N体問題アプリケーションのOpenACCとCUDAの実装: 性能と作業コストの比較
はじめに
プロメテックの南です。
以前行われた「GPUプログラミング勉強会」では、
OpenACCを用いてプログラムをGPU化するテクニックや、実際にN体問題への適用例を紹介しました。
今回は、新たにN体問題のCUDA実装の性能を紹介します。
一般に、CUDAは性能面での優位性がある一方で、OpenACCは低い作業コストでGPUアクセラレーションを実現できる利点があります。
本コラムでは、OpenACC・CUDAの性能の違いだけでなく、作業コストという観点からも評価し、開発者や研究者の方々が最適な選択をするためのヒントを提供します。
本コラムでは、N体問題やその数値計算方法については深入りしません。詳しくは、本記事末尾の出典*より母体コードを参照ください。
OpenACCによるGPUプログラム実装
N体問題のOpenACCプログラムを示します。
時間ループ全体と、GPU化部分の実装部分です。
...
while (t < endtime) // 時間積分ループ
{
compute_force(particles, forces); // GPU計算部分① 粒子間の力計算
#pragma acc kernels loop independent // GPU計算部分② 速度&移動計算
for (int i = 0; i < nparticles ; ++i) {
struct Particle* p = &particles[i]; double *force = &forces[3 * i];
// Now the positions of the particles will be calculated based // on the Leapfrog method ("kick-drift-kick")
// Kick
p->velocity[0] += force[0] * (dt/2) / p->mass;
p->velocity[1] += force[1] * (dt/2) / p->mass;
p->velocity[2] += force[2] * (dt/2) / p->mass;
// Drift
p->position[0] += p->velocity[0] * dt;
p->position[1] += p->velocity[1] * dt;
p->position[2] += p->velocity[2] * dt;
}
compute_force(particles, forces); // GPU計算部分① 粒子間の力計算
#pragma acc kernels loop independent // GPU計算部分③ 速度計算
for (int i = 0; i < nparticles ; ++i) {
struct Particle* p = &particles[i]; double *force = &forces[3 * i];
// Kick
p->velocity[0] += force[0] * (dt/2) / p->mass;
p->velocity[1] += force[1] * (dt/2) / p->mass;
p->velocity[2] += force[2] * (dt/2) / p->mass;
}
t += dt;
iteration += 1;
...
}
// Calculate forces
void compute_force(struct Particle* particles, double* forces) // GPU計算部分① 粒子間の力計算
{
#pragma acc kernels
for (int i = 0; i < nparticles ; ++i)
{
double sum_fx, sum_fy, sum_fz;
sum_fx = 0.0; // forces[3 * i + 0] = 0.0;
sum_fy = 0.0; // forces[3 * i + 1] = 0.0;
sum_fz = 0.0; // forces[3 * i + 2] = 0.0;
for (int j = 0; j < nparticles ; ++j)
{
// We are computing the force on particle i due to particle j.
// (dx, dy, dz) is the vector pointing from particle i to particle
// j: this is the direction of the force.
