute Capability | 1.3 | 2.0 |
| 総CUDAコア(SP)数 | CUDA cores (Streaming Processors) |
240 cores | 512 cores |
| 単精度浮動小数点演算 | Single Precision F.P.O. | 240 MAD/clock | 512 FMA/clock |
| 倍精度浮動小数点演算 | Double Precision F.P.O. | 30 FMA/clock | 256 FMA/clock |
| Streaming Multiprocessor(SM) | 30 SMs | 16 SMs | |
| CUDAコア数(SP)/SM | CUDA core/SM | 8 cores | 16 cores x 2 group |
| 特殊関数UNIT/SM | Special Function Unit/SM | 2 units | 4 units |
| WARPスケジューラ/SM | WARP scheduler/SM | 1 units | 2 units |
| 共有メモリ/SM | Shared Memory/SM | 16 KB | 16 KB or 48KBの選択 |
| L1キャッシュ/SM | L1 cache/SM | × | 48 KB or 16KBの選択 |
| L2キャッシュ/SM | L2 cache/SM | × | 768KB |
| ECCメモリ機能 | ECC memory | × | Yes |
| メモリインタフェース | Memory Interface | 512 bits | 386 bits |
| メモリテクノロジ | Memory technology | DDR3 | DDR5 |
| Load/Store アドレス幅 | Load/Store address width | 32 bit | 64 bit |
| メモリバンド幅 | memory Band Width | 159GB/s (GTX285) | 177GB/s (GTX480) |
※GPGPUの浮動小数点演算性能仕様については、こちらのページを参照
積和演算器 MADとFMA について
- MAD(Multiply-Add):1命令で、積和演算を行う。最初の「積」の段階で切り捨てを行い、その後「和」の処理の各段階で丸め処理を行う。
- FAD(Fused Multiply-Add):1命令で、積和演算を行う。「積・和」の最終段階で丸め処理をするため MAD より高精度。
NVIDIA GPU のアーキテクチャ(構造)を理解しよう
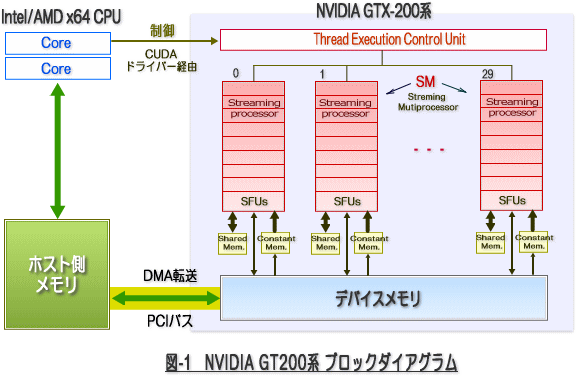
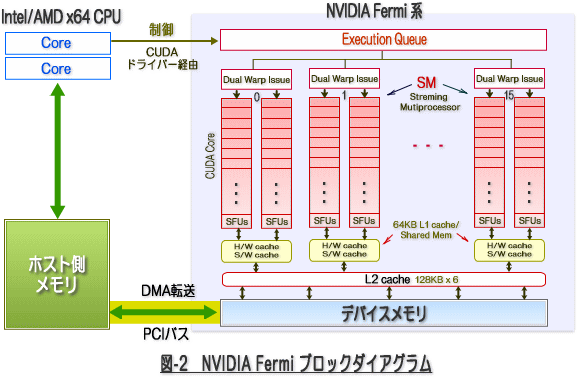
まず、始めに NVIDIA GPU の構造をブロックダイアグラムで見てみましょう。細かな意味は分からなくとも、大まかなデータの流れと演算器(Streaming Processor or CUDA core) の多さを実感して下さい。以下の図は、GT200系(Tesla C1000シリーズ、GTX 285等)のアーキテクチャと 2010年リリースした Fermi アーキテクチャ(GF100系)を示したものです。これらのアーキテクチャには多少の違いはありますが、大きな構造は同じです。
- ホスト側とGPUボードは PCI バスを通してデータの交換を行います。
- GPU内に転送速度は非常に速いが、メモリ・アクセスの遅延(レイテンシ)の大きな「デバイスメモリ」を有します。現在の実装では、数 GB オーダーの容量を有します。
- デバイスメモリとGPUの演算装置(「Streaming Multiprocessor (SM)」と言う。あるいは単に Multiprocessor と言うこともある。)の間に、ソフトウェアで管理できるキャッシュ(Shared Memory)とハードウェアで制御できる L1/L2キャッシュ(Fermi以降)が存在する。
- Streaming Multiprocessor (SM) は、演算器の集まり(クラスタ)であり、この演算器の最小単位は、Streaming Processor(SP)、あるいは CUDA coreと称される。一つの SM の中に 8個の SP (GT200系)、あるいは 32個の CUDA core(Fermi系)を有している。これを基本セットとし、GT200系は 30個の SM を有し、Fermi系では最大16個の SM を有する。
- 一つの SM には、それ自体に命令ユニット、演算器(実行ユニット)、レジスタ、キャッシュが含まれるため、従来の CPU 的な観点で見れば、SM自体は「プロセッサ・コア」と見立てることもできる。ただ、命令発行等の仕組みを含めて動作形態は大きく異なる。
ホスト側メモリからGPUのデバイスメモリまで
