cuBLASMpを使ったマルチGPU密行列計算 (2)
はじめに
前回はcuBLASMpの使い方を一通り見るために、行列加算のコードを紹介しました。
今回はcuBLASMpで行列積 (GEMM) のコードを実装し、そのベンチマークを取りたいと思います。
行列積は代表的なBLAS演算ですが、2025年現在、大規模言語モデルのアーキテクチャとして最も採用されているTransformerも計算の大部分が行列積で構成されており、ここ数年でさらに重要性が増している (= 高速処理が要求される) 計算です。
cuBLASMp GEMMの最適化パラメータ
cuBLASMpは2D block-cyclic分割を採用しており、計算領域の分散方法としては以下を取ることができます。
- Block分割 (B)
- 各プロセスは1つの連続した計算領域を持つ (C)
- Cyclic分割
- 1行・1列ずつスライスして順にプロセスへ計算領域を割り当てる
- Block-Cyclic分割 (D)
- P行・Q列ずつスライスして順にプロセスへ計算領域を割り当てる
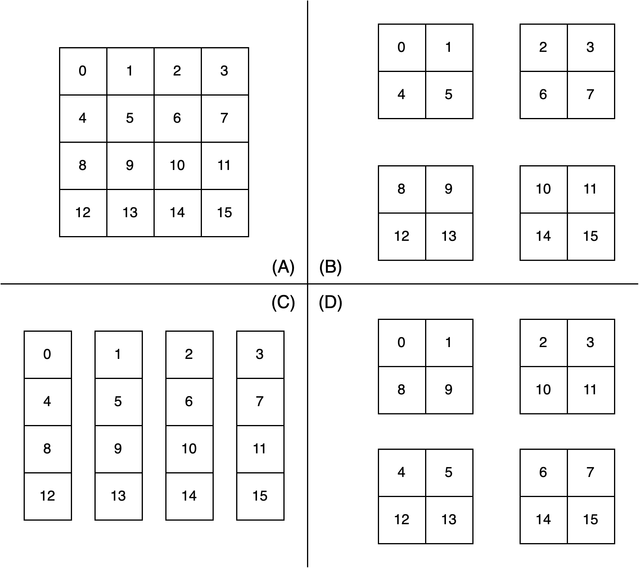
図1 行列を例にしたデータの並列分散方法、(A) 分割前の行列、(B) Block分割、(C) Cyclic分割、(D) Block-Cyclic分割を2行1列のスライスして4プロセスに並列分散した場合
Block分割は前回の行列加算で行った分割方法です。
通信回数を考えると、Block分割は通信が必要なプロセスが最小になると想定されるのでもっとも低コストと考えられます。
しかし、Cyclic/Block-Cyclic分割は行列を小さい単位で分割するので、計算と通信をオーバーラップできる余地が期待されます。
実際にcuBLASMpがどのように最適化されているか、コードにはアクセスできませんが、ベンチマークで適切な分割方法を調査することができます。
GEMMのcuBLASMpでの並列化
前回記事とほぼ同じコードですが、CALの初期化コードのみ省略しました。
#include <mpi.h>
#include <cal.h>
#include <cublasmp.h>
#include <vector>
#include <cassert>
// ---
// CAL利用に必要な関数群が入る
// ---
int main(int argc, char** argv)
{
// 行列積は入出力の型についていくつかの組み合わせが可能
using input_t = double;
using output_t = double;
using compute_t = double;
const cudaDataType_t cuda_input_type = CUDA_R_64F;
const cudaDataType_t cuda_output_type = CUDA_R_64F;
const cublasComputeType_t cublas_compute_type = CUBLAS_COMPUTE_64F;
constexpr int32_t nstep = 10;
float milliseconds = 0.0f;
MPI_Init(&argc, &argv);
int rank, size;
MPI_Comm mpi_comm = MPI_COMM_WORLD;
MPI_Comm_rank(mpi_comm, &rank);
MPI_Comm_size(mpi_comm, &size);
// ローカルのMPIランクから利用するGPUを選択
const char* local_rank_env = getenv("OMPI_COMM_WORLD_LOCAL_RANK");
assert(local_rank_env != NULL);
const int local_device = atoi(local_rank_env);
cudaSetDevice(local_device);
// CALハンドルをMPIを使って初期化
cal_comm_t cal_comm;
cal_comm_create_mpi(mpi_comm, rank, size, local_device, &cal_comm);
// cuBLASMpはCUDA streamが必須
// default streamは現段階でサポートされない
cudaStream_t stream = NULL;
cudaStreamCreate(&stream);
// 行列形状と分割単位
// 2D block-cyclic分割のため行列方向でブロッキングの単位を指定
// 今回は2D block分割と同等に設定
const int64_t m = 8192, n = 4096, k = 8192;
#if defined(CYCLIC_DIST)
const int64_t mb = 1, nb = 1, kb = 1;
#elif defined(BLOCK_DIST)
const int64_t mb = 8192, nb = 4096, kb = 8192;
#else
const int64_t mb = 2048, nb = 1024, kb = 2048;
#endif