double G = GRAVITATIONAL_CONSTANT;
double rs = SOFTENING_LENGTH;
double dx = particles[j].position[0] - particles[i].position[0];
double dy = particles[j].position[1] - particles[i].position[1];
double dz = particles[j].position[2] - particles[i].position[2];
double r2 = dx * dx + dy * dy + dz * dz;
double invr3;
invr3 = pow(r2 + rs * rs, -1.5);
double mj = particles[j].mass;
double fx = dx * G * mj * invr3;
double fy = dy * G * mj * invr3;
double fz = dz * G * mj * invr3;
sum_fx += fx ; // forces[3 * i + 0] += fx;
sum_fy += fy ; // forces[3 * i + 1] += fy;
sum_fz += fz ; // forces[3 * i + 2] += fz;
}
forces[3 * i + 0] = sum_fx;
forces[3 * i + 1] = sum_fy;
forces[3 * i + 2] = sum_fz;
}
}
主なGPU化部分は、上記コード中に記載の通り、
① 粒子間の力計算
② 速度&移動計算
③ 速度計算
の三か所になります。
次章以降では、これらをCUDA化していきます。
OpenACCとCUDAのGPU並列化手順の違い
一般に、GPUプログラミングでは、既にCPUで動作する(並列)プログラムがあり、それをGPU化します。したがって、下記のような手順を取ることが多いです。
作業1. 既存のCPUコードから並列化可能箇所(~既に並列化された箇所)を抽出
作業2. GPU並列化実装
作業3. 計算結果の確認
(作業4. 性能チューニング)
このうち、OpenACCとCUDAでは作業2. GPU並列化実装 の部分が大きく異なります。
OpenACCではディレクティブを追加するだけで、GPUプログラムを作成できます。
一方、CUDAは、一般に自由度/柔軟性の高い方法であり、並列化方法を設計したうえで、プログラムを書き直す必要があります。
CUDAによるGPUプログラム実装
本章では、既存のOpenACCプログラムから、CUDAプログラムを作成する手順を簡単に示します。
CUDAは、先に説明した通り、まず、並列化方法を設計する必要があります。
本コラムでは、この設計を簡略化し、OpenACCと同様の並列化を実装することにします。
この場合、以下のような手順を取ります。
OpenACCプログラムの並列化方法の確認
先ほど示したOpenACCのコードをコンパイルするとOpenACCプログラムの並列化方法や実行コンフィグレーションの情報が得られます。
$ make test-z
nvc -acc -fast -Minfo=accel -o main_dataallgpu_alc_fix.exe main_dataallgpu_alc_fix.c
compute_force:
39, Generating implicit copy(forces[:nparticles*3]) [if not already present]
Generating implicit copyin(particles[:nparticles]) [if not already present]
41, Loop is parallelizable
Generating NVIDIA GPU code
41, #pragma acc loop gang /* blockIdx.x */
48, #pragma acc loop vector(128) /* threadIdx.x */
Generating implicit reduction(+:sum_fz,sum_fy,sum_fx)
48, Loop is parallelizable
...
main:
136, Generating copyin(forces[:nparticles*3],particles[:nparticles]) [if not already present]
141, Loop is parallelizable
Generating implicit private(force,p)
Generating NVIDIA GPU code
141, #pragma acc loop gang, vector(128) /* blockIdx.x threadIdx.x */
163, Loop is parallelizable
Generating implicit private(p,force)
Generating NVIDIA GPU code
163, #pragma acc loop gang, vector(128) /* blockIdx.x threadIdx.x */
コンパイルメッセージ中の太字の部分に着目すると、
① 粒子間の力計算(compute_force)は、1次元グリッド1次元ブロックで並列化されていることが分かります。2次元ループの外側をブロック並列化、内側をスレッド並列化しています。
② 速度&移動計算、 ③ 速度計算は1次元グリッド1次元ブロックで並列化されていることが分かります。この場合、ブロック数は1であるため、1次元ループをスレッド並列化していることが分かります。
CUDAプログラムの実装
前節を踏まえてCUDA実装したプログラムは以下となります。
...
dim3 grid(NUM_PARTICLES);
dim3 block(128);
while (t < endtime)
{
compute_force_gpu <<<grid, block, sizeof(double) * 3 * 128>>>(nparticles, dt, d_particles, d_forces); // ① 粒子間の力計算
cudaDeviceSynchronize();
kick_n_drift <<<grid, block>>>(nparticles, dt, d_particles, d_forces); // ② 速度&移動計算
cudaDeviceSynchronize();
compute_force_gpu <<<grid, block, sizeof(double) * 3 * 128>>>(nparticles, dt, d_particles, d_forces); // ① 粒子間の力計算
cudaDeviceSynchronize();
kick <<<grid, block>>>(nparticles, dt, d_particles, d_forces); // ③ 速度計算
cudaDeviceSynchronize();
t += dt;
iteration += 1;
...
}
// ① 粒子間の力計算
// Calculate forces
__global__ void compute_force_cuda(int nparticles, double dt, struct Particle* particles, double* forces)
sum_forces)
{
unsigned int ix = blockIdx.x;
unsigned int jx = threadIdx.x;
extern __shared__ double sums[];
double G = GRAVITATIONAL_CONSTANT;
double rs = SOFTENING_LENGTH;
if (jx < nparticles)
{
// We are computing the force on particle i due to particle j.
