OpenACCでのマルチGPU計算の制御
はじめに
CUDA Streamを用いた並行処理では、OpenACC asyncの実装に用いられているCUDA Streamの動きを説明しました。
OpenACC asyncは、通常は計算とメモリ転送をオーバーラップするlatency hidingの用途を想定しているようで、Single GPUにおいて複数のカーネルを同時に実行するのは限定的です。
一方で、複数GPUを容易に制御する手段としては期待できそうです。今回は複数GPUを1つのプログラムから扱うときの制御について考えます。
複数GPUの制御方法
OpenACC asyncを使用せずに1つのプログラムで複数のGPUを制御する場合、いくつかの選択肢があります。
- 逐次的にそれぞれのGPUを制御する
- OpenMPやPOSIX Threadを使ってスレッドにGPUを紐づける
- MPIを使ってプロセスにGPUを紐づける
GPUで計算しようとしているプログラムがすでにMPIで実装されている場合に3は最も簡単なやり方ですが、今回は割愛します。
CUDAで複数のGPUを同時に制御する場合、メモリやストリームなどのコンテキスト情報が各GPU(デバイスとします)によって異なることから、制御対象とするGPUを明示的に指定する必要があります。
OpenACCの場合、acc_set_device_num(device_id, acc_device_nvidia)を使います。第2引数は制御対象のデバイス種別ですが、ここではacc_device_nvidiaはCUDA GPUを指定します。
device_idは0番から、計算ノードやワークステーションに接続されているGPUの台数-1までの範囲で指定します。
逐次的に制御
最も簡単にはデバイス台数でループを回し、各ループでGPUを切り替え計算カーネルを実行し複数GPUを扱います。
#include <stdio.h>
#include <assert.h>
#include <openacc.h> /* acc_set_device_num, acc_get_num_devices */
int main() {
const int n_devices = acc_get_num_devices(acc_device_nvidia);
assert(n_devices > 0);
const int n = 16;
double x[n_devices][n], y[n_devices][n];
double a = 0.5;
for (int i = 0 ; i < n_devices ; ++i)
for (int j = 0 ; j < n ; ++j) {
x[i][j] = i * n + j;
y[i][j] = 0;
}
for (int i = 0 ; i < n_devices ; ++i) {
acc_set_device_num(i, acc_device_nvidia);
/* runs on device{i} */
#pragma acc kernels
for (int j = 0 ; j < n ; ++j)
y[i][j] = a * x[i][j] + y[i][j];
}
for (int i = 0 ; i < n_devices ; ++i)
for (int j = 0 ; j < n ; ++j)
printf("%lf\n", y[i][j]);
return 0;
}
スレッドにGPUを割り当てる
各スレッドで使うGPUを切り替えます。デバイス台数分のスレッドを起動し、スレッドID = デバイスIDと対応付けして制御するのが簡単です。
先程のコードでは、acc_set_device_numを呼び出すループをOpenMPで並列化し容易に実現可能です。
...
#pragma omp parallel for
for (int i = 0 ; i < n_devices ; ++i) {
/* runs on thread{i} */
acc_set_device_num(i, acc_device_nvidia);
/* runs on device{i} */
#pragma acc kernels
for (int j = 0 ; j < n ; ++j)
y[i][j] = a * x[i][j] + y[i][j];
}
...
コンパイルする際は、OpenMPとOpenACC両方を有効にする必要があります。
$ nvc++ -mp -acc ./multi_gpu.cc
OpenACC asyncを使った制御
逐次制御では複数GPUを扱えてはいますが、ある瞬間を切り取ってみると計算をしているGPUは常に1台なので、計算時間の短縮は行えていません。
一方、OpenMPで並列化する場合は各スレッドが独立動作し複数GPUを同時並行で利用できていますが、スレッド間での変数の管理がやや不便です。
またOpenMPとOpenACCを併用するため、並列化順序を間違えると原因が分かりづらいバグが発生しやすくなります。
OpenACCはループ処理やメモリコピー処理は同期処理ですが、asyncを使って非同期処理として扱うことが可能です。
この機能を使って、先のコードでOpenMPを使わずに複数GPUの同時利用を可能にできます。
omp parallel forを入れる代わりに、以下のようにコードを編集します。
...
for (int i = 0 ; i < n_devices ; ++i) {
acc_set_device_num(i, acc_device_nvidia);
/* runs on device{i} */
#pragma acc kernels async(1)
for (int j = 0 ; j < n ; ++j)
y[i][j] = a * x[i][j] + y[i][j];
}
/* do something... */
/* wait all devices */
for (int i = 0 ; i < n_devices ; ++i) {
acc_set_device_num(i, acc_device_nvidia);
acc_wait(1);
}
...
