OpenACC ディレクティブによるプログラミング
2章 OpenMP と OpenACC プログラミング・モデル
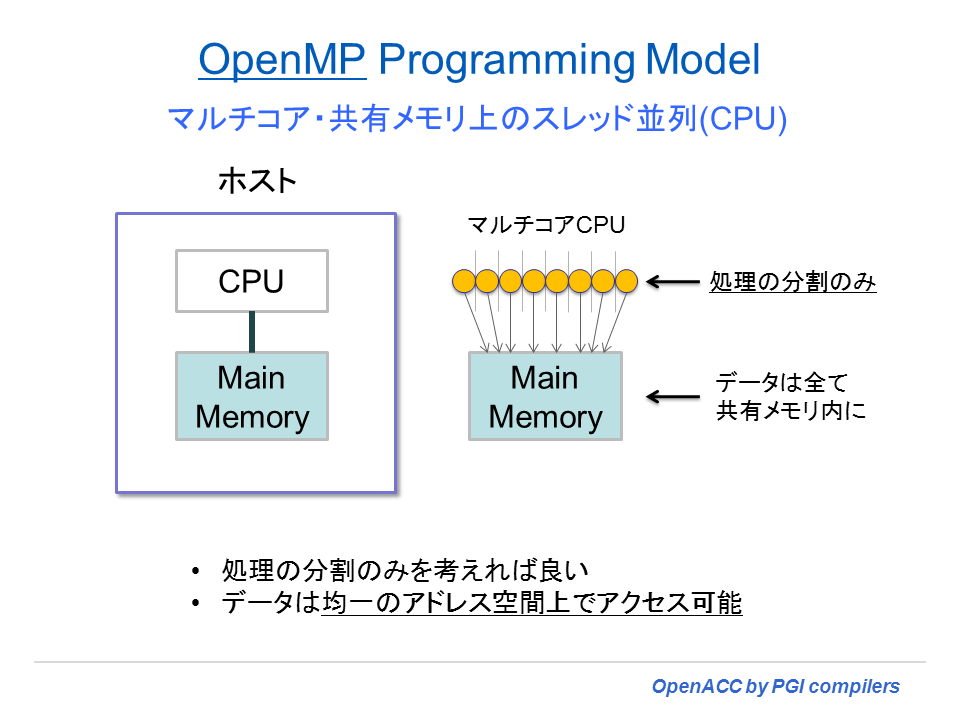
OpenMPプログラミングモデル
OpenMP プログラミングモデルは、共有メモリ構成を有するマルチコアCPU上で、マルチスレッド並列化を行うためのプログラミング手法である。ユーザは、プログラム内の並列化可能なループに対して、コンパイラ・ディレクティブで指示することにより、スレッド並列コードを生成できる。各コア上で分割した処理をスレッド実行することによって並列効果を得る。メモリ空間は共有できるため、プログラマは「処理の分割の指示」を行うだけで済む。OpenMP は、並列化指示のためのディレクティブ仕様とこの機能を支援するための API ルーチン群を言う。下図は、OpenMPのスレッド実行の概念図である。
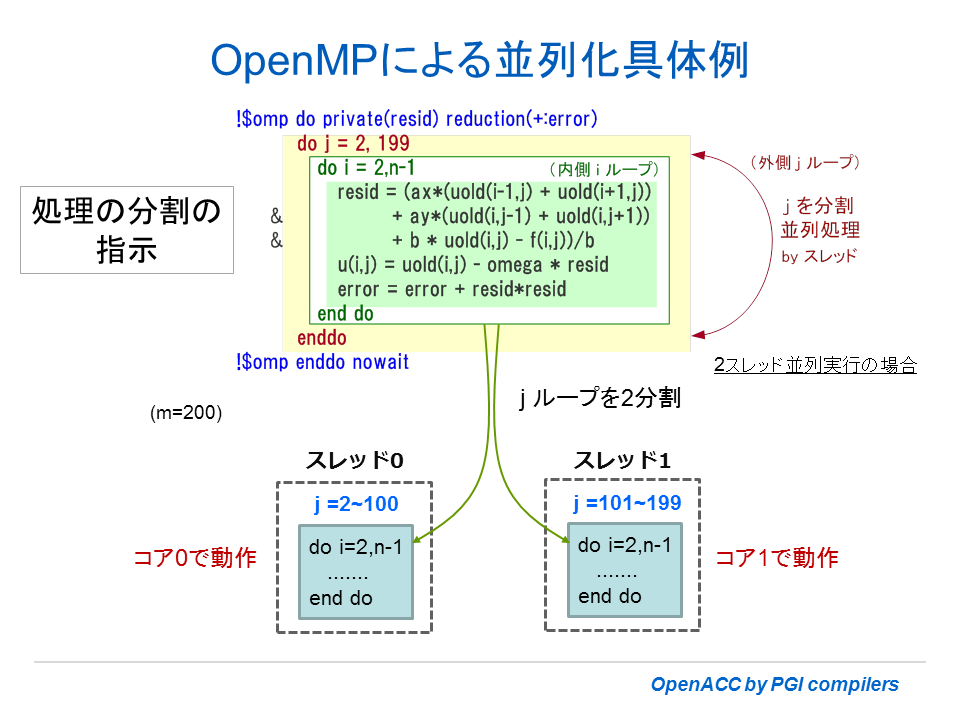
具体的にディレクティブを挿入した場合の例を示そう。下図は、Fortran プログラムのループに対して、並列化の指示を行っている様子を表したものである。j ループを分割し、異なるスレッドで並列実行する形を示している。なお、OpenMP の場合、配列等のデータはメモリ共有を想定しているため、データアドレス空間の分割等の作業は必要ない。
OpenACC(アクセラレータ)プログラミングモデル