// (dx, dy, dz) is the vector pointing from particle i to particle
// j: this is the direction of the force.
double dx = particles[jx].position[0] - particles[ix].position[0];
double dy = particles[jx].position[1] - particles[ix].position[1];
double dz = particles[jx].position[2] - particles[ix].position[2];
double r2 = dx * dx + dy * dy + dz * dz;
double invr3;
invr3 = pow(r2 + rs * rs, -1.5);
double mj = particles[jx].mass;
double fx = dx * G * mj * invr3;
double fy = dy * G * mj * invr3;
double fz = dz * G * mj * invr3;
sums[3 * jx + 0] = fx;
sums[3 * jx + 1] = fy;
sums[3 * jx + 2] = fz;
} else
{
sums[3 * jx + 0] = 0.0;
sums[3 * jx + 1] = 0.0;
sums[3 * jx + 2] = 0.0;
}
__syncthreads();
for (int s = 1; s < blockDim.x; s *= 2) {
if ((jx % (2 * s)) == 0) {
sums[3 * jx + 0] += sums[3 * (jx + s) + 0 ];
sums[3 * jx + 1] += sums[3 * (jx + s) + 1];
sums[3 * jx + 2] += sums[3 * (jx + s) + 2];
}
__syncthreads();
}
forces[3 * ix + 0] = sums[0];
forces[3 * ix + 1] = sums[1];
forces[3 * ix + 2] = sums[2];
}
// ② 速度&移動計算
__global__ void kick_n_drift (int nparticles, double dt, struct Particle* particles, double* forces)
{
unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x;
if (ix < nparticles) {
struct Particle* p = &particles[ix]; double *force = &forces[3 * ix];
// Now the positions of the particles will be calculated based
// on the Leapfrog method ("kick-drift-kick")
// Kick
p->velocity[0] += force[0] * (dt/2) / p->mass;
p->velocity[1] += force[1] * (dt/2) / p->mass;
