OpenACC ディレクティブによるプログラミング
1章 アクセラレータを利用したコンピューティング
アクセラレータとは?
コンピューティング環境における「アクセラレータ」とは、一般に処理能力を向上させるためのハードウェアやソフトウェアのことを意味するが、特にハードウェアの場合は CPU の処理を代替し処理の効率を向上させる装置(デバイス)を指す。ここで言う「処理効率を向上させる」手法は、そのほとんどが「並列処理」によるスループットの高速化である。HPCのプログラムを対象として見た場合、ループ構造を有した処理部分を並列処理により高速化することを目的とした装置がアクセラレータである。2013年現在、こうした機能を提供するものとして、NVIDIA社の GPU や Intel社の Xeon Phi、AMD社の APU or GPU などが相当する。これら装置(デバイス)のアーキテクチャはそれぞれ異なるが、計算処理の重い部分を CPU に代わって高速に処理させること(こうした処理を「オフロード offload」と称する。)を目的にしていることは共通である。以下に示した図は、NVIDIA GPU 装置を PCIバスで PC に接続した際の CPU と GPU 間のブロック図を示したものである。図の左側の点線枠線内の CPU と図の右側に配した NVIDIA の GPU は、PCI バス経由で接続された形態となっている。Intel社の Xeon Phiも、アクセラレータ・デバイス内部のアーキテクチャは異なるが、PCIバスで接続されていると言う意味では共通な構造を持つ。
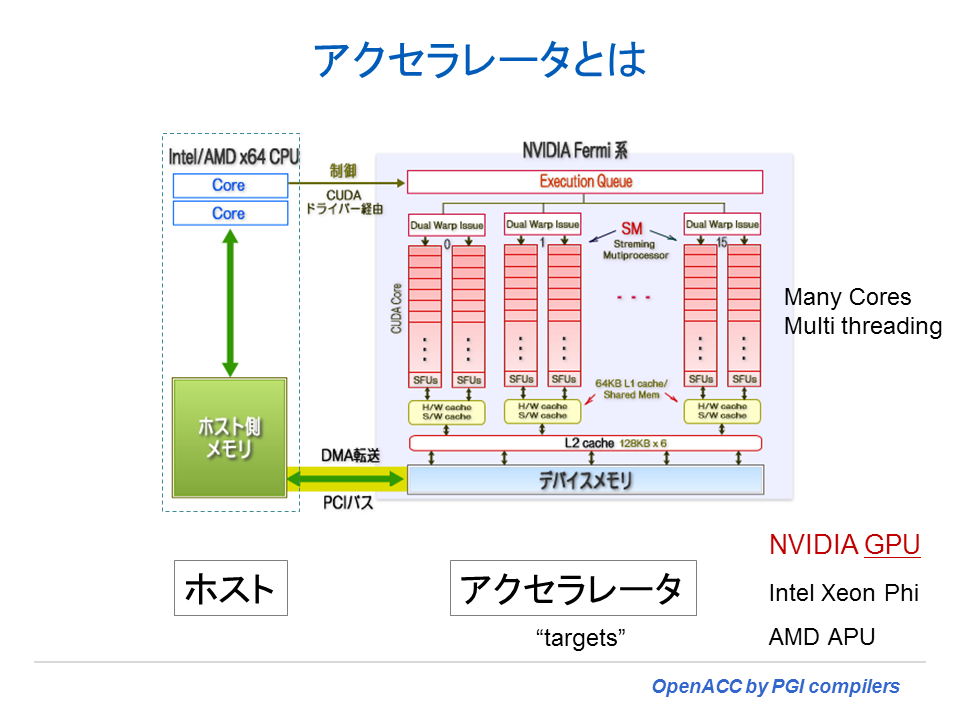
「CPU」と「アクセラレータ」の違いは?