GPU は、一般に PC のハイスピードI/Oバスのスロット(PCI-Express 2.0x16=10GB/sec)に装着して、ホスト(PC)側と接続されます。この PCI バスを経由した転送バンド幅の仕様値は、高々 10GB/sec オーダーであり、GPUの性能仕様に対してのデータ供給能力としては、極めて低いものと認識して下さい。また、GPU は、ホスト側からのデータを保持し、GPU内で利用するために、それ自身のデバイスメモリを有しており、現時点の構成では数 GByte 程度実装されています。即ち、GPUで処理するためには、必ず、ホスト側とデバイスメモリの間で、データのコピーあるいはその戻しが発生します。このコストは、非常に大きなものですので、GPUにオフロードしたい「ループブロック(kernel program)」の中で、ホストからデータ転送が頻繁に起こりうるようなロジックを有する場合は、GPUを使った加速性能を得る以前の問題と言うことになります。すなわち、GPUで演算する時間よりもデータの転送時間が遙かに大きいという事態になります。
ホスト側メモリとGPU間のデータ転送は、DMA (Direct Memory Access)という方法で行われます。この DMA では、ホスト側メモリとGPU間の双方向の転送が同時に可能となります。また、ある制約条件はあるものの、GPU からホスト側のメモリを直接アクセスすることもできます。DMAは、ホスト側の「連続したアドレスのデータ領域」を連続的にデータ転送する場合はオーバーヘッドが少ないですが、例えば、メモリのアドレスのストライドを有したデータ転送の繰り返しは大きなオーバーヘッドを有します。ユーザの視点から言えば、一つの大きなマトリックスデータの中で、必要なサブマトリックスデータ部分だけ小刻みに転送するよりも、大きなマトリックスデータ全体を一気にGPU側へ転送した方が速いと言うことを覚えておけば良いと思います。(PGI Accelerator プログラミングモデルでは、Host-GPU間データ転送の directive がありますので、この考え方を参考に、転送量の調整を行うことが必要です)
PGI Accelerator プログラミングモデルの場合のデータ転送 directive の例(全てのデータ転送) !$acc data region & !$acc copyin(a(1:mimax,1:mjmax,1:mkmax,1:4)) & !$acc copy (p(1:mimax,1:mjmax,1:mkmax)) .... 配列の一部をデータ転送する場合の指定(上記よりも遅い転送となる可能性あり) !$acc data region & !$acc copyin(a(2:mimax-1,2:mjmax-1,2:mkmax-1,1:4)) & !$acc copy (p(2:mimax,2:mjmax,2:mkmax)) ....
GPUのデバイスメモリと演算器(CUDA core)の間
次に GPU 内部の構造を順番に説明しましょう。最初に、GPU内部の「デバイスメモリ」と「演算用の Core プロセッサ」間についてです。メモリの転送能力は、HPC アプリケーションの性能を決める重要な指標ですが、その「メモリバンド(帯域)幅」は、一般的なIntel®/AMD等の x64 系のプロセッサが有するものに較べても、6~7倍程度高い性能を有します(ご参考:NVIDIA GPUの実効メモリ帯域)。具体的には、Teslaアーキテクチャ(GT200)である GTX285 のボードでは 159 GB/sec のメモリ帯域を有し、Fermi では、最大 177 GB/sec のメモリ帯域を持っています。とは言え、今までのプロセッサ技術の常識から見れば、この帯域は確かに高い性能ではありますが、GPU 内に備えている240~512個の演算器(Streaming Processor あるいはCUDAコア)がなし得る総演算能力(単精度で 700~1400 GFLOPSオーダー)に対するデータ供給能力としては未だに非弱です。これ以上に大きなボトルネック、すなわち、もう一つの性能支配要素があります。これは、メモリアクセスの「レイテンシ」と言われるもので、実際の演算コアまでデータを供給するまでの初動オーバーヘッドです。実は、この値は通常 400~600cycle 位長いものです。GPU 内部の WARP と言う演算単位が 2~4 cycle の単位で実行を行うレベルから見たら、非常に大きなオーバーヘッドと言えましょう。GPUの本領は、演算能力に対してバランスを欠いたメモリアクセスの遅さ(データ供給の遅延)を隠蔽する方法を提供していることです。遅いデータ転送の合間に、演算の準備が整っている実行スレッド・グループ(Warpと言う)を順不同で同時にできるだけ多く稼働させると言うメカニズム(マルチスレッディングによるConcurrency) によって、データ転送と実行の「オーバーラップ」を実現させ、結果的にメモリ転送遅延を隠蔽させているのです。このメカニズムを効果的に発揮させるために、次項で述べるメモリキャッシュ利用や非常に大量に実装しているレジスタの数があります。
さて、ユーザが起こしうるメモリの転送性能を劇的に落とす場面を説明しておきましょう。再度、メモリのハードウェア仕様を説明します。NVIDIA GT200系の場合、物理的に 512ビット幅のデータパスを有し、16個の連続した 32-bit words を 1 サイクルで転送する能力があります。Fermi の場合は、6個の連続した 64-bit words を 1 サイクルで転送する能力があります。この転送パターンを毎サイクル実行できれば、上述のメモリ帯域を実現できますが、もし、メモリ・アクセスが「ストライド」を有した場合、連続アクセス性が失われるため、そのメモリ転送性能は劇的に低下します。GPU上の性能を落とす要因の一つは、GPU上で処理するループ内のデータアクセスが、stride-1 以外のパターンであるとことを覚えておいて下さい。(プログラムのロジックは、stride-1 でアクセスできるように組むことが必要です)なお、こうしたメモリのアクセス性能を左右する「コアレッシング・アクセス」と称する重要な概念がありますが、ここでは省略します。