p->velocity[2] += force[2] * (dt/2) / p->mass;
// Drift
p->position[0] += p->velocity[0] * dt;
p->position[1] += p->velocity[1] * dt;
p->position[2] += p->velocity[2] * dt;
}
}
// ③ 速度計算
__global__ void kick (int nparticles, double dt, struct Particle* particles, double* forces)
{
unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x;
if (ix < nparticles) {
struct Particle* p = &particles[ix]; double *force = &forces[3 * ix]; // Kick p->velocity[0] += force[0] * (dt/2) / p->mass;
p->velocity[1] += force[1] * (dt/2) / p->mass;
p->velocity[2] += force[2] * (dt/2) / p->mass;
}
}
OpenACCとCUDAの性能比較
以下に性能を示します。比較に用いたGPUは、NVIDIA Quadro GV100です。
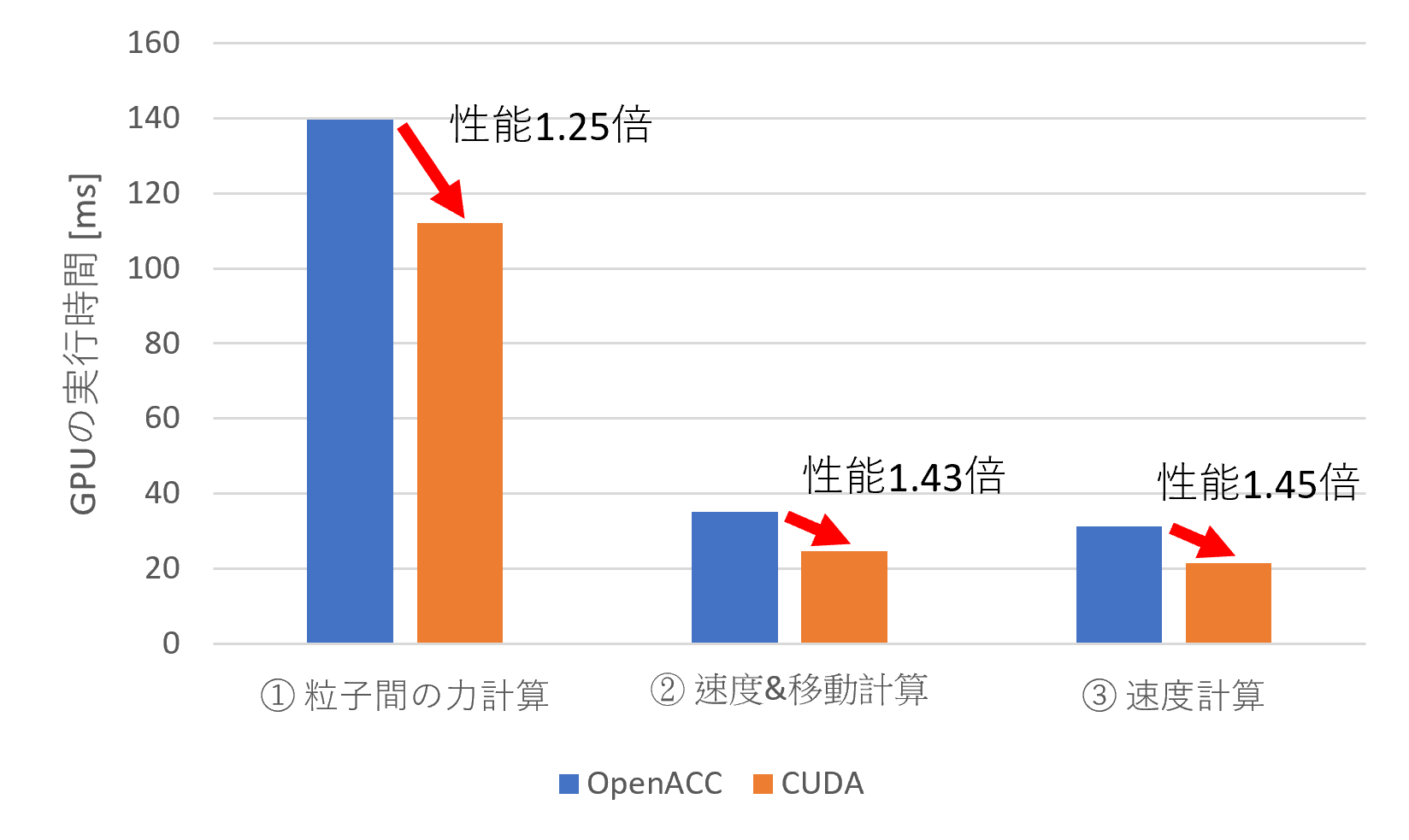
GPU化した3つの部分は、CUDA実装が1.25~1.45倍程度速いことを確認できます。
OpenACCから見ると、CUDA実装の70 ~ 80%の性能を実現できています。
GPU化作業コストの比較
先に示したように、プログラムのGPU化は以下の要素からなります。
本章では、作業2. GPU並列化実装 について、作業コストを評価します。
作業1. 既存のCPUコードから並列化可能箇所(~既に並列化された箇所)を抽出
作業2. GPU並列化実装
作業3. 計算結果の確認
(作業4. 性能チューニング)
本コラムでは、並列化方法をゼロから考えるのではなく、OpenACCと合わせることで楽をしました。作業としては以下のようになります。
作業2. GPU並列化実装
├ 既存OpenACCプログラムの並列化方法の確認(通常はこれが並列化方法の設計に相当)
└ CUDAプログラムの書き換え
今回の母体となるプログラムは200行弱で、上記の作業2. に私1人で約2~3時間程度かかりました。
一方で、OpenACCで作業2. を行うとすると、長く見積もっても30分程度の試行錯誤でGPUで性能向上するプログラムが作成できるかと思います。
もちろんこれらの値は、対象となるプログラムの規模や複雑さ、作業人数などに大きく依存しますので参考程度となりますが、両手法の作業量について一つの目安にはなると考えます。
まとめ
N体問題プログラムのGPU化を通して、OpenACCとCUDAにおける性能と作業コストについて紹介いたしました。両者の違いを理解することで、GPU化手法の選択のヒントとなれば幸いです。
出典
NSimX
(本コラムおよびGPUプログラミング勉強会にて使用したN体問題コード)
NSimX CUDA
(本コラムで紹介したCUDA実装)
