cuBLASMpを使ったマルチGPU密行列計算 (1)
はじめに
今回は以前のMPIを用いたマルチGPU操作を踏まえ、cuBLASMpを使ったマルチGPU密行列計算を試したいと思います。
cuBLASMpはNVIDIA HPC SDK 24.1以降に同梱されている、cuBLASのマルチノード並列対応版です。
BLASのマルチノード版である、PBLASの立ち位置です。
cuBLASが内部的にはCUDAライブラリを用いたマルチGPU計算を実現しているのに対し、cuBLASMpはMPIを組み合わせることで以下のすべての環境に対応できる密行列計算コードを構築できます。
- GPU 1台
- 1台の計算機上でのマルチGPU
- 複数台の計算機を用いたマルチGPU
前半の2つはcuBLASでも実行できますが、cuBLASMpにより、多くの環境かつ大量のメモリを駆使した密行列計算が1つのコードで実現可能です。
コードはPBLASに近いC言語のインターフェイスを提供し、2次元のBlock-Cyclic分割での並列計算を提供します。
cuBLASMpを動かすための構成と、実際にcuBLASMpを使って最も簡単な行列の加算を実行してみます。
cuBLASMpの処理の流れ
cuBLASMpドキュメントには初期化から計算、終了処理までは以下の流れになる、と簡単に書いてあります。
PBLASやScaLAPACKを使ったことがある方は、馴染みのある流れかもしれません。(一旦は読み飛ばして問題ありません)
- (MPIを初期化して各プロセスで利用するGPUを決定する)
- CALライブラリハンドルを初期化する
- cuBLASMpライブラリハンドルを初期化する
- grid descriptorsを初期化する
- matrix descriptorsを初期化する
- ホストおよびデバイスに必要なバッファサイズを求める
- ホストおよびデバイスのワークスペースバッファを確保する
- 計算処理を実行
- 計算の完了を待つ
- ホストおよびデバイスのワークスペースバッファを解放する
- matrix descriptorsを破棄する
- grid descriptorsを破棄する
- cuBLASMpライブラリハンドルを破棄する
- CALライブラリハンドルを破棄する
- (MPIライブラリハンドルを破棄する)
上記の順番にしたがって、cuBLASMpのコードを書いて動かしてみたいと思います。
コードサンプルも公開されていて、現在cuBLASMpで利用できる計算ルーチンのサンプルがすべて提供されているので、こちらも参考にしてください。
注釈: コードサンプルとドキュメントについて
cuBLASMpは2024年11月のリリース(v0.3.0)において、関数の引数が変わるなどの大幅な仕様変更が行われました。(参考)
HPC SDK 24.11に同梱のcuBLASMpは仕様変更前のバージョン(v0.2.1)であるため、コードサンプルはそのままでは動作しません。
cuBLASMpの最新版を別途インストールするか、v0.2.1の仕様に対応したコードに修正する必要があります。
なお、本記事ではHPC SDK 24.11同梱のcuBLASMp v0.2.1を使用します。
実装
GPUを有効にしたMPIの初期化や終了処理は、OpenACC/MPIによるマルチノード・マルチGPU計算を参照してください。
GPUの選択はCALライブラリを経由しますので、各プロセスがローカルにあるどのGPUを利用するか選択するだけです。
CAL (Communication Abstraction Library)
CALというライブラリが突然現れますが、ドキュメントにはcuBLASMpで制御するGPU間の通信を効率化するための抽象化ライブラリであると説明しています。
かなり低レイヤーな抽象化ライブラリのようで、ドキュメントにはMPIを使ったCAL初期化の例が記載されています。
コードサンプルも同じものが使われていて、いまのところそのまま使っておけば間違いなさそうです。
まずCALの初期化までのコードが以下です。
#include <mpi.h>
#include <cal.h>
#include <cublasmp.h>
#include <cassert>
/* ------------------------------ */
/* CAL利用の定型文: ここから */
/* ------------------------------ */
calError_t allgather(void* src_buf, void* recv_buf, size_t size, void* data, void** request)