PGI Accelerator プログラミングモデルの場合のコンパイルメッセージ(-Minfo=accel) の例
32, Non-stride-1 accesses for array 'a'
(解説)
"Stride-1" のアクセスとは、アクセスの順番の跳び番(ストライド)が 1 ずつと言う意味であり、この場合は連続アクセスすると言う意味です。いわゆる、一般的なアクセスです。Stride-2 のアクセスとは、1, 3, 5, ...と言う風に一つおきにアクセスすることを言います。例えば、Fortran 配列 A(3,2) の場合の各配列要素のメモリ配置上の並び方は、(1,1),(2,1),(3,1),(1,2),(2,2),(3,2)と言う順番でマッピングされています。A(i,j) と言う表記の配列であれば、内側で i ループを1~3まで回し、外側で jループを1~2 と言う形で回せば、メモリ上連続でアクセスできます。この場合を Stride-1 アクセスと言います。もし、先に内側で j = 1, 2 と言う形でループを回せば、要素のアクセスは、(1,1),(1,2),(2,1),(2,2),(3,1),(3,2) と言う風にプログラム上ではアクセスされます。メモリ上で見れば本来の配置ポジションを 2 置き(あるいは、ポインタが前に戻ってから 2 置き)にアクセスすることになります。こうした場合は、連続アクセス性が失われ、アクセス性能を大幅に劣化させます。従って、多次元配列を多重ループ内でアクセスする際に、最内側のループではできるだけ連続でアクセスできるループ・インデックスを選ぶようにしなければなりません。)
メモリに対するキャッシュ階層について
GPU はそもそも、データ依存性がなく、データの再利用性も少ないアプリケーション(グラフィック処理等)で、どんどん結果を出してゆくようなストリーム型、あるいはスループット型計算を志向したものです。したがって、従来のプロセッサで実装されているような、トータルなメモリ性能を上げるための深い「キャッシュ」階層を有していませんでした。特に、Teslaアーキテクチャ(GT200) までの NVIDIA GPU の場合は、大量のデータレジスタ群を利用し、たくさんのスレッドを立ち上げてどんどん計算させてゆくスタイル(これを「マルチスレッディング」と言う。)を行う演算装置と考えた方が素直な説明となります。しかし、汎用的なプログラムをGPU上で利用しようとすると、使用可能なレジスタ数が限界となり、デバイスメモリへのアクセスの割合も大きくなりました。こうなるとメモリ・レイテンシへの対策も必要となり、その対策の一つとして、ソフトウェア・ハンドリングによる低レイテンシで高速な Shared Memory(16KB) をキャッシュとして使用して高速化を図るプログラミングを行うようになりました。これは、GPGPU における重要な性能最適化技法の一つとなっています。特に、HPCのアプリケーションには、こうした Shared Memory を使用する高速化は非常に有効となります。
一方、Fermiアーキテクチャになると、いよいよ「ハードウェア・キャッシュ」階層が出現しました。すなわち、書き込み可能な L2/L1 キャッシュが提供されました。特に、(L1キャッシュ + Shared Memory) は、一つの SM(Streaming Multiprocessor) 当たりトータル 64KB (兼用)が提供され、プログラムで各サイズを可変できる形となっています。ソフトウェアから制御可能な Shared Memory のサイズを変更できることは、汎用的なプログラム、特に HPC系のプログラムにおいて最適化プログラミングの自由度を一層向上させます。また、明示的に Shared Memory を使いにくいアプリケーションに対しては、ハードウェアが制御するL1キャッシュ内のデータをオンチップで再利用できるため、総じてデータアクセス性能(レイテンシを低下させる)が向上します。Fermi以降では、こうしたキャッシュの利用やその容量を多く確保できるShared Memory の活用によって、低速なデバイスメモリとのアクセス・レイテンシを隠蔽しやすくし、汎用プログラム向けのアーキテクチャに変わったと言えましょう。また、このことは HPC 等の汎用的なプログラムの使用可能性(汎用性)を高めたと言うことも言えます。
※ HPC 等で使用する汎用プログラムのCPU内における動作特性は、データレジスタとキャッシュを非常に多用してデータの再利用を図ると言う特性を有します。プログラム実行時、データアクセスの局所性(近傍のデータを多く使用)を利用するためにキャッシュを使用して、実メモリアクセスのロード・ストアを軽減して性能を向上させています。これが、「汎用的」と言われるプログラム特性です。