OpenACC プログラミングモデルの動作概念図を以下に示す。この図では Accelerator Programming Model と称しているが、OpenACC のモデルと同じと考えて良い。ホスト側 CPU で実行する一部の処理をオフロードして、デバイス側で処理を行う場合の実行モデルである。このページの説明では、デバイスを GPU とした場合を例とした図を描いている。「GPGPU」とは、General Purpose GPU の意味である。
プログラムの中で、時間を消費し並列化可能とするループ部分を切り出して、デバイス側で(オフロード)処理を行う。そのためには、当該ループプログラム部分のデバイス用コードを作成しなければならない。例えば、デバイスが NVIDIA 社の GPU であれば、CUDA 用のバイナリを生成することが必要となる。また他のデバイスであれば、当該デバイス用の実行バイナリを作成することになる。コンパイラは CPU 側の実行形式とデバイス側の実行形式を作成し、これら二つの実行形式バイナリをバインドして、一つの実行ファイルとして生成する。
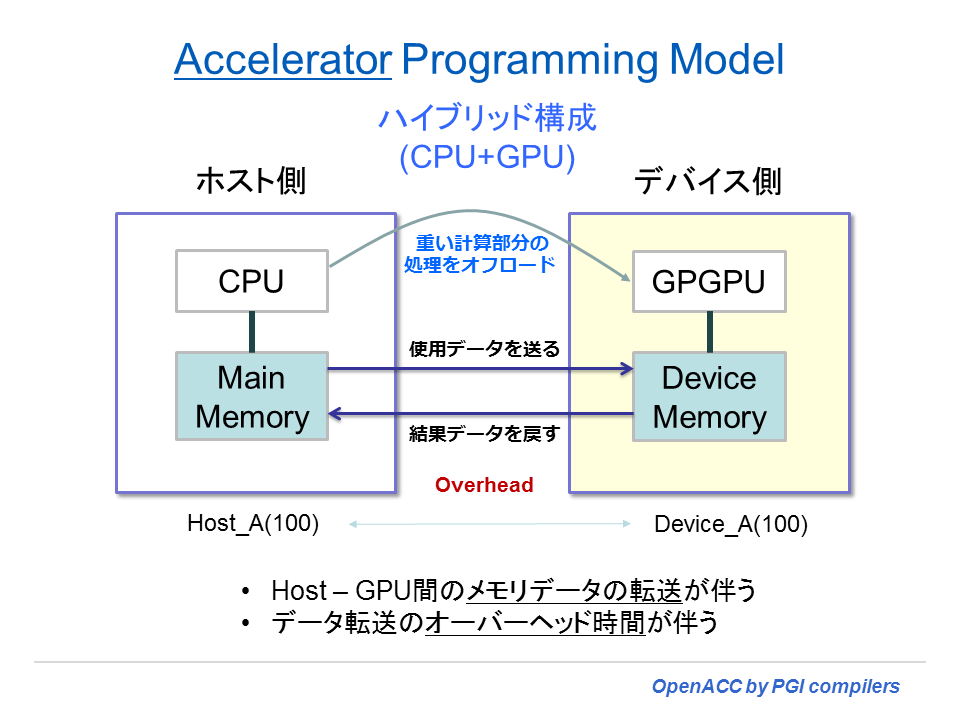
上記の通りプログラムによる処理部分はCPU部とデバイス用に分割される。必要とするデータはどうであろうか?上図のような二つのメモリ空間を配するハイブリッド構成で動作させるためには、デバイス側に対して計算処理に必要なデータをコピーしなければならない。また、処理が終了した後、CPU側へデータを戻すことが必要となる。