{
MPI_Request req;
int err = MPI_Iallgather(src_buf, size, MPI_BYTE, recv_buf, size, MPI_BYTE, (MPI_Comm)data, &req);
if (err != MPI_SUCCESS)
{
return CAL_ERROR;
}
*request = (void*)req;
return CAL_OK;
}
calError_t request_test(void* request)
{
MPI_Request req = (MPI_Request)request;
int completed;
int err = MPI_Test(&req, &completed, MPI_STATUS_IGNORE);
if (err != MPI_SUCCESS)
{
return CAL_ERROR;
}
return completed ? CAL_OK : CAL_ERROR_INPROGRESS;
}
calError_t request_free(void* request)
{
return CAL_OK;
}
calError_t cal_comm_create_mpi(MPI_Comm mpi_comm, int rank, int nranks, int local_device, cal_comm_t* comm)
{
cal_comm_create_params_t params;
params.allgather = allgather;
params.req_test = request_test;
params.req_free = request_free;
params.data = (void*)mpi_comm;
params.rank = rank;
params.nranks = nranks;
params.local_device = local_device;
return cal_comm_create(params, comm);
}
/* ------------------------------ */
/* CAL利用の定型文: ここまで */
/* ------------------------------ */
int main(int argc, char** argv)
{
MPI_Init(&argc, &argv);
int rank, size;
MPI_Comm mpi_comm = MPI_COMM_WORLD;
MPI_Comm_rank(mpi_comm, &rank);
MPI_Comm_size(mpi_comm, &size);
// ローカルのMPIランクから利用するGPUを選択
const char* local_rank_env = getenv("OMPI_COMM_WORLD_LOCAL_RANK");
assert(local_rank_env != NULL);
const int local_device = atoi(local_rank_env);
// CALハンドルをMPIを使って初期化
cal_comm_t cal_comm;
cal_comm_create_mpi(mpi_comm, rank, size, local_device, &cal_comm);
/* cuBLASMpの初期化、計算、終了処理 */
// CALハンドルの破棄
cal_comm_destroy(cal_comm);
MPI_Finalize();
}
NVIDIA HPC SDKは24.11を利用しています。
CALを利用するにはlibcal.soをリンクする必要がありますが、NVIDIA HPC SDK提供のenvironment modulesのファイルでは必要なライブラリのサーチパスが登録されません。
LD_LIBRARY_PATHは登録されているので、これをそのままLIBRARY_PATHにしてビルドするとリンクできます。
$ module load nvhpc/24.11
$ LIBRARY_PATH=${LD_LIBRARY_PATH} mpic++ -cuda -o xcal_init cal_init.cc -lcal
コンパイル後、以下のコマンドで2プロセス以上で動作しリターンコードが0であればOKです。お使いの環境を確認してお試しください。(検証環境では、1プロセスでは原因がはっきりしないSEGVが発生し動作しませんでした)
$ mpiexec --bind-to none -np 2 --mca coll ^hcoll ./xcal_init
$ echo $?