PGI コンパイラでは、こうしたキャッシュをどのように使えるのでしょうか? PGI Accelerator programming model(ディレクティブ使用)のコンパイルモードでは、コンパイラが分析してできるだけ Shared Memory をキャッシュとして活用できるようにコードの生成を試みますが、そのサイズとの兼ね合いで全てのプログラムが Shared Memory を使用できる訳ではありません。一方、CUDA Fortran の場合は、attribute(shared) 宣言を使用して明示的に Shared Memory を使用するようにプログラムを作成できます。
PGI Accelerator プログラミングモデルの場合のコンパイル情報 338, Loop is parallelizable Accelerator kernel generated 334, !$acc do parallel(16) Cached references to size [130x3x3] block of 'p' PGI CUDA Fortran場合のShared memory の使用 attributes(global) subroutine sgemm16x16(a, b, c, m, n, k, alpha, beta) real, device :: a(m,*), b(k,*), c(m,*) integer, value :: m, n, k real, shared, dimension(17,16) :: bs
Streaming Processor あるいは CUDA Core(演算器)の構成
NVIDIA GPU は、数多くのプロセッサを有しています。また、これらのプロセッサは同時に演算が可能な構造となっています。Teslaアーキテクチャ(GT200) の場合、8 個の Streaming Processors (演算器の最小単位)を「一つの単位グループ」として、これが 30 セットの演算装置 (8x30=240 processors) として実装されています。Fermi の場合は、16 個の Streaming Processors(CUDA Cores とも言う。)の二つを「一つの単位グループ」として、16 セット(16x2x16=512 cores) 実装されています。NVIDIA では、この「一つの単位グループ」を Streaming MultiProcessor (SM) と称してハードウェア上で区別された演算装置となっています。さて、演算器の最小単位である 1 streaming processor or 1 CUDA core は、ひとつのスレッドがシーケンシャルに実行できる単位となります。実際には、同じグループ内に存在する Streaming Processor は、全て同じインストラクション(命令)を同時に実行するスタイルをとります。NVIDIAの用語では、これを SIMT (Single Instruction, Multiple Thread) と称しています。SIMT とは、従来の SIMD (Single Instruction, Multiple Data) と同じ概念と考えください。また、「ベクトル処理」と同じと考えても良いです。従って、NVIDIAの GPU 内では、「一つの単位グループ(SM)内のプロセッサ」を使ってベクトル処理を行う機構を有していることを理解して下さい。また、NVIDIAアーキテクチャ上、「常に同じ命令を実行するスレッド」の固まり(グループ)があることを理解して下さい。ここで余談ですが、「なぜ、NVIDIAの GPU には、こうした SIMD あるいはベクトル実行を行う SM と言う機構が備えられているか?」という疑問が沸いてきませんか?全ての演算器がマルチスレッドで並列に動作させた方がアーキテクチャとして単純ではないか?と言うことを考える方もいるかと思います。これについては、私の別のコラムで説明していますのでご参照下さい。
さて、NVIDIAのアーキテクチャには、一つの演算動作の単位である「スレッド」の動作方法について、ハードウェア的にもう一つ決まり事があります。これは「Warp」と言う概念であり、スレッドの動きは全て「Warp」単位で制御されています。現在、NVIDIA の GPU は世代が変われど、1 Warp の単位は 32スレッド固定とされています。すなわち、32スレッドが同じ命令を実行する(SIMT or SIMD or Vector)と言う動作形態を採用し、Warp 内では命令列を必ず順番に(In-Order)実行しています。こうしたスレッドの実行グループの動き方を「ベクトルプロセッサ」として見立てることもできます。すなわち、ハードウェア上で論理的に 「32 のベクトル長」を有するベクトルプロセッサであるということができます。実際は、 32 の同時実行を行おうにも、物理的なハードウェアとしては、Teslaアーキテクチャ(GT200) の場合で、1 SM 当たり 8 個の Streaming Processors(SP)しか有しない。すなわち、8 スレッドしか 1 タイムスライスに同時実行できない(8並列スレッドが物理的ベクトル長の最小単位)。そこで、各 SP は、4 サイクルを使用して、同じ命令を「異なる」スレッドに対して実行するような形態を取ります。このように、1サイクル単位ではなく、「4サイクル毎に 1 Warp 単位の 32 スレッド束のベクトル実行」が可能となっています。 それでは、新しい Fermi ではどうでしょう。Fermiでは、物理的に 16 CUDA コア演算ユニット(物理ベクトル長が16と同意)を一つのグループとして二つ実装されています。Warp の概念は同じですので、32 スレッドのベクトル実行を行うには、2 サイクル使用して 32スレッド束ベクトル(1 Warp) 実行します。このグループが二つありますので、同時に動作すると、2 サイクル毎に 2 個の Warp を実行できます。