// 行列をどのようにcuBLASMp (MPI) で分割するかの設定
// 2並列の場合、行方向で分割する
const int64_t nprow = 2, npcol = 1;
const int64_t myprow = rank / npcol;
const int64_t mypcol = rank % npcol;
// CUDAデバイス上に行列A, B, Cを生成
const int64_t llda = cublasMpNumroc(m, mb, myprow, 0, nprow);
const int64_t loc_n_a = cublasMpNumroc(k, kb, mypcol, 0, npcol);
const int64_t lldb = cublasMpNumroc(k, kb, myprow, 0, nprow);
const int64_t loc_n_b = cublasMpNumroc(n, nb, mypcol, 0, npcol);
const int64_t lldc = cublasMpNumroc(m, mb, myprow, 0, nprow);
const int64_t loc_n_c = cublasMpNumroc(n, nb, mypcol, 0, npcol);
std::vector<input_t> h_A(llda * loc_n_a, 0);
std::vector<input_t> h_B(lldb * loc_n_b, 0);
std::vector<output_t> h_C(lldc * loc_n_c, 0);
for(int64_t ia = 0 ; ia < llda ; ++ia)
for(int64_t ja = 0 ; ja < loc_n_a ; ++ja)
h_A[ia * loc_n_a + ja] = input_t(rand()) / RAND_MAX;
for(int64_t ib = 0 ; ib < lldb ; ++ib)
for(int64_t jb = 0 ; jb < loc_n_b ; ++jb)
h_B[ib * loc_n_b + jb] = input_t(rand()) / RAND_MAX;
const input_t alpha = 1.0f, beta = 0.0f;
input_t *d_A;
input_t *d_B;
output_t *d_C;
cudaMallocAsync(&d_A, llda * loc_n_a * sizeof(input_t), stream);
cudaMallocAsync(&d_B, lldb * loc_n_b * sizeof(input_t), stream);
cudaMallocAsync(&d_C, lldc * loc_n_c * sizeof(output_t), stream);
cudaMemcpyAsync(d_A, h_A.data(), llda * loc_n_a * sizeof(input_t), cudaMemcpyDefault, stream);
cudaMemcpyAsync(d_B, h_B.data(), lldb * loc_n_b * sizeof(input_t), cudaMemcpyDefault, stream);
cudaMemcpyAsync(d_C, h_C.data(), lldc * loc_n_c * sizeof(output_t), cudaMemcpyDefault, stream);
// cuBLASMpのハンドルを初期化
cublasMpHandle_t handle = NULL;
CUBLASMP_CHECK(cublasMpCreate(&handle, stream));
// グリッド情報を作成
// MPIランク群がグリッド空間にあるとして、空間情報を管理
cublasMpGrid_t grid = NULL;
CUBLASMP_CHECK(cublasMpGridCreate(nprow, npcol, CUBLASMP_GRID_LAYOUT_ROW_MAJOR, cal_comm, &grid));
// descriptorを作成
// サイズやブロック化係数などの行列情報を管理
cublasMpMatrixDescriptor_t descA = NULL, descB = NULL, descC = NULL;
CUBLASMP_CHECK(cublasMpMatrixDescriptorCreate(m, k, mb, kb, 0, 0, llda, cuda_input_type, grid, &descA));
CUBLASMP_CHECK(cublasMpMatrixDescriptorCreate(k, n, kb, nb, 0, 0, lldb, cuda_input_type, grid, &descB));
CUBLASMP_CHECK(cublasMpMatrixDescriptorCreate(m, n, mb, nb, 0, 0, lldc, cuda_output_type, grid, &descC));
// cuBLASMpの計算カーネル用の一時領域 (workspace) のサイズを求める