「CPU」と「アクセラレータ(GPU)」の構造的な違いを纏めたよい資料がある。PGI の Michael Wolfe の資料(*1) をもとに、性能に関与する構造上の違いを以下の表に表した。「アクセラレータ(GPU)」は、その動作周波数はきわめて低く、スカラ処理する際のベース性能はCPUに比べて低いことが分かる。その代わりに、大量のコアプロセッサを用いて、SIMD(ベクトル)処理と MIMD 並列処理の両方を行って性能を稼ぐ方法をとっている。プロセッサの構成も CPU に比べて単純であり高度な分岐予測等は行わず in-order で実行処理を行い、命令処理のストールを隠蔽するために、多重のマルチスレッディング実行ができるようになっている。すなわち、こうしたアクセラレータ上では、SIMD(ベクトル)処理と並列処理が可能なプログラムが、その本来有している高い性能を享受することが出来る。
| CPU | アクセラレータ(GPU) | |
|---|---|---|
| 基本的な性能のベースとなる動作周波数 | ||
| 高速クロック周波数 (2.5~3.5GHz) | > | 低速クロック周波数 (0.8~1.0GHz) |
| クロック当たりの命令実行を増やす工夫 | ||
| パイプライン (深い) | パイプライン(浅い) | |
| Multiscalar (3-4) | > | Multiscalar (1-2) |
| SIMD命令当たりの処理数 (4-16) | < | SIMD命令当たりの処理数 (16-64) |
| プロセッサコア数 (6-12) | < | プロセッサコア数 (15-32) |
| 命令実行のストール(wait)を少なくする工夫 | ||
| 大きなキャッシュメモリ搭載 | > | 小さなキャッシュメモリ搭載 |
| 高度な分岐予測 | > | - |
| Out-of-order execution | > | In-of-order execution |
| マルチスレッディング (2-4) | < | マルチスレッディング (15-32);大量のレジスタ数 |
GPU プログラミングを行う上で、NVIDIA GPU の構造、特に、スレッドの処理単位やベクトル処理の方法に関して書いた拙著「NVIDIA GPU の構造と CUDA スレッディングモデル」は、2010 年に書いたものであるが、GPUの基本的な構造はあまり変わらないため、一読していただくと今後の参考になるかもしれない。
現在のアクセラレータ・デバイス
2013年末における「アクセラレータ・デバイス」として、NVIDIA社の GPU、Intel社の Xeon Phi、AMD社の Radeon GPU が市場に流通している。ユーザが使用するプログラミングモデルとしては、これらの異機種デバイス上で大きなプログラム変更無しに使用できるものが理想である。その解は、実は、これから説明する OpenACC である。これら三社のデバイスは、今後、同じマーケットにおいて競い合うものと思われるが、これらのデバイスの特徴を簡単にまとめてみる。
NVIDIA Kepler
- 15 SMXユニット、192 単精度GPUコア/SMX、トータル 2880 単精度GPUコア
- SIMD: 32-wide SIMD 処理(この単位を warp と言う)2サイクルで 32-wide SIMD処理
- 1 SMX には、単精度 32 CUDA core が 6組、倍精度浮動小数点(DP unit) 2組
- 1 SMX は 64 threads までの状態を保持できる、In-order Instruction issue
- SMXの動作クロックは、0.8~1.0 GHz、最大 6 GBメモリ
Intel Xeon Phi Coprocessor
- 最大61コア、x86命令セットの実行、976 単精度GPUコアに相当する
- 1 コア当たり 512-bit vector 命令可能
- 単精度 16 ベクトル処理、倍精度 8 ベクトル処理可能、Gather/Scatter命令有り
- 1 コアは 4 threads までの状態を保持できる、In-order Instruction issue
- 動作クロックは、1.1 GHz、最大 8 GB メモリ
AMD Radeon GPU
- 32~44 CU(Compute Unit)ユニット、64 SIMD unit/CU 、トータル 2048~2816 単精度GPUコア
