OpenACC ディレクティブによるプログラミング
4章 OpenACC を使って、まず始めてみよう
最初の心構え
簡単な C と Fortran プログラムを使って、OpenACC によるプログラミングを体験してみる。さらに、実際に GPU を使って実行を行う。OpenACC プログラミングにおいて最も大事な点を最初に述べよう。それは、ホストとアクセラレータ(デバイス)間のデータ転送を行う場所をプログラム上で明示しなければ、実行時に非常に時間が掛かる場合があると言うことである。プログラムの並列化部分の処理は、基本的にコンパイラに任せればよい。これに関して大きな労力はほとんどない。OpenACC においてプログラマが取り組むべき重要なタスクは、「データ転送を行う場所」をプログラム上で明示的に指示することだ。予め、この点を理解して OpenACC のプログラミングに臨む必要がある。
この章では単純なプログラム例を取り上げ、OpenACC の「並列マッピング用のディレクティブ」と「データコピーのためのディレクティブ」の二つを大まかに理解する。そして、第 2 章で述べた「CPU+アクセラレータ構成における性能のボトルネック部分」に関して、どのような方策をとれば両者間のデータコピーを極小化できるかも理解する。ここで使用した機材等を以下に示す。
| 使用した機材、ソフトウェア |
|---|
| コンパイラ |
| PGI Accelerator Fortran/C/C++ Workstation version 13.10 for Linux |
| NVIDIA CUDA ソフトウェア環境 |
| CUDA 5.5 の utility(nvprof, NVIDIA Visual Profiler等) |
| OS |
| Scientific Linux release 6.4 (Carbon) = Red Hat EL 6.4 |
| ハードウェア |
| Intel(R) Core(TM) i7 CPU 920 @ 2.67GHz / 4 cores |
| GPU |
| NVIDIA Tesla K20c (Kepler) with CUDA 5.5 driver |
pgaccelinfo コマンドで GPU のプロパティを見る
PGIのコマンドに pgaccelinfo がある。このコマンドを実行すると、以下に示すように搭載されている GPU(アクセラレータ)のハードウェア・プロパティの内容が表示される。複数のデバイスが搭載されていれば論理デバイス番号と共に、各デバイスの詳細が順番に表示される。
[photon29 Laplase]$ pgaccelinfo CUDA Driver Version: 5050 (GPU ソフトウェア・ドライバーのバージョン) NVRM version: NVIDIA UNIX x86_64 Kernel Module 319.37 Device Number: 0 Device Name: Tesla K20c Device Revision Number: 3.5 Global Memory Size: 5368512512 Number of Multiprocessors: 13 Number of SP Cores: 2496 Number of DP Cores: 832 Concurrent Copy and Execution: Yes Total Constant Memory: 65536 Total Shared Memory per Block: 49152 Registers per Block: 65536 Warp Size: 32 Maximum Threads per Block: 1024 Maximum Block Dimensions: 1024, 1024, 64 Maximum Grid Dimensions: 2147483647 x 65535 x 65535 Maximum Memory Pitch: 2147483647B Texture Alignment: 512B Clock Rate: 705 MHz Execution Timeout: No Integrated Device: No Can Map Host Memory: Yes Compute Mode: default Concurrent Kernels: Yes ECC Enabled: No Memory Clock Rate: 2600 MHz Memory Bus Width: 320 bits L2 Cache Size: 1310720 bytes Max Threads Per SMP: 2048 Async Engines: 2 Unified Addressing: Yes Initialization time: 31218 microseconds Current free memory: 5288091648 Upload time (4MB): 1062 microseconds ( 730 ms pinned) Download time: 1031 microseconds ( 642 ms pinned) Upload bandwidth: 3949 MB/sec (5745 MB/sec pinned) Download bandwidth: 4068 MB/sec (6533 MB/sec pinned) PGI Compiler Option: -ta=nvidia,cc35 (このデバイスに対するPGIコンパイラオプション)
簡単なラプラス方程式のプログラム
GitHub に、C 言語で書いた簡単なラプラス方程式をヤコビ法で解くプログラムがある。今回はこのプログラムを利用することにする。プログラムは、以下のサイトから入手出来る (Apache License)。
https://github.com/parallel-forall/cudacasts/tree/master/ep3-first-openacc-program
ここでは、このソースを元に以下のベース・プログラムを作成した。なお、PGI C コンパイラは C11 準拠のコンパイラであり、デフォルトで C11 構文を解釈する。C/C++特有のコンパイラオプションに関してはこちらを参照。
/*
* Copyright 2012 NVIDIA Corporation
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
#include <math.h>
#include <string.h>
#include "timer.h"
#define NN 4096
#define NM 4096
double A[NN][NM];
double Anew[NN][NM];