必要とするデータを転送する部分は、OpenACC コンパイラが担い、基本的に自動的にそのコードを作成する。あるいは、ユーザが明示的にディレクティブを指定してデータのコピーを指示することも出来る。これらに必要な時間は、全てオーバーヘッドとなる。こうしたオーバーヘッドが加算されたとしても、全体の性能(経過時間)として CPU のみで実行する時間よりもメリットがあれば、アクセラレータを使用する意味が出てくる。
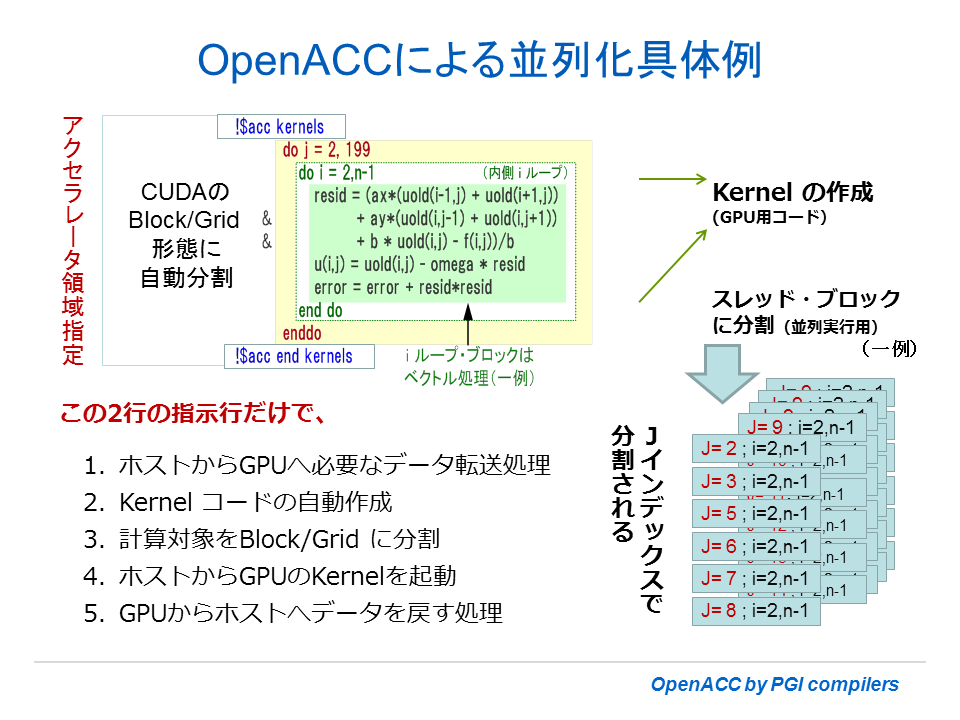
以下の例は、上記 OpenMP の例と同じ Fortran プログラムのループに対して、OpenACC ディレクティブで指示した様子を表したものである。OpenMP の場合と同じように j ループを分割し、それぞれの単位が並列実行主体(スレッド・ブロック)となる。このスレッド・ブロックがアクセラレータのコア上で独立に処理される形態をとる。また、OpenACC モデルの場合、内側の i ループ自体も並列に分割して並列多重度を高めて実行する場合が多い。なお、OpenACC の場合、デバイス上で使用する配列等データの転送は、コンパイラによって自動的にそのコードが生成される。
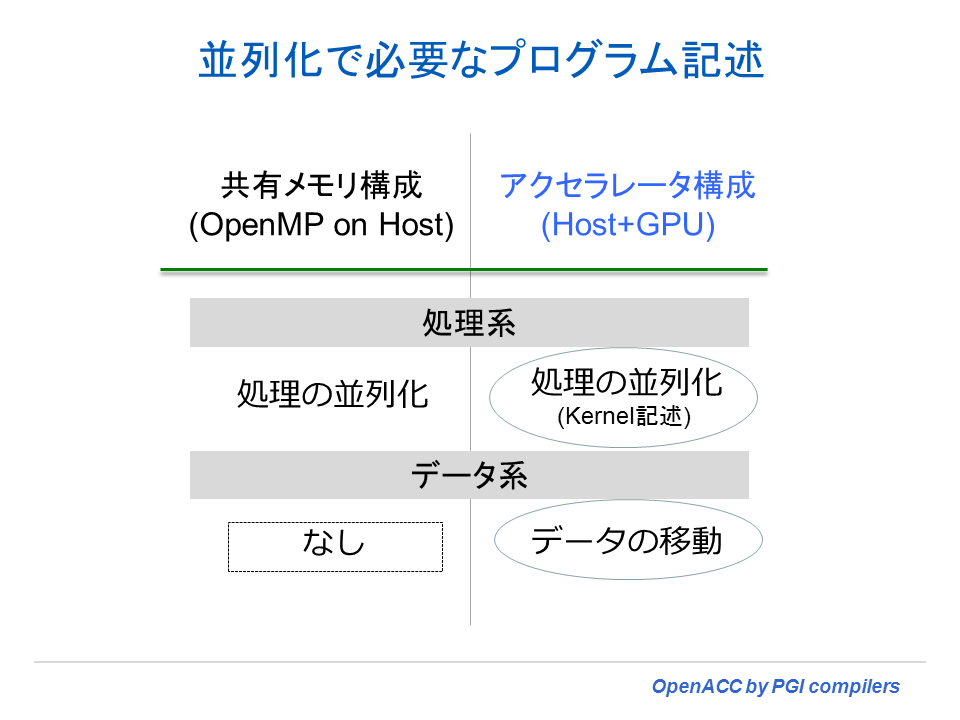
OpenMPとOpenACC(アクセラレータ)プログラミングモデルの違い