- SIMD: 64-wide SIMD 処理(この単位を wavefront と言う)単精度は4サイクルで 64-wide SIMD処理、倍精度は16サイクルで 64-wide
- 1 CU には、4 組の 16-wide SIMD unit を実装、
- 1 SIMD unitは 10 threads までの状態を保持できる、In-order Instruction issue
- 動作クロックは、1.0 GHz、最大 4GB メモリ
アクセラレータ用のプログラミングモデル
このアーキテクチャで特徴的なことは、以下の点である。
- CPUのメモリ空間とアクセラレータ・デバイスのメモリ空間が異なること
- 一般的なメモリ帯域幅に比べて低速な PCI バスで接続されていること
このような構成の上でプログラミングを行うことを想定してみよう。ある重い処理をアクセラレータ・デバイス(以下、「デバイス」とも言う。)側で処理をしようとした場合、CPU 側に存在する必要なデータをデバイス側にコピーし、処理が終わった後に、CPU 側に戻すと言うハンドリングが必要となる。また、これと関連して、両者のメモリ空間が異なるため、一つのプログラム内で単一アドレス空間でのメモリアクセスが出来ない(あるいは同じ変数名が使用できない)ことにより、プログラミングの難易度が増すと言った欠点がある。
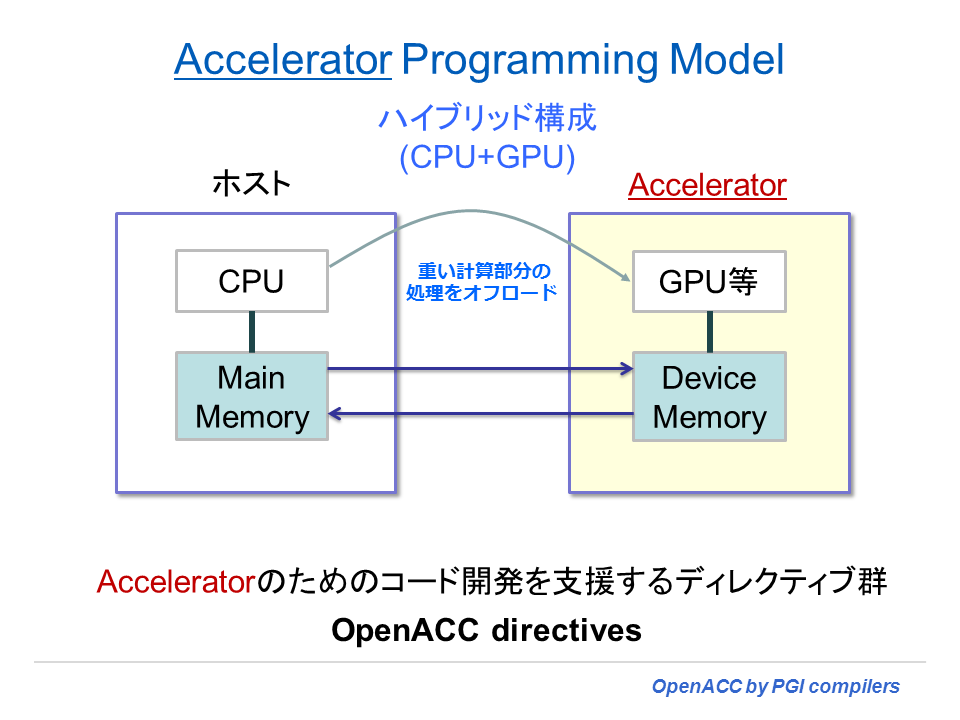
こうしたプログラミング上の問題を出来る限り吸収し、例えば、NVIDIA のネイティブな CUDA 言語よりも簡単に、さらに従来の高級言語によるプログラムの中にコンパイラ・ディレクティブを挿入するだけで、アクセラレータ(デバイス)コードを生成出来るようにしたものが OpenACC プログラミング仕様である。現在、一番成功したと言われる共有メモリアーキテクチャに対する「並列プログラミングモデル」である OpenMP と同じ手法を踏襲したものと考えて良い。OpenACC プログラミングモデルの原型は、PGI が 2008年に提唱した PGI Accelerator Programming Model であり、2009年11月に PGIアクセラレータコンパイラとしてその実装形を市場に提供した。その後、2011年11月に、PGI は、NVIDIA社、Cray社、CAPS社と共に、OpenACC API 1.0 仕様書を定義し、現在、OpenACC 対応のコンパイラを提供している。さらに、2013 年 7 月に OpenACC 2.0 の標準仕様を発表し、その実装コンパイラが 2013 年末から 2014 年の始めに各社から提供されることとなっている。OpenACC は、下図のように 「CPU+アクセラレータ」のハイブリッド構成に対するプログラミングモデルであり、CPU処理をオフロードしデバイス側で処理するためのコード開発を支援するディレクティブ群と理解して良い。また、もう一つの仕様として2013年7月に、New OpenMP 4.0 の中の機能としてアクセラレータデバイス構文(target 構文 directive) が確定され、同様なコンセプトで今後の標準化を見据えている。
OpenMP 4.0 target 構文と OpenACC 規約
筆者の考えでは、OpenMP 4.0 の target 構文でアクセラレータ・プログラミングが可能な内容と OpenACC 2.0 レベルで可能なことを比べた場合、OpenMP 4.0 はその機能自由度の観点でまだ見劣りする点があり、アクセラレータデバイスに関する標準規約としては、3 年余り先じている OpenACC がデファクト・スタンダードとなるのではないかと思っている。これに関してもう一つ重要な視点は、現在市場に存在するアクセラレータデバイス(NVIDIA、AMD、Intel、その他DSP、FPGA等)の中で、OpenMP 4.0(過去の3.1機能仕様も当然含む)の規約を実装したソフトウェア環境を有してプログラミングできるデバイスは、インテル Xeon Phi しか存在しない。また、インテル社の Xeon Phi(MICアーキテクチャ)用のもう一つのオフロード・プログラミングモデルは、独自のディレクティブ仕様であり、インテル社以外の「デバイス」上では利用出来ない。さらに、インテル社がこのプログラミングモデルの後継としている OpenMP 4.0 の target 構文は、複数のデバイス間のプログラム互換性を推進するためのオープンな規約であるにも拘わらず、皮肉にもこの規約で動作するアクセラレータ・デバイスは、 現在、Xeon Phi 以外存在しないと言う情況にある。