次に、GPUの中の演算器の概略も簡単に述べておきます。Teslaアーキテクチャ(GT200) の場合、一つの SM の中の 8 個の SP(コア)には、それぞれ整数演算あるいは単精度浮動小数点演算のユニットが実装され、さらに、SM 内で共有となる超越関数演算と倍精度浮動小数点演算を行う演算器(SFU)が実装されています。性能的な観点で見れば、一つの SM にいおいて、単精度演算器 8 個に対し、倍精度演算器が一つという形となり、倍精度演算性能は単精度演算に比べて 1/8 の性能比を有する GPU と言うことになります。一方、Fermiアーキテクチャ(GF100) の場合は、一つの SM は 16 コアの単位で 2 グループの CUDA コアを有し、2サイクルで二つの Warp のそれぞれに、整数演算あるいは単精度浮動小数点演算の命令を実行できます。倍精度演算に関しては、二つのグループのコア(16 core x 2) を組み合わせ、16-core の倍精度演算器と見立てて実行します。従って、Fermi は、単精度演算のピーク性能に対して、その 1/2 の倍精度演算能力を有します。
様々なレイテンシを隠蔽する仕組みとスレッド・スケジューリング
従来の CPU に較べて、GPUの演算性能は速いと言う仕組みはぼんやりと理解しているが、何か腑に落ちないと言う人も多いことでしょう。確かに、演算を行うコア数は、従来の CPU のコア数に較べて多いと言うことは、性能を左右する前提となることですが、この多数のコアをできるだけ遊びがなく、同時多重で稼働させることによって性能向上をもたらしています。実は、従来のCPU技術は、この「演算器が遊びなく動く」ように改善してきた歴史でもあります。しかし、そうは言え演算器が常に休みなく動作する状況は稀であり、ほとんどは何らかの「待ち」が生じているのが、現在のCPUの動作状況と言えましょう。例えば、ある二つのデータの乗算を行うとした状況でも、演算を行うためには、データをメモリからロードする必要があります。メモリからのデータをアクセスしてくることは、上述したとおり、演算の処理サイクル時間に較べて数百倍もの時間が掛かります。メモリアクセスに関わる「演算の準備が整うまでの時間」をメモリ・レイテンシ(遅延)と言います。現在のプロセッサ技術で言うと、このレイテンシが一番大きいため、多段階層のキャッシュを置いています。また、演算器の命令実行時においても、命令間の依存性等による実行の遅れ(これを「命令実行のレイテンシ」とも言う)によって、命令の実行が常に一定のサイクル毎に行われる訳ではありません。こうした、「命令の連続実行」できない状況が、様々なレイテンシ要因によって生じているのが、GPUを含めたあらゆるプロセッサ技術の現実となっています。「レイテンシ」は決してゼロにはならない状況で性能を向上させるには、この「レイテンシ」の時間を覆い隠す仕組みを作れば良いと言うことになります。そもそも、このレイテンシは、処理の「シリアル処理」を行っている際に大きく顕在化します。シリアル実行の場合は何らかの原因で途中で命令実行が止まったら(ストールしたら)、これを「待つ」以外に手がないのです。従来の CPU(1コア)では、大げさに言えば、こう言った状況で動いています。もちろん、キャッシュでメモリ・レイテンシを極力小さくし、Out-of-Order と言う命令の発行方法等で、コア内の演算器の多重利用を行うと言ったハードウェア上の最適化は行われていますが、様々なレイテンシを全て覆い隠すほどの有効な手立てはありません。従って、現在の 1CPU(1コア)実行時の大きな性能最適化手法は、レイテンシの大きな部類のメモリアクセスに関して手を入れると言った、すなわち、キャッシュを有効活用できるようにプログラムを変更する位しか手がないと言うのが現状です。
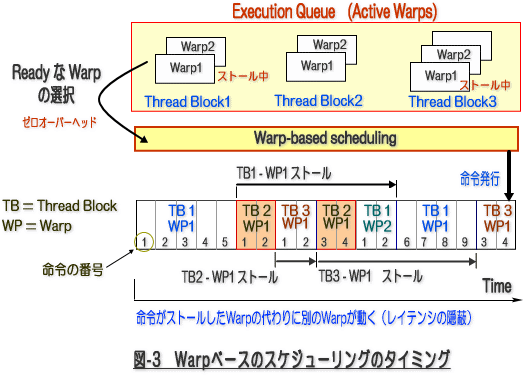