複数GPUで同時に計算を走らせることが可能になり、かつdo something...と書いた場所ではGPUに関係ない処理を非同期で処理できるようになりました。
分散並列化する場合のメモリの扱い
1つの計算を複数のGPUで分割して行う場合(分散並列化)、入力や出力はそのGPUが持つメモリに置かなければいけません。
例えば長さnのベクトルを2つのGPUで分割計算する場合、それぞれのGPUはn/2の部分ベクトルが自身のメモリ上に格納されている必要があります。
OpenACCで実現する場合、acc_set_device_numを使ってデバイスを切り替え、acc enter/exit data節などを使ってメモリ確保とデータ転送を行います。
しかしdata ownershipの管理は非常に複雑で、最新のデータがCPUとGPUどちらにあるかだけでなく、どのGPUにあるかまで考える必要が出てきます。
Unified/Managed memoryはCPU <-> GPU間だけでなく、同じ計算ノード/ワークステーションに接続されているGPU間も自動的にメモリ転送のやりとりが可能です。
今回のようなマルチGPUプログラムの場合、基本的にはManaged memoryの利用を推奨します。
行列積で同時利用ができているか確かめる
行列積AB = Cを計算し、本当に複数GPUを同時利用できているか検証してみます。
Aを2分割して2つのGPUにそれぞれ割り当て、Cを求めます。本来は各GPUへそれぞれメモリ転送をする必要がありますが、ここではManaged memoryを使って転送処理を省略します。
#include <iostream>
#include <vector>
#include <openacc.h>
void dgemm_async( int queue_id
, int n
, int m
, int k
, double const* A // [n, k]
, double const* B // [m, k]
, double * C // [n, m]
){
// A, B, Cはすでにメモリ確保とデータ転送が終わっている
#pragma acc kernels async(queue_id) present(A, B, C)
#pragma acc loop independent gang worker
for (int i = 0 ; i < n ; ++i) {
#pragma acc loop independent vector
for (int j = 0 ; j < m ; ++j) {
double v = 0.0;
for (int l = 0 ; l < k ; ++l) {
v += A[i * k + l] * B[j * k + l];
}
C[i * m + j] = v;
}
}
}
int main() {
constexpr int n = 8192;
std::vector A(n * n), B(n * n), C(n * n, -0.1);
for (int i = 0 ; i < n; ++i)
for (int j = 0 ; j < n ; ++j) {
A[i * n + j] = double(i * n + j + 1) / n;
B[j * n + i] = A[i * n + j] * -1;
}
double *rA = A.data(), *rB = B.data(), *rC = C.data();
/* runs on device0 */