0
cuBLASMpを使った行列加算
cuBLASやcuSPARSE、またはScaLAPACKを使ったことがあるとわかりやすいのですが、cuBLASMpの実行には多くのステップが必要で、サンプルコードでも若干長いです。
ただ一度覚えると概ね定型文だというのが理解できるかと思いますので、この記事はコードにコメントを書く形で、一度全体を書き出します。
コメントには冒頭の処理の流れに対応する番号をつけています。
#include <mpi.h>
#include <cal.h>
#include <cublasmp.h>
#include <vector>
#include <cassert>
// ---
// CAL利用に必要な関数群が入る
// ---
int main(int argc, char** argv)
{
MPI_Init(&argc, &argv);
int rank, size;
MPI_Comm mpi_comm = MPI_COMM_WORLD;
MPI_Comm_rank(mpi_comm, &rank);
MPI_Comm_size(mpi_comm, &size);
// 1. ローカルのMPIランクから利用するGPUを選択
const char* local_rank_env = getenv("OMPI_COMM_WORLD_LOCAL_RANK");
assert(local_rank_env != NULL);
const int local_device = atoi(local_rank_env);
// 2. CALハンドルをMPIを使って初期化
cal_comm_t cal_comm;
cal_comm_create_mpi(mpi_comm, rank, size, local_device, &cal_comm);
// cuBLASMpはCUDA streamが必須
// default streamは現段階でサポートされない
cudaStream_t stream = NULL;
cudaStreamCreate(&stream);
// 行列形状と分割単位
// 2D block-cyclic分割のため行列方向でブロッキングの単位を指定
// 今回は2D block分割と同等に設定
const int64_t m = 4, n = 4;
const int64_t mb = 2, nb = 2;
// 行列をどのようにcuBLASMp (MPI) で分割するかの設定
// 今回は行と列を2分割する
const int64_t nprow = 2, npcol = 2;
const int64_t myprow = rank / npcol;
const int64_t mypcol = rank % npcol;
// ローカル部分行列の形状 [lldx, loc_n_x] を計算
const int64_t llda = cublasMpNumroc(m, mb, myprow, 0, nprow);
const int64_t loc_n_a = cublasMpNumroc(n, nb, mypcol, 0, npcol);
const int64_t lldc = cublasMpNumroc(m, mb, myprow, 0, nprow);
const int64_t loc_n_c = cublasMpNumroc(n, nb, mypcol, 0, npcol);
// 各プロセスのCUDAデバイス上に部分行列A, Cを生成
std::vector<double> h_A(llda * loc_n_a, 0);
std::vector<double> h_C(lldc * loc_n_c, 0);
/* matrix A
rank 0 = [ 0, 1, 2, 3]
rank 1 = [ 4, 5, 6, 7]
rank 2 = [ 8, 9, 10, 11]
rank 3 = [ 12, 13, 14, 15]
global = [ 0, 1, 4, 5]
[ 2, 3, 6, 7]
[ 8, 9, 12, 13]
[ 10, 11, 14, 15]
*/
for(int64_t ia = 0 ; ia < llda ; ++ia)
for(int64_t ja = 0 ; ja < loc_n_a ; ++ja)
h_A[ia * loc_n_a + ja] = ia * loc_n_a + ja + rank * n;
/* matrix C
rank 0 = [ 0, 4, 8, 12]
rank 1 = [ 1, 5, 9, 13]
rank 2 = [ 2, 6, 10, 14]
rank 3 = [ 3, 7, 11, 15]
global = [ 0, 4, 1, 5]
[ 8, 12, 9, 13]
[ 2, 6, 3, 7]
[ 10, 14, 11, 15]
*/
for(int64_t ic = 0 ; ic < lldc ; ++ic)
for(int64_t jc = 0 ; jc < loc_n_c ; ++jc)
h_C[ic * loc_n_c + jc] = rank + m * (ic * loc_n_c + jc);
/* C = alpha A^T + beta C
A^T = [ 0, 2, 8, 10]
[ 1, 3, 9, 11]
[ 4, 6, 12, 14]
[ 5, 7, 13, 15]
global = [ 0, 6, 9, 15]
[ 9, 15, 18, 24]
[ 6, 12, 15, 21]