int main(int argc, char** argv)
{
const int n = NN;
const int m = NM;
const int iter_max = 1000;
const double tol = 1.0e-6;
double error = 1.0;
memset(A, 0, n * m * sizeof(double));
memset(Anew, 0, n * m * sizeof(double));
for (int j = 0; j < n; j++)
{
A[j][0] = 1.0;
Anew[j][0] = 1.0;
}
printf("Jacobi relaxation Calculation: %d x %d mesh\n", n, m);
StartTimer();
int iter = 0;
while ( error > tol && iter < iter_max )
{
error = 0.0;
for( int j = 1; j < n-1; j++)
{
for( int i = 1; i < m-1; i++ )
{
Anew[j][i] = 0.25 * ( A[j][i+1] + A[j][i-1]
+ A[j-1][i] + A[j+1][i]);
error = fmax( error, fabs(Anew[j][i] - A[j][i]));
}
}
for( int j = 1; j < n-1; j++)
{
for( int i = 1; i < m-1; i++ )
{
A[j][i] = Anew[j][i];
}
}
if(iter % 100 == 0) printf("%5d, %0.6f\n", iter, error);
iter++;
}
double runtime = GetTimer();
printf(" total: %f s\n", runtime / 1000);
exit(0);
}
順番に OpenACC ディレクティブを挿入した効果とその結果を示すために、以下のソースプログラムを作成した。また、同じ内容の Fortran ソースプログラムも作成した。各ソースファイルは、これから説明する順番に suffix が付いている。なお、C プログラムのコンパイル時は、Linux、Windows 環境共に、timer.h ファイルが必要となるため、これをソースファイルと同じ directory に置いておくこと。以下に述べる事例は、全て Linux 上で実施した際の様子を示したものである。
| 内容 | C | Fortran |
|---|---|---|
| (1) CPU用のベースプログラム | laplace0.c | laplace0.f90 |
| (2) OpenACC のループ並列化用ディレクティブ挿入 | lapace1.c | laplace1.f90 |
| (3) OpenACC のデータ・ディレクティブ挿入 | lapace2.c | laplace2.f90 |
| C プログラム用ヘッダーファイル | timer.h | -- |
なお、Winodws 環境の C コンパイラでコンパイルする場合は、時間計測関数を変更するためコンパイルオプションに "-DWIN32" を付けてコンパイルする必要がある。Fortran の場合はその必要はない。
(Windows の場合) $ pgcc -O2 -DWIN32 -Minfo lapace*.c
(1) CPU 上での実行
laplace0.c と laplace0.f90 をコンパイルして CPU 上で実行を行ってその時間を把握する。-O2 最適化オプションを適用して、SSE(SIMD) ベクトル化を実施した性能を取得する。以下の C の場合と Fortran の場合を示したが、このプログラムにおいては、Fortran コーディングの方が速い。いずれも1コアを使用して実行した結果である。
C プログラムの場合
[kato@photon29 Laplase]$ pgcc -O2 -Minfo laplace0.c -o laplace0-C (コンパイル・リンク)
main:
39, Generated vector sse code for the loop
56, Generated an alternate version of the loop
Generated vector sse code for the loop
Generated 3 prefetch instructions for the loop
66, Memory copy idiom, loop replaced by call to __c_mcopy8
[kato@photon29 Laplase]$ ./laplace0-C (実行)
Jacobi relaxation Calculation: 4096 x 4096 mesh
0, 0.250000
100, 0.002397
200, 0.001204
300, 0.000804
400, 0.000603
500, 0.000483
600, 0.000403
700, 0.000345
800, 0.000302
900, 0.000269
total: 131.864039 s 131秒掛かる。
Fortran プログラムの場合
[kato@photon29 Fortran]$ pgfortran -O2 -Minfo laplace0.f90 -o laplace0-F
laplace:
31, Memory zero idiom, array assignment replaced by call to pgf90_mzero8
32, Memory zero idiom, array assignment replaced by call to pgf90_mzero8
34, Generated vector sse code for the loop
48, Generated an alternate version of the loop
Generated vector sse code for the loop
Generated 3 prefetch instructions for the loop
56, Memory copy idiom, loop replaced by call to __c_mcopy8
[kato@photon29 Fortran]$ ./laplace0-F
Time measurement accuracy : .10000E-05
Jacobi relaxation Calculation: 4096 x 4096 mesh
0 0.2500000000000000
100 2.3970623764720811E-003