仮に、インテル社の動作環境で Phi ではなくマルチコアCPU を target として動作させようとしよう。この場合、プログラム上に Phi デバイス用の「OpenMP target構文」のオフロード・ディレクティブが記述されている場合、どのように動作するのだろうか?完全に無視されてしまうかどうかは分からないが、これだと、同じ OpenMP ディレクティブのソースコードでありながら、「マルチコアCPU」上では、並列化動作できないと言う不自然さが生じる。一つのソースコードでのプラットフォーム互換性に問題が出る。これが、OpenMP 4.0 の正しい動作かどうかは調べていないが、CPUとデバイスの両者で多くの feasibility の知見とそれを改善してゆく時間が必要なのではないかと感じざるを得ない。
OpenMP 4.0 に準拠するということは、それ以前の OpenMP 3.1 までのマルチコアベースの並列化機能も取り込む必要がある。x86 アーキテクチャを有する Intel Xeon Phi の場合は、現在のインテル社の OpenMP 環境をそのまま踏襲できるため、これは可能である。しかし、他社のデバイスに関しては、そもそも OpenMP エンジンを有していないため、当該デバイス用の OpenMP 3.1 機能を含めた 4.0 の環境の新たに開発を行うことは、あまり合理的な話ではない。となると、インテル社以外のデバイスで、OpenMP 4.0 に対応することはかなり敷居が高いと言えよう。一方、インテル社自体も Xeon Phi のようなコプロセッサに対する並列ソフトウェア環境が OpenMP 4.0 ベースのままで踏襲していくと、アクセラレータ用のソフトウェア開発環境においては、今後益々、他デバイスとのプログラム互換性という観点で孤立感を高めてしまう可能性もある。OpenACC 2.0 では、すでに Xeon Phi も含めたマルチベンダーデバイスを利用出来る仕様策定がなされており、PGI では 2014 年にこの 3 社のデバイス用の OpenACC コンパイラを市場提供する。OpenACC の使い勝手の向上や、ネイティブな並列言語 CUDA C/C++、CUDA Fortran 等の言語体系とのインターオペラビリティの向上、さらに異なるマルチベンダーデバイス上で OpenACC 実装が利用出来ることになると、OpenACC の利用にも弾みが付く可能性がある。特に、OpenACC の特長は、「プログラム互換性」だけでなく、複数のデバイス間でも、それぞれの特性に応じたベスト・パフォーマンスが得られること、すなわち「性能互換性」を志向したプログラミング・モデルでもあることだ。そのためにユーザが指定可能な directives と clauses が用意されている。なお、2013 年 11 月に米国のスーパーコンピュータ「Titan Cray XK7」を保有している Oak Ridge Leadership Computing Facility は、GCC (Linux) の OpenACC 2.0 への対応を行うための取り組みを進めていることを発表した。オープンソースのコンパイラも OpenACC への実装が始まりつつある。
ユーザの視点で見た場合でも、現在のところ、OpenMP directives と OpenACC directives の共存でプログラミングした方が分かり易いと言う利点がありそうだ。ソースプログラムに、OpenMP と OpenACC の両方のディレクティブを入れておけばよいのである。PGIコンパイラの場合は、コンパイルオプションとして -acc(OpenACC directives を解釈する) と -mp(OpenMP directivesを解釈する)オプションがあるが、使用用途に分けてこれら二つの実行バイナリを作成しておけばよい。もう一つ、ユーザにとって重要なことは、OpenACC は現在、Windows、Linux、OS X の OS プラットフォーム用に開発環境が存在するが、Intel Xeon Phi 用の開発環境は、現在のところ Linux のみに限定されている。
オフロード形式のプログラミングモデルの合理性
Intel Xeon Phi コプロセッサを利用する方法として、(1) Native Compilation(ネイティブモード)と