// LAPACK, ScaLAPACKの一部の計算カーネルと同じことをしています
// ref: https://www.netlib.org/lapack/lug/node118.html
size_t workspaceInBytesOnDevice = 0;
size_t workspaceInBytesOnHost = 0;
CUBLASMP_CHECK(cublasMpGemm_bufferSize(
handle,
CUBLAS_OP_N,
CUBLAS_OP_N,
m,
n,
k,
&alpha,
d_A,
1,
1,
descA,
d_B,
1,
1,
descB,
&beta,
d_C,
1,
1,
descC,
cublas_compute_type,
&workspaceInBytesOnDevice,
&workspaceInBytesOnHost
));
printf("workspaceInBytesOnDevice = %d, workspaceInBytesOnHost = %d\n", workspaceInBytesOnDevice, workspaceInBytesOnHost);
// workspaceを作成、バイトサイズなのでint8で作成
int8_t *d_work = NULL;
cudaMallocAsync(&d_work, workspaceInBytesOnDevice, stream);
std::vector<int8_t> h_work(workspaceInBytesOnHost);
// リソース作成完了を待つ
// waitにはCAL handleとCUDA streamを使ってsync + barrierする
cal_stream_sync(cal_comm, stream);
cal_comm_barrier(cal_comm, stream);
// 時間計測のためにcudaEventを作成
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
// warmup: 初回は内部で初期化が走ることがあるため
CUBLASMP_CHECK(cublasMpGemm(
handle,
CUBLAS_OP_N,
CUBLAS_OP_N,
m,
n,
k,
&alpha,
d_A,
1,
1,
descA,
d_B,
1,
1,
descB,
&beta,
d_C,
1,
1,
descC,
cublas_compute_type,
d_work,
workspaceInBytesOnDevice,
h_work.data(),
workspaceInBytesOnHost
));
// compute: C = alpha AB + beta C
cudaEventRecord(start);
for (int32_t i = 0 ; i < nstep ; ++i)
CUBLASMP_CHECK(cublasMpGemm(
handle,
CUBLAS_OP_N,
CUBLAS_OP_N,
m,
n,
k,
&alpha,
d_A,
1,
1,
descA,
d_B,
1,
1,
descB,
&beta,
d_C,
1,
1,
descC,
cublas_compute_type,
d_work,
workspaceInBytesOnDevice,
h_work.data(),
workspaceInBytesOnHost
));
// nstep回実行した計算の完了を待つ
cal_stream_sync(cal_comm, stream);
cal_comm_barrier(cal_comm, stream);
// 全プロセスが計算を完了した時点までを計算時間として保存して出力
cudaEventRecord(stop);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&milliseconds, start, stop);
if (rank == 0)
printf("cublasMpGemm computation time: %f [sec]\n", milliseconds / 1000.0f / nstep);
cudaEventDestroy(start);
cudaEventDestroy(stop);
cudaMemcpyAsync(h_C.data(), d_C, lldc * loc_n_c * sizeof(output_t), cudaMemcpyDefault, stream);
cal_stream_sync(cal_comm, stream);
cal_comm_barrier(cal_comm, stream);
// cuBLASMpのリソースの破棄
cublasMpMatrixDescriptorDestroy(descA);
cublasMpMatrixDescriptorDestroy(descB);
cublasMpMatrixDescriptorDestroy(descC);
cublasMpGridDestroy(grid);
cublasMpDestroy(handle);
// CUDAリソースの破棄
