キャッシュアーキテクチャを意識したプログラミング ~False Sharingを例に~
はじめに
プロメテックの南です。
今回は、キャッシュアーキテクチャを意識したプログラミングについて解説します。
現代のCPUは処理能力が向上した一方、メインメモリとの性能差が拡大しています。HPCアプリケーションでは大量のデータ処理が必要なため、この性能差が計算時間に影響します。
そこで重要になるのが、CPUのキャッシュシステムおよびそれを意識したプログラミングです。本記事では、OpenMP並列プログラムで頻繁に遭遇するFalse Sharingという現象を例に、キャッシュの動作を実践的に学んでいきます。
実際のプログラムと測定結果を通じて、キャッシュアーキテクチャの基本を体感的に理解していただければと思います。
知っておくべきキャッシュの基本
キャッシュの階層構造
一般的なIntel CPUでは、以下のような構成となっています:
L1キャッシュ: 各CPUコアに専用のキャッシュ
L2キャッシュ: 各CPUコアに専用のキャッシュ(L1より大容量だが低速)
L3キャッシュ: 全CPUコアで共有されるキャッシュ
マルチコア環境において、L1/L2キャッシュは各コアが持っています。もし、同じデータを複数のキャッシュで共有する場合、正しく計算を行うためコヒーレンス(一貫性)を保つ必要があります。
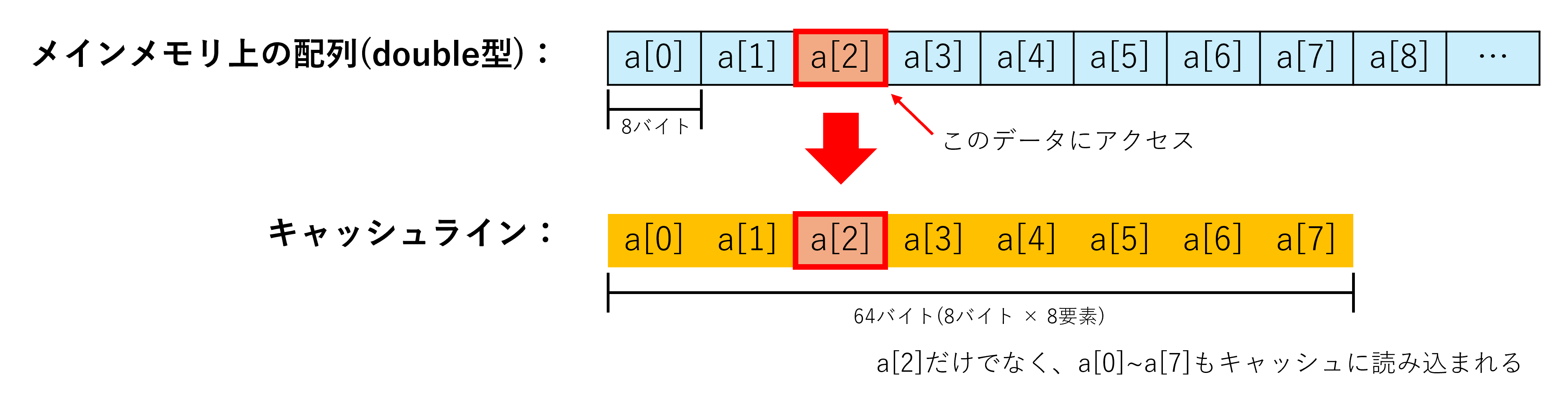
データの管理単位:キャッシュライン
キャッシュは64バイト単位の「キャッシュライン」でデータを管理します。プログラムが1バイトのデータにアクセスしても、その周辺63バイトも一緒にキャッシュに読み込まれます。この仕組みにより、連続したメモリアクセスでは高い効率を得られます。
マルチコアでのキャッシュコヒーレンス
各コアがL1/L2キャッシュを持つため、同じデータが複数のキャッシュに存在する可能性があります。この状況でデータの一貫性を保つため、CPUはMESIプロトコルと呼ばれる仕組みを使用します。
あるコアがキャッシュラインを更新すると、他のコアの同じキャッシュラインは自動的に無効化されます。他のコアがそのキャッシュラインのデータにアクセスが必要な時、下位のメモリ階層(典型的にはメインメモリ)から、再読み込みが必要になります。この無効化と再読み込みが頻繁に発生すると、性能が大幅に低下します。
False Sharingという問題
このようなキャッシュの仕組みが、False Sharingという問題を引き起こします。False Sharingとは、実際にはデータを共有していないにもかかわらず、同じキャッシュラインに配置されたデータへの異なるスレッドからのアクセスにより、キャッシュラインの無効化と再読み込みが繰り返される現象です。
実際のプログラムで体験
実際にFalse Sharingの影響を測定してみましょう。テストプログラムでは、4つのOpenMPスレッドが大量の配列要素を処理し、それぞれの結果を異なる配列要素に足しこんでいく処理を行います。
ソースコードはこちらで公開しています。
★ False Sharing版のコア部分
$ cat worksharing_false_sharing.cpp
...