(2) Offload Compilation(オフロード形式のコンパイルモード、これを使うにはインテル独自の directive と OpenMP 4.0 target directive がある)の二つがある。前者の Native Compilation モードでは、Phi 自体が Pentium ベースのレガシーな x86 命令セットを有するため、従来の x86 CPU と同じ扱いで既存のプログラムを Phi 用にコンパイル出来る。一方、他社のデバイスでは、x86 命令セットは有していないため、そのアクセラレータ用に既存のプログラムをコンパイルしてネイティブに実行させることは出来ない。自ずと、CPUとアクセラレータの二つの実行形式が協同して実行するモデル、すなわち、「オフロード形式のプログラミングモデル」を使用せざるを得ない。こういうことになると、わざわざ、オフロードのような形式ではなく、Xeon Phi のようにネイティブに動作する実行形式の方が、ユーザにとって簡単ではないかと言う議論となる。既存の並列プログラム資産がコンパイルでき、そのままアクセラレータ上で動作する、これほど楽なことはない。しかし、そこには大きな落とし穴が存在する。この鍵を握るのは、アクセラレータデバイスの「動作クロック周波数」である。
そもそも、一般的なアクセラレータの「動作クロック周波数」は、0.8 ~ 1.1GHzである。2013年の Intel、NVIDIA、AMD の製品共にその動作クロックは、この範囲に入る。プロセッサの消費電力は、動作周波数に比例して増える。既存の CPU の周波数が 4GHz 以内で頭打ちなのは、一つの理由としてプロセッサの消費電力の壁が存在するからである。近年、HPC システムの性能向上には、単位電力当たりの性能を伸ばす必要があった。そこに、NVIDIA の GPU のようなアクセラレータが出現した。「動作クロック周波数」を 1GHz 前後として、消費電力のベースラインを下げる代わり、大量の演算コアを配置したプロセッサ(デバイス)で性能向上を目指すものである。さて、ここで 1GHz 程度の動作周波数のプロセッサ性能をイメージしてみよう。これは、2000 年前後の Pentium 3 ~ Pentium 4 初期ロット時代のスカラ性能と考えれば良い。今から見ると非常に性能が低いプロセッサと言うことになる。Intel Xeon Phi の上で、ネイティブモードでコンパイルして実行した場合、この動作周波数の低さ、すなわちスカラ性能の低さがプログラムの全体性能を決めてしまう。もし、仮に「スカラ実行特性」しか有しないプログラムを Intel Xeon Phi 上で実行して比較した場合、既存の 3GHz 前後のクロックを有する単一 CPU コア上で実行した方がより高速と言うことになる。ネイティブモードで Intel Xeon Phi 上で実行して利を得るプログラムは、Phi の 512-bit wide SIMD を利用出来るようにループがベクトル化され、かつ、MIMD 並列実行が可能な特性を有するものしかない。すなわち、プログラム全体として見た場合、高いベクトル化率を有し、かつ、高い並列化率を有するプログラムでないと、Intel Xeon Phi 上の「ネイティブモード」では高性能を得ることができないのである。
一般に、アクセラレータは「動作クロック周波数」が低いため、この上で「スカラ部分の実行」を行うことは、大きくプログラム全体性能の低下をもたらす。こうしたスカラ実行部分は高速な CPU 側で実行し、アクセラレータ上では計算 intensive な部分をベクトル・並列実行で集中的に行うと言う構図が、現状のアクセラレータ・アーキテクチャを考えた場合、合理的な使い方となる。これが、すなわち、これが「オフロード形式」の実行形態なのである。アクセラレータのプログラミングモデルが「オフロード形式」にならざるを得ない一つの理由は、一般的なアクセラレータの「動作クロック周波数」が低いためであることに因るものである。
SIMDベクトル演算とアムダールの法則(Intel Xeon Phiのネイティブモード実行の明と暗)