さて、GPUのアーキテクチャではどうでしょう。NVIDIA の GPU computing は、本質的に、①演算データに関するベクトル・並列依存性がない保証をユーザプログラムで実現していること、②異なるWarp間では、その演算命令に依存性がない、③数百~千規模の「マルチスレッド処理」を行うことができる軽量なスレッド・プロセッサを備えていること、と言うような特長を有します。①は、論理的な実行形式の固まりである「スレッド・ブロック(単にブロックとも言う。)」が、個々に「並列実行できる命令列の固まり」として構成されていることを意味します。また、「スレッド・ブロック」内のハードウェア動作上の最小ベクトル実行単位であるWarpも、②で言うとおり、他のスレッド・ブロックの Warp 同士の演算命令に依存性がないと形となっています。GPUの SM 上にある命令スケジューラユニットは、従来の CPU が行っているような「並列に実行可能な命令を見つける」と言った複雑な処理を行わなくて良いわけです。命令発行のスケジューラーは、何の躊躇もなく Out-of-Order(順不同)で、命令実行準備が終了している Active Warp の命令を発行していきます。命令スケジューラのキューの中に、実行が可能な Warps (Ready Warps)が複数存在していれば、命令スケジューラは、オーバーヘッド無しに ready な命令を次々に発行します(zero-overhead thread scheduling)。こうした Active な Warp とは、実行のためにキューに入っているものや、メモリ・トランザクションあるいは、命令のフェッチ等でストール(停止)状態が終えたものを指します。一つの SM に対して、Active Warps が多数存在すれば、連続の命令発行が可能となり、論理的に見ればマルチスレッド実行の「多重度」が向上しているように見える、ハードウェア的に見れば、一つの SM の演算器を「遊びなく」利用できると言うことになります。すなわち、何らかのレイテンシ要因でストールしているスレッドの合間に、別のスレッドが「実行している状態」となるため、これが結果として「ストールした状態=レイテンシ」を覆い隠すことになります。すなわち、GPU が高速に演算できる原理とは、「非常に多くのスレッドを起動すること=マルチスレッディング」と「キャッシュ等の活用によるメモリ・レイテンシの極小化」の二つの方法によるものと言えます。
マルチスレッディングの実行を制限、制約するもの
今までの話から、とりあえず、GPU向けのプログラムの最適化の方法としては、まず第一義に、多くのスレッドを立ち上げるようにすれば良いだろうと言う見当がつきます。しかし、ここにまた制約条件があります。すなわち、GPUのハードウェア自体が持つ1 SM 当たりの起動可能なWarp数やスレッド数、スレッド当たり使用できるレジスタ量等に制約条件がいくつかあります。以下の表を見て下さい。
| ハードウェア仕様 | Tesla (GT200) | Fermi (GF100) |
|---|---|---|
| Threads / Warp (Warpサイズ) | 32 | 32 |
| Max. Threads per Thread Block (SIMD width) | 512 | 1024 |
| Max. Threads / Streaming Multiprocessor | 1024 | 1536 |
| Warps / Streaming Multiprocessor | 32 | 48 |
| Thread Blocks / Streaming Multiprocessor | 8 | 8 |
| Shared Memory per Multiprocessor (bytes) | 16384 | 49152 |
| Total # of 32-bit registers per Multiprocessor | 16384 | 32768 |
特に、赤太字で示す仕様は、スレッド(or Warp)の同時多重実行数を制約する重要なパラメータです。一つの SM 上で、動作可能な Warp 数は、GT200系では、最大32個、Fermi では 48個しか起動できないと言う制約と、異なるスレッド・ブロックは、最大 8 個しかキューイングできないと言う制約です。こうした制約が、実際のプログラムの構造とどのように関わりがあるのかを説明するためには、CUDAプログラミング環境の「スレッド・ブロック」と言った論理的な概念とハードウェアの Warp 等の概念とマッチングを図る必要があります。
プログラムから見たスレッド・ブロックと SM 上での動作形態
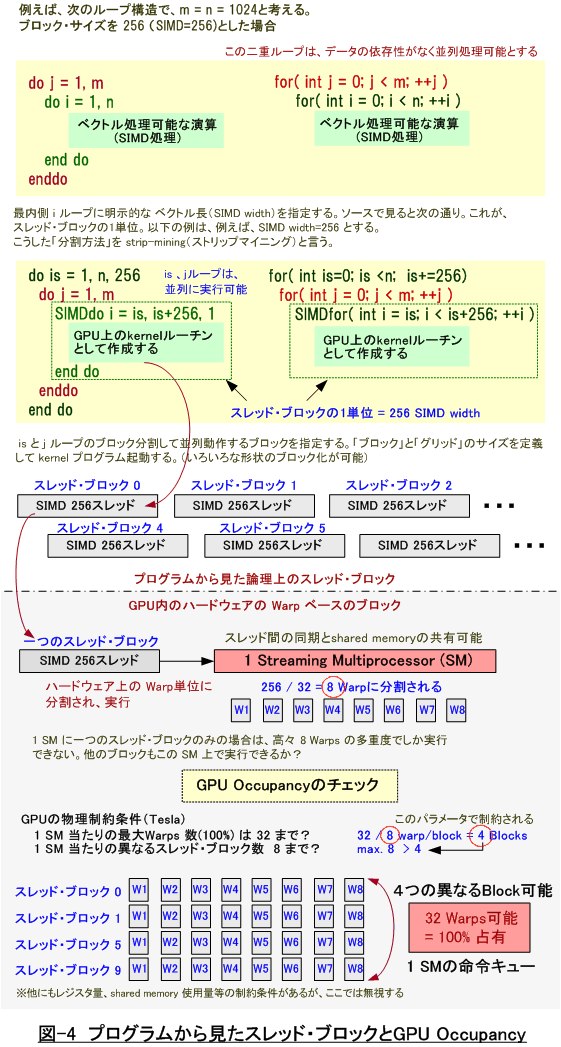
マルチスレッディングにおける同時多重実行数の制約は、実際のプログラムの構造とどのように関わりがあるのかを説明しましょう。以下の図-4 の Fortran あるいは C の単純なループ構造で考えます。この図では、重要な説明が含まれています。ソースプログラムから見て、CUDA の概念で言う GPU内での実行の最小単位である「kernel program」と「SIMD widthを有するスレッド・ブロック」の概念が理解できるかと思います。基本的に、並列化可能な多重ループ構造の場合は、どのループインデックスで並列分割してもよいわけですが、GPU 内の SM 上で独立で動作する基本単位である「スレッド・ブロック」は明確にしなければなりません。以下の例では、最内側 i ループを 256 のベクトル長(SIMD width) で分割して、これをスレッド・ブロックとして定義しています。ここでは、仮に1次元構造のブロックとしています。また、ここで言うベクトル長をCUDA流に厳密に表現すると「Threads Per Block」となります。表-2 に示したとおり、このベクトル長の上限値も Compute Capability によって異なります。この例では、256スレッド単位で、異なるスレッド・ブロックが形成されますが、各スレッド・ブロックは、任意の SM にスケジューリングされます。