[15, 21, 24, 30]
rank 0 = [ 0, 6, 9, 15]
rank 1 = [ 9, 15, 18, 24]
rank 2 = [ 6, 12, 15, 21]
rank 3 = [ 15, 21, 24, 30]
*/
const double alpha = 1.0, beta = 1.0;
double *d_A, *d_C;
cudaMallocAsync(&d_A, llda * loc_n_a * sizeof(double), stream);
cudaMallocAsync(&d_C, lldc * loc_n_c * sizeof(double), stream);
cudaMemcpyAsync(d_A, h_A.data(), llda * loc_n_a * sizeof(double), cudaMemcpyDefault, stream);
cudaMemcpyAsync(d_C, h_C.data(), lldc * loc_n_c * sizeof(double), cudaMemcpyDefault, stream);
// 3. cuBLASMpのハンドルを初期化
cublasMpHandle_t handle = NULL;
cublasMpCreate(&handle, stream);
// 4. グリッド情報を作成
// MPIランク群がグリッド空間にあるとして、空間情報を管理
// C, C++はRowMajorなので、揃えるのが無難と思われます
cublasMpGrid_t grid = NULL;
cublasMpGridCreate(handle, nprow, npcol, CUBLASMP_GRID_LAYOUT_ROW_MAJOR, cal_comm, &grid);
// 5. descriptorを作成
// サイズやブロック化係数などの行列情報を管理
// 選択できる数値型については以下に記載されています
// ref: https://docs.nvidia.com/cuda/cublasmp/usage/functions.html#cublasmpmatrixdescriptorcreate
cublasMpMatrixDescriptor_t descA = NULL;
cublasMpMatrixDescriptor_t descC = NULL;
cublasMpMatrixDescriptorCreate(handle, m, n, mb, nb, 0, 0, llda, CUDA_R_64F, grid, &descA);
cublasMpMatrixDescriptorCreate(handle, m, n, mb, nb, 0, 0, lldc, CUDA_R_64F, grid, &descC);
// 6. cuBLASMpの計算カーネル用の一時領域 (workspace) のサイズを求める
// LAPACK, ScaLAPACKの一部の計算カーネルと同じことをしています
// ref: https://www.netlib.org/lapack/lug/node118.html
size_t workspaceInBytesOnDevice = 0;
size_t workspaceInBytesOnHost = 0;
cublasMpGeadd_bufferSize(
handle,
CUBLAS_OP_T,
m,
n,
&alpha,
d_A,
1,
1,
descA,
&beta,
d_C,
1,
1,
descC,
&workspaceInBytesOnDevice,
&workspaceInBytesOnHost
);
// 7. workspaceを作成、バイトサイズなのでint8で作成
int8_t *d_work = NULL;
cudaMallocAsync(&d_work, workspaceInBytesOnDevice, stream);
std::vector<int8_t> h_work(workspaceInBytesOnHost);
// リソース作成完了を待つ
// cudaStreamSynchronize + MPI_Barrierと解釈して問題ありません
cal_stream_sync(cal_comm, stream);
cal_comm_barrier(cal_comm, stream);
// 8. compute: C = alpha A^T + beta C
cublasMpGeadd(
handle,
CUBLAS_OP_T,
m,
n,
&alpha,
d_A,
1,
1,
descA,
&beta,
d_C,
1,
1,
descC,
d_work,
workspaceInBytesOnDevice,
h_work.data(),
workspaceInBytesOnHost
);
cudaMemcpyAsync(h_C.data(), d_C, lldc * loc_n_c * sizeof(double), cudaMemcpyDefault, stream);
// 9. 計算完了を待つ
cal_stream_sync(cal_comm, stream);
cal_comm_barrier(cal_comm, stream);
printf("[%d] A^T + C = %2.0f, %2.0f, %2.0f, %2.0f\n", rank, h_C[0], h_C[1], h_C[2], h_C[3]);
// 10--15. 各種リソース等の破棄