現在、市場に流通する三社のアクセラレータは、共に wide-vector operation が可能である。すなわち wide-SIMD 処理できる。但し、各社のデバイスのその動作方法は異なる。デバイス上の SIMD 処理は、gather/scatter 等のマスキングを使い「条件」を含んだベクトルを同時処理することが出来ないものもあるため、厳密な定義でのベクトル演算とは言えないが、ここでは広義のベクトル処理として扱う。Intel Xeon Phi の場合は、単精度レベルで 16-wide のベクトル長、NVIDIA Kepler は、32-wide(warp)、AMD Radeon は、64-wide(wavefront) 単位の SIMD(ベクトル)処理が可能である。プログラム的見地では最内側のループを対象としてベクトル・SIMD 処理の基本単位を作り、その外側ループ構造で MIMD 並列単位を作ることで、数多くの並列実行実体を生成して、ハードウェアの並列演算コアとのマッピングを行い、ベクトルならびに並列実行にて高速化を図る。オフロード形式のプログラミングモデルでは、必ず、こうしたベクトル化かつ並列化可能なループ構成をオフロードの対象としてプログラミングを行う。一方、Xeon Phi のネイティブモードの場合においても、ベクトル処理を有効に活用しなければ、理想的な高速化ができない。アクセラレータでは、単に「並列処理」の高速化だけではなく、その基本実行主体が「ベクトル処理」されていることによって高速化が達成されるのである。従来の CPU においては、最近の AVX 機構でも高々 256-bit wide (単精度で 8、倍精度で 4 のベクトル長)の SIMD が提供されているものの、こうした短いベクトル長であったため、プログラムの「ベクトル化率」が全体プログラムの性能にどの程度影響を及ぼすかと言う議論はあまりなかった。実は、20~30年前にスーパーコンピュータが「ベクトル機」の全盛時代であった時は、プログラムの「ベクトル化率」が性能を左右する大きな要素であった。ベクトル機で性能高速化する際の最も重要な点は、全体プログラムの中でスカラ演算部分をどれだけ排除するかと言う点、すなわちベクトル化率を出来るだけ 99% に近づけると言う最適化方針が存在した。アクセラレータにおいても、wide-vector operation が出来るようになったため、ベクトル演算効果を阻害しないプログラム作りが必要となる。もちろん、オフロード対象となるループ部分は、データ依存性がないため、本来ベクトル化も並列化も可能であることが普通であるが、「ベクトル演算効果を阻害しない」というところに意義がある。効果を最大限に高めるには、例えば、stride-1 のメモリアクセスや if 分岐の論理判断の合理的処理等の方策がチューニングにおいては必要となると言うことである。
プログラム全体の何%が並列化可能かと言う指標は「並列化率」と言うが、この割合により並列効果が変化する。並列化しても問題の大きさが変化しないという前提の下、これをモデル化したのがアムダールの法則である。このアムダールの法則を使って、ベクトルプロセッサを対象としたモデル化もできる。プログラム全体のベクトル化可能な割合であるベクトル化率の他に、もう一つのパラメータとして、スカラ実行した場合の時間とベクトル実行した場合の時間の比率(これを「ベクトル加速率」という。)をモデル化パラメータとすれば、全体のプログラムのベクトル化率割合に応じた性能のシミュレートが出来る。但し、ベクトル加速率は、プログラムの演算特性(計算密度や演算命令の種類)によって変化するため、予め何らかの方法で仮定することが必要となる。
以下の図は、全体のプログラムの実行時間がベクトル化されたループだけで構成される「姫野ベンチマーク」を例に、Xeon Phi の 61コアある中の 1コア内(512-bit vector 命令)で行われるベクトル演算の性能を模擬してみたものである。仮定に基づいているため、個々の模擬(絶対)性能を議論するのではなく、ベクトル化率に応じた性能曲線の傾向や絶対性能のベースとなる「動作クロック周波数」の違いによりベクトル性能も決まること、ベクトル化による性能効果はベクトル化率 95% 以上であれば加速率が高くなることなどを理解して欲しい。前項の話題でも触れたが、Xeion Phi のネイティブモードで実行する際は、全体のプログラムとして、このベクトル演算の恩恵を得ることが重要であるため、プログラム全体のベクトル化率が低いコードの場合、ネイティブモードで実行しても大きな性能の享受を期待できないことが予想できる。繰り返しになるが、Xeion Phi のネイティブモードを利用する際は、ベクトル化・並列化が可能な実行割合が 90% を超えるようなプログラムでないと、それ相当の性能を期待できないように思う。「ネイティブでコンパイル」できると言うと、どのようなプログラムでも Xeon Phi の高速性の恩恵を受けることができると言った誤解を生んでいるようだが、スカラ計算部の比率が高いプログラムではその高速化は難しいだろう。ということを総合すると、筆者の意見は、Xeon Phi も含めて一般的なアクセラレータの性能を最大限引き出すためのプログラミングモデルは、「オフロード型のモデル」が今のところ最適であろうと思っている。この理由は、ベクトル化による性能効果を期待できないスカラ部分は高速な CPU に処理を任すことによって、CPUとアクセラレータのそれぞれの良さを活用できるからである。但し、その際に問題となるのは、CPU とアクセラレータ間のデータ転送時間を最小化すると言う課題だけは残る。