#pragma omp parallel for num_threads(NUM_THREADS)
for (int i = 0; i < ARRAY_SIZE; i++) {
int tid = omp_get_thread_num();
double val = data[i];
val = std::sin(val) * std::cos(val);
val = std::log(val * val + 1.0);
results[tid] += val; // False Sharing発生
}
...
この例では、各スレッドがresults[tid](tid = 0, 1, 2, 3)に結果を足しこんでいます。results配列の要素は隣接しているため、同じキャッシュライン内に配置されます。
★ シングルスレッド版(ベースライン)
$ g++ -fopenmp -o worksharing_single_thread worksharing_single_thread.cpp -lm
$ ./worksharing_single_thread
...
実行 1: 318.49 ms
実行 2: 318.07 ms
実行 3: 317.44 ms
実行 4: 317.97 ms
実行 5: 316.82 ms
平均実行時間: 317.76 ms
...
★ False Sharing版
$ g++ -fopenmp -o worksharing_false_sharing worksharing_false_sharing.cpp -lm
$ ./worksharing_false_sharing
...
実行 1: 339.99 ms
実行 2: 332.10 ms
実行 3: 331.57 ms
実行 4: 329.20 ms
実行 5: 331.94 ms
平均実行時間: 332.96 ms
...
4つのスレッドで並列化したにも関わらず、シングルスレッド版(317.76ms)とほぼ同じ、むしろ劣化した性能となりました。これがFalse Sharingによる性能低下の実例です。
何が起こっているのか
False Sharingは、異なるデータが同じキャッシュラインに配置されることで発生する性能問題です。
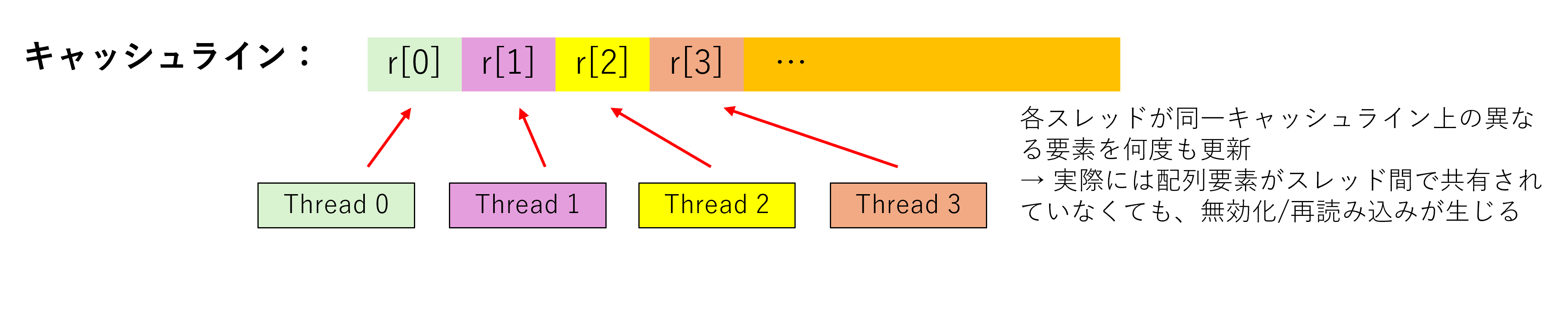
上図のように、double型の配列要素4つ(各8バイト)は1つのキャッシュライン(64バイト)内に収まります。各OpenMPスレッドが異なる配列要素を更新する場合でも、同じキャッシュラインを共有するため、以下の問題が発生します:
1. Thread 0がresults[0]を更新 → Thread 0のキャッシュラインが最新に
2. Thread 1がresults[1]を更新 → Thread 0, 2, 3のキャッシュラインが無効化、Thread 1のキャッシュラインが最新に
3. この繰り返しにより、どのコアが最新データを持つかが頻繁に変わる(キャッシュスラッシング)
キャッシュシステムの理解に基づくFalse Sharingの解決
アライメントによる対策
False Sharingを解決するにはいくつか方法があります。
今回は、キャッシュの動作理解を深めるため、各スレッドが更新するデータを異なるキャッシュラインに配置し、回避してみようと思います。
以下のようにalignasキーワードを使用してキャッシュライン境界(64バイト)にアライメントします。
★ False Sharing解決版のコア部分
$ cat worksharing_no_false_sharing.cpp
...