1スレッド・ブロック内の全てのスレッドは、SMの中で SIMD 演算が行われ、必要であれば同期処理や shared memory をキャッシュとして共用使用することもできます。また、1 スレッド・ブロック、この例では256スレッドの固まりは、必ず、同一の SM 上で演算されると言うことも重要な決まりごとです。逆に言えば、同一 SM 内で処理ができるから、同期処理やShared memory をキャッシュとして利用可能となると言うことになります。さらに、一つの SM には、同時に異なるスレッド・ブロックもキューイングされることもできます。これは、表-2 で示した SM のハードウェア制約条件を満足すれば、異なるスレッド・ブロックの WARP が命令キューに置かれます。この異なる複数のスレッド・ブロックを一つの SM の中に共存させることができることも、Warp の多重キューイングを加速し性能を向上させるようなメカニズムとなっていると言えましょう。
さて、プログラム上の論理的なスレッド・ブロックという単位で kernel プログラムを並行に動作させることまでは、理解できたと思います。(ここでは、プログラム上の do/for ループをどのようにスレッド・ブロックに分割し、これを単位として全体をどう言う並列実行形態に分割するかと言う Grid の概念の説明は割愛します。これについては、私の別のコラムをご参照下さい。 また、併せて、NVIDIA社の CUDA プログラミング・ガイドの 7 ページ第2章をご参照下さい。)
次に、論理的なスレッド・ブロックがハードウェア上の SM にスケジューリングされた際の状態を説明します。一つのスレッド・ブロックが 256 の SIMD スレッドの場合、SM上では 物理的に Warp と言う 32 スレッド単位で実行が行われるため、複数の Warp に分割されます。即ち、各スレッド・ブロックは、物理的に 256/32 = 8 Warps を持つことになります。8個の分割された Warp は、図-3 で説明したように SM 上の Warp 単位でのスケジューリング・キューに置かれ、ready となっている Warp が実行されます。前述のとおり、一つの SM は、表-2 の制約条件を越えない限り、より多くのスレッド・ブロックとその Warp を SM 内にキューイングできます。例えば、Teslaアーキテクチャの場合は、32 Warps / SM を保持できるため、256 の SIMD スレッドのブロックは、さらに異なる4つのスレッド・ブロックを保持できます。この4つのスレッドブロックは、もう一つの制約条件である、1 SM 内には 8 スレッド・ブロック以内と言う条件も満足できます。すなわち、1 SM のフルスペックの 32 Warp 数を保持できるため、この場合 Occupancy = 100% の状況となります。Occupancy とは、1 SM に許容されている実行スレッドの最大数に対して、どの程度使用しているかと言う指標です。同じ条件で、Fermiの場合はどうでしょう。最大48 Warps / SM まで可能ですので、48 / 8 warp/block = 6 スレッド・ブロックまでキューイングでき、1 SM 内には 8 スレッド・ブロック以内と言う条件も満足します。従って、これも Occupancy = 48/48 = 100% の状態で active な Warp をセットすることができます。Occupancy はいつも 100% と言う訳ではありません。SIMD の長さを 64 に小さくしてみると、Occupancy は低下します。1スレッド・ブロック当たりの Warp 数(=2)が小さくなるため、1 SM 内に 8 スレッド・ブロック以内と言う条件が優位になり、最大 8 個のスレッド・ブロックしか動作させることができず、従って総 Warp 数 16しかキューイングできません。一つの SM 上で、Acitive Warp が 16 しか動かせない状態と言うことですから、Fermi(CC 2.0)であれば 16/48 =33% の Occupancyと言うことになります。Tesla アーキテクチャの場合は、16/32 = 50% の Occupancyと言うことになります。なお、Occupancy の値が高ければ、性能が確実に向上するわけではありません。経験的には、この値は 50~66%以上の目安で、SIMD width = Threads Per Block を設定することが望ましいと言われています。
PGI 10.5 以降の Occupancy Estimator の情報表示
Occupancyを決めるパラメータは、他にもあります。表-2 に示したとおり、1 SM 内に存在する Shared memory とレジスタ数は共有資源であるため、これらの使用量が多ければ、割り当て可能なスレッド数、あるいはブロック数に制約が出てきます。特に、 SM 内で kernel が使用する1スレッド・ブロック当たりの shared memory の量や 1 スレッドが使用するレジスタの量も 一つの SM 内にスケジューリング可能な Warp 数 を制約するパラメータとなります。この三つのどれかが、それぞれの動作仕様条件を越えた場合、そのパラメータが Occupancy を支配するものとなります。これを越えた Occupancy は確保できません。これらは、PGI Accelerator Programming Model では、プログラムの特性に応じてコンパイラがその資源量を確保するため、その情報を確認して最適化の一助にすることをお勧めします。Occupancy を決めるパラメータは、以下の三つとなります。