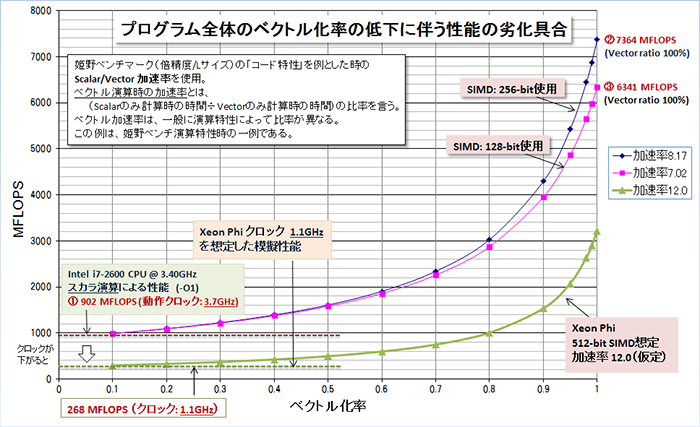
上記の図の内容を具体的に説明しよう。性能測定の条件は以下に記した。この中で、ベクトル加速率が AVS/SSE のベクトル長である 4倍、2倍以上となっている点については、コンパイラによるベクトル化最適化による他の効果、すなわち、メモリプリフェッチやキャッシュの最適利用効果による性能改善が含まれているものと考えられる。上図では、例えば、一般的にプログラムのベクトル化率が低下していくと、性能の劣化が一気に始まることも見て取れる。また、その劣化の程度は、低い動作クロックで駆動される「スカラ性能」に収束していく。ベクトル性能を優位に働くようにするには、全体プログラムのベクトル化率も考慮に入れなければならないことが分かる。また、Xeon Phi の「動作クロック周波数」が 1.1 GHz とした場合、現在の 3GHz 前後の CPU の性能と比べると、その性能のベースが大きく低下していることが分かるかと思う(スカラレベルではかなり遅い)。
姫野ベンチマーク(倍精度/Lサイズ)の「コード特性」を例とした時のScalar/Vector 加速率を使用。 ベクトル演算時の加速率とは、(Scalarのみ計算時の時間÷Vectorのみ計算時の時間)の比率を言う。 ベクトル加速率は、一般に演算特性によって比率が異なる。この姫野ベンチの加速率を以下の方法で 模擬する。使用したコンパイラは PGI 13.9。システム機材は、Intel i7-2600 CPU @ 3.40GHzを使用した。 (実行時の動作周波数は、Linux システムから捕捉し、3.7 GHz turboベースの実行であることを確認) このプロセッサは 256-bit AVX 演算が可能であるため、SIMD:256bit の命令と SIMD:128bit 命令を使った 二つの実行形式を作成して性能を測定。これがベクトル加速率の違いとして現れる。 ①の性能をベクトル化率 0%の「スカラ性能」の実測値として使用。 ②は、ベクトル化率100%とした時の AVX 256-bit(倍精度で 4-wide) で達成した性能 ③は、ベクトル化率100%とした時の SSE 128-bit(倍精度で 2-wide) で達成した性能 ①スカラ時の実測性能(902MFLOPS) $ pgf90 -O1 himenoBMTxp_omp.f90 ②ベクトル機構(AVX/SIMD256)を使用時の実測性能 (7364MFLOPS) $ pgf90 -O2 -Mvect=simd:256 himenoBMTxp_omp.f90 ③ベクトル機構(SIMD128)を使用時の実測性能 (6341 MFLOPS) $ pgf90 -O2 -Mvect=simd:128 himenoBMTxp_omp.f90 以上の性能値を使用して、②と③時のベクトル加速率を逆算し、アムダール則を使って性能曲線を描いた。 Xeon Phi の性能シミュレートは、単純に①のスカラ性能値に両者のクロック比(=1.1/3.7) を乗した ものをスカラ性能ベースとした。Xeon Phi(512-bit vector) のベクトル加速率を 12.0 として 性能曲線を描いた。ただ、この加速率はもっと大きいかもしれないし、小さいかもしれない。
プログラムの中でオフロードする対象部分とは
Fortran/C/C++ 言語で記述されたプログラムの中で、時間が掛かる処理部分をオフロードして、アクセラレータ側で処理することが一般的である。これは、多くの場合、「Do / for ループ」である。要は、ループ構造を有する繰り返し部分を「並列処理で高速化する」ことをアクセラレータ上で実現する。プログラム内にこうしたループ構造が少ない場合、並列化が出来ないあるいは、並列効果が現れない場合が多いため、そもそもアクセラレータによる高速化の対象外となる。すなわち、プログラム内で「時間を消費するループ構造」が存在すれば、アクセラレータによる高速化の対象とすることができる。