// cuBLASMpのリソースの破棄
cublasMpMatrixDescriptorDestroy(handle, descA);
cublasMpMatrixDescriptorDestroy(handle, descC);
cublasMpGridDestroy(handle, grid);
cublasMpDestroy(handle);
// CUDAリソースの破棄
cudaFreeAsync(d_A, stream);
cudaFreeAsync(d_C, stream);
cudaFreeAsync(d_work, stream);
// CUDA Streamに関連付けた全リソースの破棄を待って、CALリソースを破棄
cal_comm_barrier(cal_comm, stream);
cal_comm_destroy(cal_comm);
cudaStreamDestroy(stream);
MPI_Barrier(MPI_COMM_WORLD);
MPI_Finalize();
}
以下では、ポイントとなりそうな箇所やつまづきそうな部分について解説します。
CUDA Stream
現在の実装では、CUDAが自動的に作成するデフォルトのCUDA Streamでは正しく動作しないとのことです。
そのため、cuBLASMpを使う場合にはCUDA Streamを適切に管理する必要があります。
またメモリ確保や転送などcuBLASMp以外のCUDA APIを実行する場合も、実装ミスを防ぐために同じCUDA Streamを使うことをおすすめします。
CUDA公式のサンプルやこの記事では、CUDA Streamを利用するAPIでmalloc, memcpyを実行しています。
行列の分割方法
cuBLASMpでは2D block-cyclic分割で各プロセス = GPUの計算負荷を均一化を試みています。
ScaLAPACKでも同様の分割方法を提供しており、説明はScaLAPACKのドキュメントが詳しいです。
今回は2D block-cyclicではなく2D block分割を使い、4×4の行列を4プロセスに分割し2×2の部分行列を各プロセスが1つずつ持っています。
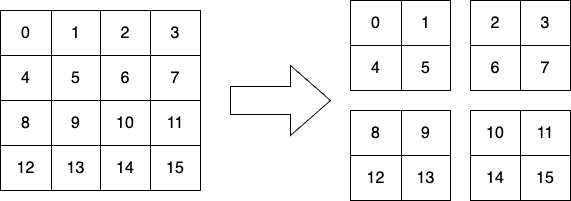
部分行列のサイズ計算
各プロセスが持つ部分行列の形状を得るために、cuBLASMpではcublasMpNumrocヘルパーを提供しています。
全体の行または列のサイズ、求めるプロセスの番号、最初の部分行列 (1行1列目の要素) を持つプロセスの番号、全体のプロセス数を渡して求めます。
このとき、最初の部分行列を持つプロセスの番号は基本的にMPIランクが0のプロセスが持つとして良いと思われます。
cuBLASMpを他の計算処理と組み合わせたとき、最初の部分行列を持つプロセスが変わることはあるかもしれません。
部分行列のインデックス
行列の加算を行うcublasMpGeaddを見ると ia, ja, ic, jc の4つのインデックス引数があると思います。
この引数の説明を見ると部分行列A, Cの最初の行インデックスと列インデックス、を指定するようです。
ですが、MPIランクと同様に0を渡すと計算がうまくいきません。どうやらcuBLASMpの計算カーネルはインデックスが1始まりで計算しているようです。
ScaLAPACKが同様のフォーマット (Fortranが1始まり) のため、それに合わせていると思われます。MPIランクの指定と混同しないように注意してください。
最初の部分行列を持つプロセス番号と同じ理由で、基本的には1固定で問題ないと思われます。
コンパイルと実行
コンパイルは、先程のCALコードのコンパイルに-lcublasmpをつけるだけです。
これを4プロセスで実行すると、以下の出力が得られるかと思います。MPIランク番号でソートしています。
$ module load nvhpc/24.11
$ LIBRARY_PATH=${LD_LIBRARY_PATH} mpic++ -cuda -o ./xgeadd xgeadd.cc -lcal -lcublasmp
$ mpiexec --bind-to none -np 4 --mca coll ^hcoll ./xgeadd
[0] A^T + C = 0, 6, 9, 15
[1] A^T + C = 9, 15, 18, 24
[2] A^T + C = 6, 12, 15, 21
[3] A^T + C = 15, 21, 24, 30
コード上でも計算内容を記載していますが、グローバル行列で示すと以下の計算を行っています。
各プロセスは先程の図のように2×2の部分行列に分割しているので、Aを転置することでグローバルな行列の情報をちゃんと見て計算しているかを検証しています。
A =
0 1 4 5
2 3 6 7
8 9 12 13
10 11 14 15
C =
0 4 1 5
8 12 9 13
2 6 3 7
10 14 11 15
A^T + C =
0 6 9 15
9 15 18 24
6 12 15 21
15 21 24 30
プログラムの実行結果と合わせると、各プロセスが2×2の部分行列を正しく計算できています。
おわりに
長くなりましたが、ざっと説明しました。
定型文と同程度に変数が多く混乱しますが、実際に変更しないといけないのは行列サイズや分割数で、あとは自動的に決定されたり固定することが可能な変数が大半な印象です。
次回は分割方法を変更した場合の挙動と、行列積を使ったパフォーマンスの測定を行えればと思います。