OpenMP と OpenACC のプログラム記述上の違いを説明しよう。ディレクティブを使用してプログラムに指示するべきものとして、「処理系の指示」と「データに関する指示」の二つに分けられる。処理系に関しては二つのプログラミングモデル共に、「処理の並列化の指示」を行う必要がある。しかし、データ系に関してアクセラレータ(OpenACC) モデルでは、データのコピーに関する処理を行う必要がある。デフォルトでは暗黙にコンパイラがデータコピーのためのコードを生成するが、最適な性能を得るためには、データコピーを制御するために明示的にディレクティブを挿入する必要が出てくる。OpenMP の場合は、共有メモリ空間を使用するため、こうしたデータコピー等の概念はそもそも存在しない。これが、二つのプログラミングモデルのディレクティブの記述における大きな違いと言える。逆に言えば、CPU とデバイス間のデータコピーに係わる時間(オーバーヘッド)は、OpenACC(アクセラレータ)プログラミングにおいて、当該性能を左右する大きなポイントとも言える。
プログラム開発の観点では、現在 OpenMP 化されているプログラムは、OpenACC に置き換えることは容易である。ループに対する並列化が可能であることがすでに分かっているため、OpenMP directives を OpenACC directives に変更すれば良い。そして、その際に行う追加作業は、最適なデータコピーとなるように OpenACC data directive を挿入し、データコピーの最適化を行うこととなる。
OpenMP プログラムを簡単に OpenACC に移行できるか?