// 64バイト境界アライメントで偽共有回避
struct alignas(64) AlignedResult {
volatile double value;
char padding[64 - sizeof(double)];
};
AlignedResult results[NUM_THREADS];
...
#pragma omp parallel for num_threads(NUM_THREADS)
for (int i = 0; i < ARRAY_SIZE; i++) {
int tid = omp_get_thread_num();
double val = data[i];
val = std::sin(val) * std::cos(val);
val = std::log(val * val + 1.0);
results[tid].value += val; // 各要素が異なるキャッシュラインに配置
}
...この解決版では、各results[tid]が64バイト境界にアライメントされ、異なるキャッシュラインに配置されます。
解決版の実行結果
$ g++ -fopenmp -o worksharing_no_false_sharing worksharing_no_false_sharing.cpp -lm
$ ./worksharing_no_false_sharing
...
実行 1: 103.03 ms
実行 2: 112.31 ms
実行 3: 99.90 ms
実行 4: 127.46 ms
実行 5: 101.04 ms
平均実行時間: 108.75 ms
...4スレッド並列化によりシングルスレッド比で約3倍の性能向上を実現できました。
perf結果による定量的な確認
さて、上記の修正により性能劣化は解消できましたが、本当にFalse Sharingを解消できているかを定量的に確認してみます。
perfツールを使用してキャッシュミスの詳細を確認してみます。ここで測定する項目は以下の通りです:
cache-references: キャッシュ参照数
cache-misses: (LLCでの)キャッシュミス数
L1-dcache-load-misses: L1データキャッシュでの読み込みミス数
★ False Sharing版
$ perf stat -e cache-misses,cache-references,L1-dcache-load-misses ./worksharing_false_sharing
...
Performance counter stats for './worksharing_false_sharing':
13,265,649 cache-misses # 7.442 % of all cache refs
178,263,558 cache-references
116,897,889 L1-dcache-load-misses
2.347240674 seconds time elapsed
...
★ False Sharing解決版
$ perf stat -e cache-misses,cache-references,L1-dcache-load-misses ./worksharing_no_false_sharing
...
Performance counter stats for './worksharing_no_false_sharing':
13,218,319 cache-misses # 94.772 % of all cache refs
13,947,476 cache-references
20,706,429 L1-dcache-load-misses
0.915673058 seconds time elapsed
...
False Sharing版のcache-referencesは178M回と非常に多くなっています。これは、False Sharingによりキャッシュラインが頻繁に無効化され、下位のキャッシュ参照が増加するためと考えられます。解決版では13.9M回と約13分の1に減少しており、アライメント対策が有効に機能していることが分かります。
同様に、L1-dcache-load-missesもFalse Sharing版では117M回と非常に多くなっています。False Sharingによるキャッシュラインの無効化により、L1キャッシュからのデータが失われるためです。解決版では20.7M回と約5.6分の1に減少しており、この点からもアライメント対策が機能していることが確認できます。
また、cache-missesは大きな差がありません。これは、cache-missesがLLCキャッシュ(L3)でのミス、つまり実際のメインメモリアクセス回数を表しているためと考えられます。False Sharingが発生しても、無効化されたデータは下位のキャッシュ階層(L2やL3)に残っていることが多く、最終的なメインメモリアクセス量は変わらなかったと考えられます。したがって、今回の性能低下は、L1キャッシュでの頻繁な無効化と再読み込みによるものであったと言えそうです。
まとめ
本記事では、キャッシュアーキテクチャを意識したプログラミングについて、False Sharingを例として解説いたしました。キャッシュラインという64バイト単位の管理やマルチコア間のコヒーレンス制御を、実際のプログラムとperf測定を通じて体感的に理解いただけたのではないでしょうか。キャッシュシステムの動作は普段見えませんが、このような具体的な現象を通じて学ぶことで、キャッシュアーキテクチャへの理解が深まれば幸いです。
より深く学びたい方へ
今回はFalse Sharingを通じてキャッシュの基本的な動作を学びましたが、キャッシュアーキテクチャには多くの要素があります。より深く学びたい方は、以下のキーワードを調べてみてください。
キャッシュ構造の詳細
- セットアソシアティブ(Direct-mapped、Fully associative との比較)
- キャッシュ置換アルゴリズム(LRU、Random、FIFO)
- Write-back vs Write-through ポリシー
性能最適化技法
- データレイアウト最適化(AoS vs SoA)
- キャッシュブロッキング(ループタイリング)
- プリフェッチ(ハードウェア/ソフトウェア)