- スレッド・ブロックのスレッド数(SIMD width)
- 1スレッドが使用するレジスタ量(maxregcount)
- 1スレッド・ブロック当たりの shared memory の量
PGI 10.5 以降、PGI Accelerator コンパイラで、-Minfo あるいは、 -Minfo=accel オプションを付けてコンパイルすると、各 kernel の Occupancy 情報を表示できるようになりました。以下のコンパイル・リストには、その情報が含まれております。ハードウェアの Compute Capability (CC) によって、これらの情報は変化しますが、CC 1.3 の場合は、1スレッド当たり28レジスタを使用し、ブロック当たり 4707 KBの shared memory を使用した場合、この kernel は 37% の Occupancy であることを示しています。また、CC 2.0 の場合は、Occupancy は、58% であると言った具合です。ユーザにとっては、SIMD width を変化させること、あるいは、-ta=nvidia,maxregcount:N (PGI Accelerator) 、-Mcuda= maxregcount:N (PGI CUDA Fortran) でレジスタの最大の使用量を変更することで、この Occupancy 値を変化させることができます。繰り返しますが、Occupancy の高い値が高性能を保証するわけでありませんので、Occupancy が多少下がっても使用可能とするレジスタ量を多く指定した方が性能が高い場合も多々あります。この辺は、試行錯誤で最適な性能値になるように調整することが必要です。なお、NVIDIA社の CUDA サイトには、こうしたパラメータを入力することで、Occupancy を計算する「CUDA GPU Occupancy Calculator」ファイルがありますので、一度、試してみて下さい。
PGI Accelerator プログラミングモデルの場合のコンパイル情報(PGI 10.5以降)
338, Loop is parallelizable
Accelerator kernel generated
334, !$acc do parallel(32)
Cached references to size [130x3x3] block of 'p'
336, !$acc do parallel
338, !$acc do vector(128) = SIMD の width 128
CC 1.3 : 28 registers; 4704 shared, 188 constant, 0 local memory bytes; 37 occupancy
CC 2.0 : 36 registers; 4688 shared, 192 constant, 0 local memory bytes; 58 occupancy
NVIDIA GPU 上で性能を向上させるための方法
以上のアーキテクチャの説明を纏めて、GPU のアーキテクチャの特徴に対して、その性能を向上させるために行うべきプログラム最適化のアイテムは大まかに言えば、次の通りです。これに関して、もっと具体的に、こちらのコラムでも説明しています。
- プログラム内に、GPU 上の全てのマルチプロセッサを稼働させるに十分な並列性を見出すこと
- CUDA core を常にビジーにするようなマルチスレッディングの状態を作り出せるような並列性を確保すること(並列の粒度、スレッド・ブロックのサイズ、グリッドの構成)
- 連続的にデバイスメモリ上のデータをアクセス(Stride-1 )するように最適化すること
- 中間の計算結果をストアするために、ソフトウェア・データ・キャッシュを使うこと、あるいは、non-stride-1 となるようなデータアクセスに対して、このアクセスを再構築するためにキャッシュを使用する
【Reference】
- Michael Wolfe, The PGI Accelerator Programming Model on NVIDIA GPUs Part 1
- Michael Wolfe, The PGI Accelerator Programming Model on NVIDIA GPUs Part 2 Performance Tuning
- David Kanter, Inside Fermi: Nvidia's HPC Push
- David Kanter, NVIDIA's GT200: Inside a Parallel Processor
- NVIDIA, CUDA C Programming Guide
- NVIDIA, CUDA C Best Best Practices Guide
さて、次回は、PGIアクセラレータによる行列積の計算について説明します。