acc_set_device_num(0, acc_device_nvidia);
dgemm_async(0, n/2, n, n, rA, rB, rC);
/* runs on device1 */
acc_set_device_num(1, acc_device_nvidia);
dgemm_async(1, n/2, n, n, rA + (n / 2) * n, rB, rC + (n / 2) * n);
/* wait device 0 */
acc_set_device_num(0, acc_device_nvidia);
acc_wait(0);
/* wait device 1 */
acc_set_device_num(1, acc_device_nvidia);
acc_wait(1);
if (n <= 8)
for (int i = 0 ; i < n; ++i) {
for (int j = 0 ; j < n ; ++j)
std::cout << C[i * n + j] << " ";
std::cout << std::endl;
}
}
コンパイル方法は以下です。
nvc++ -acc -gpu=managed gemm_async.cc
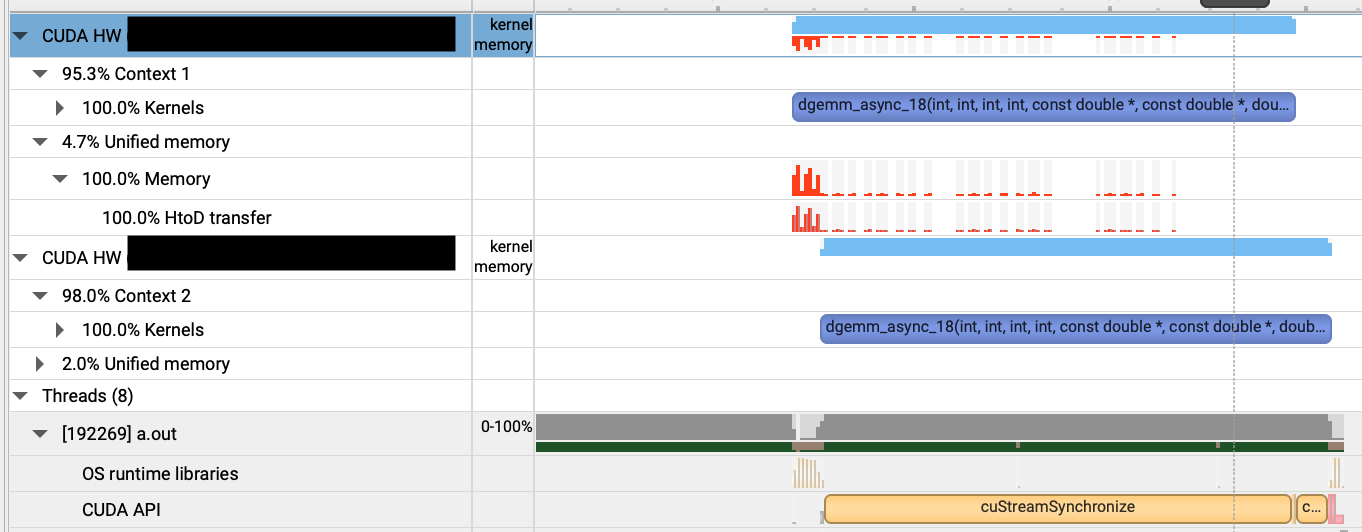
Nsight Systems (nsys) を使ってプロファイルを取ってみると、以下のように行列積のカーネルが同時に2つのGPUで処理されていることがわかります。
2つ目のカーネルの実行が遅れていますが、これは1つ目のカーネルとCPUからGPUへのメモリコピーが同時に走っていることから、メモリコピー待ちのようです。
また、以下のようにOpenMPを使った非同期呼び出しでも同じように同時並行的に処理されるのが確認できます。
...
#pragma omp parallel num_threads(2)
{
const int tid = omp_get_thread_num();
if (tid == 0) {
// device0
acc_set_device_num(0, acc_device_nvidia);
dgemm_async(0, n/2, n, n, rA, rB, rC);
acc_wait(0);
}
else if (tid == 1) {
// device1
acc_set_device_num(1, acc_device_nvidia);
dgemm_async(1, n/2, n, n, rA + (n / 2) * n, rB, rC + (n / 2) * n);
acc_wait(1);
}
}
...
まとめ
1つのプログラム上で複数のGPUを同時に使う方法として、逐次的に扱う、OpenMPで並列利用する、OpenACC asyncで非同期的に扱う、の3つを紹介しました。
複数のGPUを使う場合、効率的に計算 = 計算時間を短縮する、にはOpenMPやasyncを使って同時並行的に利用する手段が必要です。
ループを複数GPUで分割計算する場合、OpenMPでの分散並列化は非常に書きやすいと思われます。
一方、後半に紹介したような計算範囲を細かく設定したり、GPUごとにまるで違う計算をする場合は実装が複雑になり苦手な処理といえます。
OpenACCで実装を閉じたい、異なる処理をGPUに別々に割り当てる場合はOpenACC asyncを使うなどの使い分けができそうです。
まずは簡単にマルチGPU化したい、という場合はUnified memory + OpenACC asyncをおすすめします。