cudaFreeAsync(d_A, stream);
cudaFreeAsync(d_B, stream);
cudaFreeAsync(d_C, stream);
cudaFreeAsync(d_work, stream);
// CUDA Streamに関連付けた全リソースの破棄を待って、CALリソースを破棄
cal_comm_barrier(cal_comm, stream);
cal_comm_destroy(cal_comm);
cudaStreamDestroy(stream);
MPI_Barrier(MPI_COMM_WORLD);
MPI_Finalize();
}
注意
公開されているドキュメントは https://docs.nvidia.com/cuda/cublasmp/ で閲覧可能ですが、2025年4月26日現在、v0.4.0のドキュメントになっています。
そのため公式のコードサンプルも含め、APIの引数や使い方が異なる可能性がありますのでご注意ください。
例えば、cuBLASMpMutmulはv0.3.0でリリースされています。
行列積の数値型の組み合わせ
各行列 (A, B, C) の数値型は浮動小数点数型と複素数型に加え、8 bit整数が指定可能で、入力行列A, Bと出力行列Cの型は異なるものを選択できる場合があります。
例えばA, Bを16 bit floatで計算し、出力を32 bit floatにすることが可能です。実際の組み合わせは、cublasMpGemmのドキュメントの末尾にあるCUBLAS_COMPUTE_*の説明を参照してください。
ベンチマーク設定
上記のコードを使って、ベンチマークを行います。
行列の入出力型はdouble型で、サイズは以下の通りに設定しました。
m = 8192
n = 4096
k = 8192
今回は2台のA100を使用し、行方向と列方向で2 x 1のプロセス分割に固定します。
あとはBlock-Cyclic分割をどのように行うかですが、行列サイズm, n, kの分割単位 (blocking factor) をそれぞれbm, bn, bkとして以下の組み合わせを試しました。
FP64の行列とすると、1 GiB x 3が全体のメモリサイズになります。
| Block | Cyclic | Block-Cyclic | |
|---|---|---|---|
bm |
8192 | 1 | 2048 |
bn |
4096 | 1 | 1024 |
bk |
8192 | 1 | 2048 |
行列Aについて、各プロセスは8192 x 4096の部分行列を1個 (Block分割)、1 x 1の部分行列を8192 x 4096個 (Cyclic分割)、2048 x 1024の部分行列を4つ持ちます。
Block分割の場合はメモリ上連続した領域1個なので、計算コストが最も低いと思われますが、通信が必要なプロセス間の分割面が一番大きくなります。
Cyclic分割は1 x 1行列として見えるので、計算する場合は飛び飛びの領域にアクセスすることになるためメモリアクセスコストが高いと言えます。
Block-Cyclic分割は2つの中間で、部分行列を複数持つことで計算コストとメモリアクセスコストをバランスします。
密行列の場合はメリットが見えにくいですが、三角行列または対称行列の場合、CyclicとBlock-Cyclic分割は計算負荷を均一化するために有効な手段です。
ベンチマーク結果
以下に行列積1回あたりの計算時間を示します。
計算時間は10回計算したときの平均値で、コードの通り一度warmupした状態で計測しています。
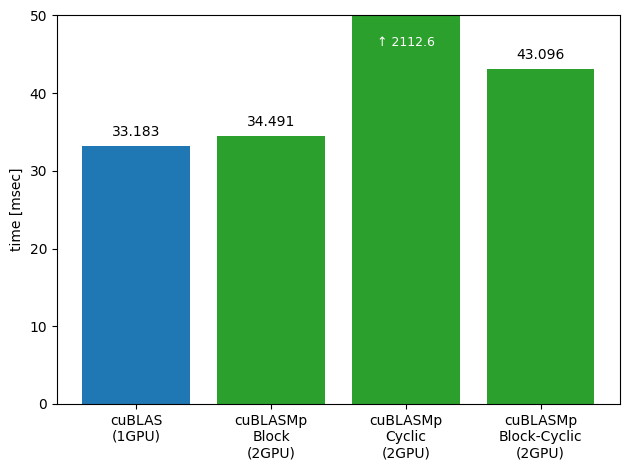
まず、1 GPUに入るメモリサイズではcuBLASMpはcuBLASに速度面で負けている結果となりました。
通信のコストが必要になっている関係で、速度だけで考えればcuBLASの方が適切と考えられ、1 GPUではアプリケーション全体のメモリ使用量が足りない場合に有効と言えそうです。
Cyclic分割はスカラ分散した結果、並列粒度が細かすぎるために性能が全く得られず他の分割方法に比べて2桁遅くなっています。
そのため、グラフはCyclic分割以外にフォーカスしています。
一方で、Block分割では各プロセスは部分行列を1つ持っているので並列化がしやすく、Cyclicに比べ高い性能を得られました。
考慮すべき点としては、cuBLASMpを組み込むアプリケーションで取っている並列化によって最適な利用方法は異なります。
Block分割されているコードについて、cuBLASMpはBlock-Cyclic分割にしようとすると分割方法の変換コストがかかるので、アプリケーション全体で見たときには計算性能は悪くなる可能性が高いです。最適な分割方法と、最適化パラメータの選択が非常に重要といえます。
おわりに
今回はcuBLASMpでの行列積のベンチマークを行いました。
プロセス並列での行列の分割は難しいですが、cuBLASMpはScaLAPACKのマナーに倣っておりほとんどの分が定式化されていて比較的扱いやすいと思われます。
プロセス間通信が必要な計算の並列化は実装が難しいので、cuBLASMpのようなライブラリをうまく活用できると良いと思います。
