HPC用のコンパイラ、ライブラリ、ツールの包括的パッケージ
NVIDIA HPC SDKを使うことにより、HPC開発者は、インターコネクトを介してGPUからCPUにおよぶHPCプラットフォーム全体をプログラムできるようになります。
NVIDIA HPC SDKは、アクセラレーテッドコンピューティングシステムをプログラミングするための唯一の包括的な統合SDKです。
NVIDIA HPC SDK C++およびFortranコンパイラは、C++17の並列アルゴリズムやFortranのIntrinsicなど、標準言語構造の自動GPUアクセラレーションをサポートする、初めてかつ唯一のコンパイラです。

NVIDIA HPC SDK の特徴
GPU数学ライブラリ
cuBLASおよびcuSOLVERライブラリは、可能な場合は自動的にNVIDIA GPU Tensorコアを使用して、LAPACKのすべてのBLASルーチンおよびコアルーチンのGPU最適化およびマルチGPU実装を提供します。cuFFTには、実データおよび複素数データ用のGPU高速1D、2D、3D FFTルーチンが含まれており、cuSPARSEはスパース行列用の基本的な線形代数サブルーチンを提供します。これらのライブラリは、C、C ++、およびFortranで記述されたCUDAおよびOpenACCプログラムから呼び出すことができます。
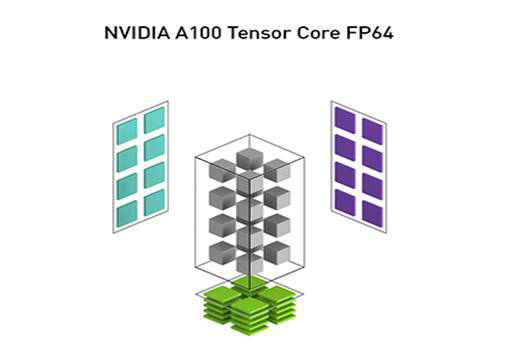
Tensorコア向けに最適化
NVIDIA GPU Tensorコアにより、科学者やエンジニアは、混合精度または倍精度を使用して適切なアルゴリズムを劇的に加速できます。NVIDIA HPC SDK数学ライブラリはTensorコアとマルチGPUノード用に最適化されており、最小限のコーディングでシステムのパフォーマンスを最大限に引き出すことができます。NVIDIA Fortranコンパイラを使用すると、変形配列組み込み関数をcuTENSORライブラリに自動的にマッピングすることにより、Tensorコアを活用できます。

CPUに最適化
HPCサーバーは、x86-64、OpenPOWER、またはArm命令セットアーキテクチャに基づく高速コンピューティングおよびマルチコアCPUにGPUを使用します。NVIDIAコンパイラとツールはこれらのすべてのCPUでサポートされており、すべてのコンパイラ最適化はそれらをサポートするすべてのCPUで完全に有効になっています。NVIDIA HPC SDKは、サポートされているすべてのシステムにわたって統一された機能、コマンドラインオプション、言語実装、プログラミングモデル、ツールとライブラリのユーザーインターフェイスを備えており、さまざまなHPC環境での開発者エクスペリエンスを簡素化します。
マルチGPUプログラミング
NVIDIA Collective Communications Library(NCCL)は、MPI互換のall-gather、all-reduce、broadcast、reduce、reduce-scatterルーチンを使用して、高度に最適化されたマルチGPUおよびマルチノードの集合通信プリミティブを実装し、HPCサーバーノード内およびノード間で使用可能なGPUを利用します。NVSHMEMは、GPUメモリのOpenSHMEM標準を実装し、ホストCPUまたはGPUから開始して、CUDAカーネル内から呼び出すことができるマルチGPUおよびマルチノード通信プリミティブを提供します。

スケーラブルシステムプログラミング
MPIは、分散メモリスケーラブルシステムをプログラミングするための標準です。NVIDIA HPC SDKには、GPUDirect™をサポートするOpen MPIに基づくCUDA対応のMPIライブラリーが含まれているため、CUDAユニファイドメモリに割り当てられたバッファーを含むリモートダイレクトメモリアクセス(RDMA)を使用してGPUバッファーを直接送受信できます。CUDA対応のOpen MPIは、CUDA C/C++、CUDA Fortran、およびNVIDIA OpenACCコンパイラと完全に互換性があります。
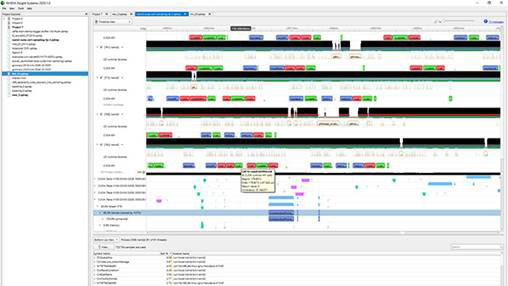
Nsightパフォーマンスプロファイリング
Nsight™システムは、HPCサーバー上のアプリケーションパフォーマンスのシステム全体の視覚化を提供し、ボトルネックを解消し、マルチコアCPUとGPU全体で並列アプリケーションをスケーリングできるようにします。Nsight Computeを使用すると、グラフィカルまたはコマンドラインのユーザーインターフェイスを介して、GPUで高速化されたアプリケーションのインタラクティブプロファイラーでGPUカーネルを詳しく調べることができ、NVTX APIを使用してソースコードの領域を直接計測することで、パフォーマンスのボトルネックを特定できます。

どこにでも導入
コンテナーは、アプリケーションとその依存関係をポータブル仮想環境にバンドルすることにより、ソフトウェアのデプロイメントを簡素化します。NVIDIA HPC SDKには、HPC Container Makerを使用してソフトウェアを開発、プロファイリング、デプロイして、コンテナーイメージの作成を簡略化するための手順が含まれています。NVIDIA Container Runtimeは、DockerやSingularityを含むほぼすべてのコンテナーフレームワークでシームレスなGPUサポートを可能にします。
NVIDIA HPC Compiler & Professional Support Service
HPC Compiler Support Serviceとは・・・
NVIDIAのテクニカルサポートを受けることができます。
HPC Professional Support Serviceとは・・・
HPC Compiler Support Serviceに加え、プロメテック・ソフトウェアによる日本語でのテクニカルサポートを受けることができます。