OpenMP を適用したプログラムがすでに存在し、これを OpenACC 用に置き換えすることは比較的、容易である。「容易である」という意味合いは、OpenMP ディレクティブがプログラム内に挿入されているため、プログラム内で並列化可能なループがすでに特定されていることによるものである。すなわち、OpenMP と同じ場所を OpenACC の並列化対象部とすることができる。この意味では、ポーティングが容易いと言うことになる。
但し、注意点が二つある。マルチコア上で OpenMP スレッド並列が性能的にもうまく動作しているプログラムであっても、GPU 上でも同じようにうまく動作するとは限らない。一般に GPU は、非常に多くの「並列性(並列実行単位)=数百~数千の並列反復」を必要とする。非常に多くの並列単位に分割できないようなループ特性の場合は、GPU上で大きな性能が得られないことがある。それに対して、マルチコア CPU 上では、高々 4-way あるいは 8-way 程度の並列単位でも効果的に並列効果が現れるところに特徴がある。また、GPUのアーキテクチャに依存した特性であるが、メモリ内のデータレイアウトの如何でメモリ・アクセス性能が大きく低下する場合がある。例えば、stride-1 のアクセスが可能な場合に、GPUのメモリバンド幅を有効に活用できるが、このパターンでアクセス出来ない場合は性能が低下する。一方、CPUの場合は、大容量キャッシュの活用で性能低下を軽減出来る場合も多い。こうしたCPUとGPUの内部的アーキテクチャの違いが、同じ並列化可能なループであっても性能効果の様相が異なって見えることがある。
もう一つは、OpenACC の場合、CPUメモリとデバイス・メモリ間のデータ転送に伴う「時間」を追加コストとして加えて考えなければいけないことである。もし、「単純」に、プログラム上の OpenMP ディレクティブを OpenACC ディレクティブに置き換えた場合、ほとんどの場合、OpenACC は良い性能を得ることが出来ないであろう。この理由は、OpenACC kernels/parallel ディレクティブのデフォルトの動作態様が、ループ構造を並列化するだけではなく CPU とデバイス間で必要とするデータ転送を行うようコード生成しているため、kernels/parallel ディレクティブを指定した並列対象ループ本体が反復する度に転送時間が積算され、このコストの方が並列演算のコストよりも優位になることが多いためである。こうしたことを回避するために、メモリデータのコピーの管理を適切に行うことが OpenACC を利用する上で最も重要なこととなる。OpenACC にポーティングする際にこの点を配慮し、 OpenACC data ディレクティブを使ってデータ転送を最適化すると、大きな性能効果を得ることが出来る。その概説を 4 章の「OpenACC を使って、まず始めてみよう」で説明している。