また、「並列処理で高速化」を行うと言うことに関しては、マルチコア環境下の OpenMP による場合と同じ構図となる。従って、OpenMP を適用して並列化出来ているプログラムは、OpenACC 適用の対象となる。但し、享受できる並列性能に関しては OpanMP の場合とは異なるチューニング要素があるため、アクセラレータで常に性能加速率が良くなるとは言えない。最後に大事な点は、並列対象となるループでは、並列実行における阻害要因がない(並列依存性がない)ことが求められる。並列依存性が存在するループ構造の場合は、これをなくすためのプログラムの変更が必要とされ、これが不可能な場合は、そもそも「並列化」による高速化はできないことは言うまでもない。
OpenACC Standardとは
OpenACC Standard について簡単に説明する。これは、Accelerators(デバイス)用のプログラミング API の標準仕様である。具体的に言えば、Fortran, C/C++ 言語上で指定するコンパイラ・ディレクティブの仕様とこの機能を支援するための API ルーチン群を言う。特に、CPUホストからアクセラレータ側に処理をオフロードするための目的に策定されたものである。
- ユーザサイドでは、開発者がアクセラレータで実行するコード部分をディレクティブで指定する(コンパイラに対して、ヒントを与える)
- OpenACC コンパイラは、ホスト側の処理をデバイス側にオフロードするコードを生成し、また、ホストと デバイス間のデータ転送コードの生成を行うと言った機能を果たす
OpenACC の利点、特長は以下の点にある。
- 可搬性(ポータビリティ):ホストOS, ホストCPUs, アクセラレータ、コンパイラ等、異なるプラットフォームに変わっても「性能」の可搬性を提供
- ハイレベル/高級言語:基本的に、CUDA, OpenCL or 低レベル GPU プログラミング等の難しい言語知識の必要がなく、現在のソースコードの変更を必要としない
- 高生産性:迅速な開発ステップと段階的に行える開発
- ヘテロジニアスなプログラム:シングル・ソース・ベースで維持管理可能(CPU用、デバイス用と分ける必要なし)
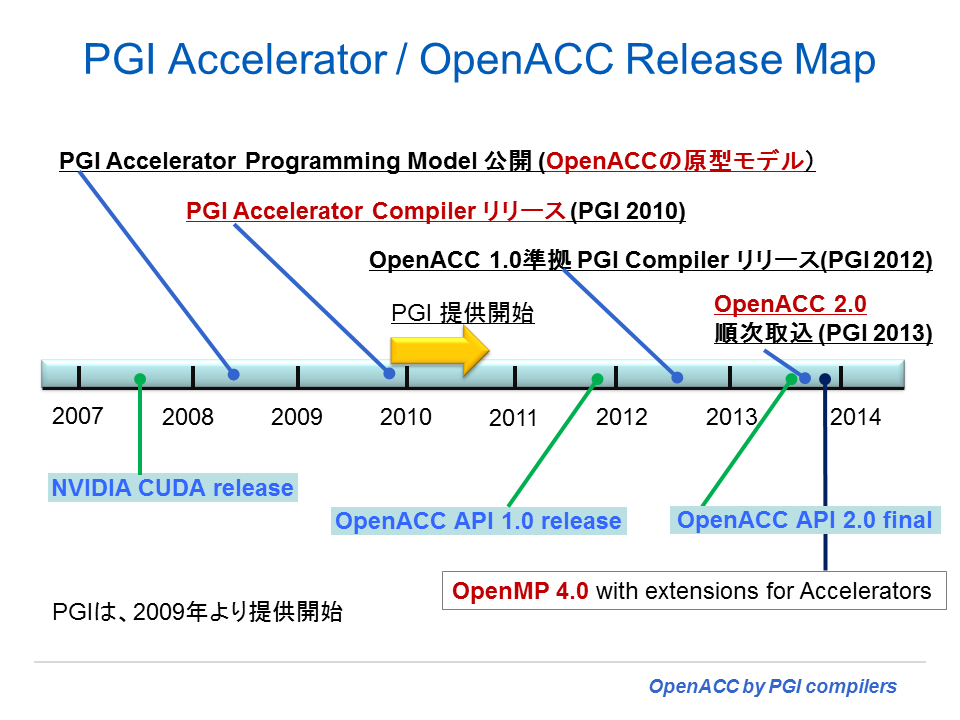
以下の図は、2013年に至る今までの OpenACC の変遷を示したものである。
OpenACC コンパイラが行うこと
プログラム内に、「ディレクティブ」でヒントを与えると、コンパイラは、次のような機能を組み込んだホスト側コードとデバイス側コードを自動生成する。コンパイラは、これら両者の「実行コード」リンクし、一つの実行形式のバイナリファイルとして生成する。
- デバイスをイニシャライズ
- ホスト(CPU)とデバイス間の「データ」と「プログラム」の転送の管理
- ホスト(CPU)とアクセラレータ間の「データ」を監視
- ホスト(CPU)とアクセラレータ間の「仕事」を管理
- 「仕事」を並列に分割して、デバイス・ハードウェアの並列構造にマッピング
- さらに、性能最適化を試みる
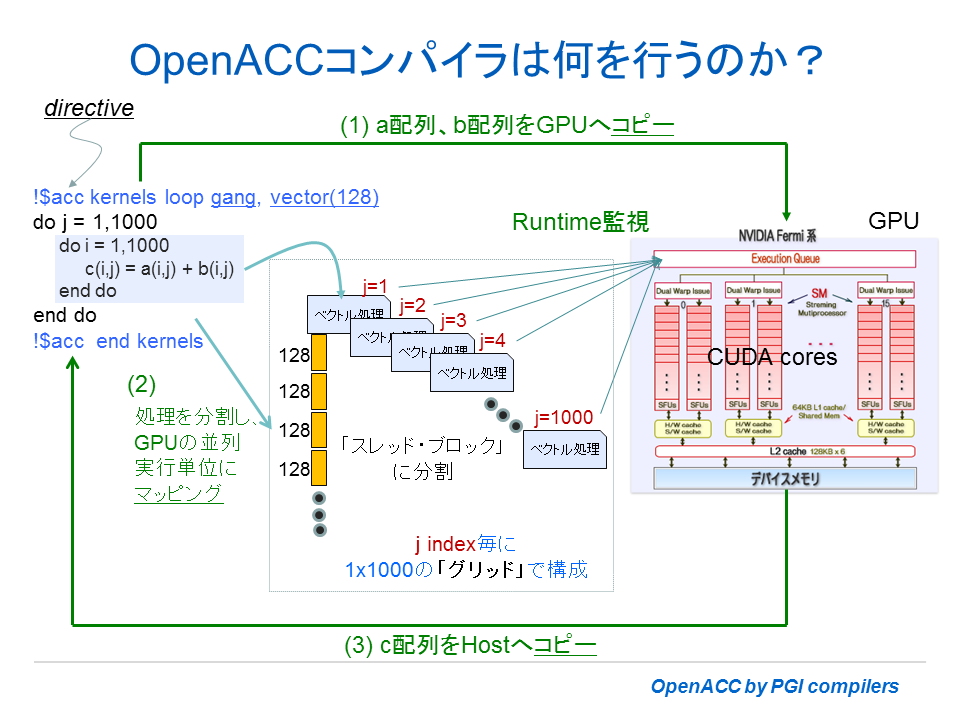
以下の図は、具体的に Fortran のループ処理を例にとって、OpenACCコンパイラはどのような処理を行うコードを作成するか模式的に示した。ここでは、GPU をアクセラレータとしている。ネスト・ループの内側ループを SIMD/Vector 処理を行うために、適当な長さ単位(チャンク)に分割する。この単位でトータル 1000 個の要素を計算処理する。また、外側ループは、内側ループで行われる SIMD/Vector 処理のブロックを 1000 個用意し、これを並行に動作させるコードを作り上げる。1000 要素のベクトル処理を行うブロック 1000 個、GPU 上のタスクキューに並べ、有効な GPU コアの中に当該ブロックを並行にタスクとして投入する。ここまでが、オフロードされた仕事の処理の方法を説明したものであるが、もちろん、その前に、GPU側で必要とするデーターの転送を行う。同様に計算結果となるデータも GPU から CPU 側に戻す処理も行う。こうしたデータ転送に係わる処理命令もコンパイラは自動的に作成する。以上が OpenACC コンパイラが作り上げるコードの概要である。
[Reference]
- Michael Wolfe,The Portland Group, Inc., Heterogeneous X64+GPU Systems Using OpenACC