CPU+アクセラレータ構成における性能のボトルネック部分
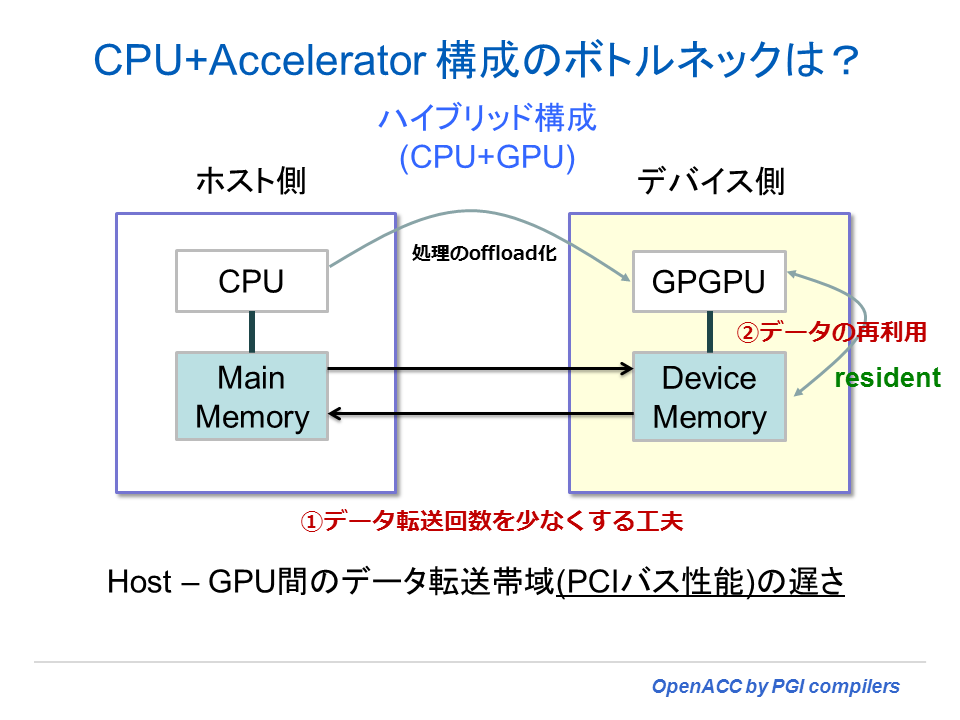
CPU+アクセラレータ(デバイス)構成において性能面で加わるオーバーヘッドは、CPU とデバイス間のデータ転送に伴う「時間」である。頻繁にデータ転送を行うような形になると、こうしたプログラミングモデルによる「性能効果」は望めず、CPU のみで実行した場合より時間が掛かる場合がある。これは、デバイスとの接続が PCI Express バス(Gen2 で 5~6GB/sec程度)を経由することによる遅延が原因であるが、それ以上に、データ転送の回数を最適化しないことによる問題の方が大きい。OpenACC を使用する場合には、OpenMP の場合とは異なり、以下に述べるデータの転送に係わることに注意をしてプログラミングする必要がある。
- CPU~デバイス間のデータ転送回数を極力少なくする
- 一度、デバイスに転送したデータを常駐させ、データの再利用を図るようにする
CPU+アクセラレータ構成のメモリモデル
OpenACC 等のアクセラレータ・プログラミングモデルにおけるメモリに係わる論点を整理する。このプログラミングモデルでは、以下のようなメモリ・ハンドリングに関する特徴がある。以下では、アクセラレータ・デバイスのことを GPU として表記している。
- ホスト側 CPU のデータ空間とGPU 側のデータ空間の二つの空間が必要
- CPU と GPU 間のデータ転送が必要、これが overhead 時間となる
- データコピーを明示的に制御するには、そのためのディレクティブが必要
- データコピーの最小化を行う必要がある
- ホスト側CPUメモリとGPU側メモリ間の転送帯域(PCI帯域)に制約があるため、オフロードすべき対象を絞る必要がある
- 性能加速性があるループ領域かどうかの判別が必要
- ループ内の「計算密度」のレベルで加速性が変化することを認識する
- GPU側のメモリ容量に制約がある(現在、< 6GB)
- 非常に大きな配列を伴う「コード領域」のオフロード化に制約
- もし必要な場合、複数の GPU デバイス上の MPI 化が必要