200 1.2043203299441085E-003
300 8.0370630064013904E-004
400 6.0346074818462547E-004
500 4.8300191812361559E-004
600 4.0251372422966947E-004
700 3.4514687472469996E-004
800 3.0211701794469192E-004
900 2.6855145615783949E-004
total : 73.50961699999999 sec 73秒掛かる。
(2) OpenACC のループ並列化のためのディレクティブを適用する
さて、OpenACC ディレクティブを使ってみよう。一般的には、プログラム内で時間が掛かりそうなルーチンに目星を付け、その中で並列化可能なループを見つける。そして、このループに対して OpenACC ディレクティブを適用する。以下に、laplace1.c の主要部をリスティングの形 (-Mlistコンパイルオプション)で表示した。行番号 50 は while 構文で収束計算を行う外側の大きなループである。このループの中に、OpenACC 並列化対象となるループが複数存在している。行番号 55 と 66 は、2 重のネストループであり、このループ内はデータ依存性がないため並列化可能である。この二つのネストループの直前に、OpenACC kernels ディレクティブを挿入してみる。このディレクティブは、その直下のネストループを対象としてアクセラレータ用に並列化コード(カーネル)を作成するよう、コンパイラに指示するものである。最低限、この kernels ディレクティブを指示することで、コンパイラは自動的にアクセラレータの並列構造に応じた並列化マッピングを行い、当該カーネルコードを作成する。さらにもう一つ、コンパイラはアクセラレータ上で必要とされる「データ」を調べ、ホストとアクセラレータ間でデータのコピー(copyin/copyout) を行うためのコードも自動的に作成する。大きく言ってこの二つの機能がデフォルトで行う kernels ディレクティブの動作となる。注意すべき点は、コンパイラはその度にデータコピーを行うコードも必ず作成すると言う点にある。これが、場所によっては「データ転送の嵐」を引き起こす。このプログラムもこの問題に相当するものである。以下のコンパイル・メッセージを見て欲しい。プログラムの行番号と共に「並列化の箇所」と「データのコピーを行う配列名とそのサイズ」が表示されており、データ転送を行う場所が分かる。この場所は、while ループの内側にあるため、収束計算のためのイテレーション毎に必ず、データ転送のイベントが生じる形態となっている。これが性能的に問題となる。
C プログラムの場合
( 50) while ( error > tol && iter < iter_max ) // 外側の収束計算のための反復ループ ( 51) { ( 52) error = 0.0; ( 53) ( 54) #pragma acc kernels //以下の nest loop の並列化コードとデータコピーのためのコードを作成する ( 55) for( int j = 1; j < n-1; j++) ( 56) { ( 57) for( int i = 1; i < m-1; i++ ) ( 58) { ( 59) Anew[j][i] = 0.25 * ( A[j][i+1] + A[j][i-1] ( 60) + A[j-1][i] + A[j+1][i]); ( 61) error = fmax( error, fabs(Anew[j][i] - A[j][i])); ( 62) } ( 63) } ( 64) ( 65) #pragma acc kernels //以下の nest loop の並列化コードとデータコピーのためのコードを作成する ( 66) for( int j = 1; j < n-1; j++) ( 67) { ( 68) for( int i = 1; i < m-1; i++ ) ( 69) { ( 70) A[j][i] = Anew[j][i]; ( 71) } ( 72) } ( 73) ( 74) if(iter % 100 == 0) printf("%5d, %0.6f\n", iter, error); ( 75) ( 76) iter++; ( 77) }[kato@photon29 Laplase]$ pgcc -acc -O2 -Minfo=accel laplace1.c -o laplace1-C main: 54, Generating present_or_copyout(Anew[1:4094][1:4094]) Generating present_or_copyin(A[0:][0:]) データコピーコード生成 Generating NVIDIA code Generating compute capability 1.3 binary Generating compute capability 2.0 binary Generating compute capability 3.0 binary 55, Loop is parallelizable 「並列化可能であることを伝えているだけ」のメッセージ 57, Loop is parallelizable Accelerator kernel generated 「並列化コード生成した」と言うメッセージ 55, #pragma acc loop gang /* blockIdx.y */ 57, #pragma acc loop gang, vector(128) /* blockIdx.x threadIdx.x */ 61, Max reduction generated for error 65, Generating present_or_copyin(Anew[1:4094][1:4094]) Generating present_or_copyout(A[1:4094][1:4094]) データコピーのコード生成 Generating NVIDIA code Generating compute capability 1.3 binary Generating compute capability 2.0 binary Generating compute capability 3.0 binary 66, Loop is parallelizable 68, Loop is parallelizable Accelerator kernel generated 「並列化コード生成した」 66, #pragma acc loop gang /* blockIdx.y */ 68, #pragma acc loop gang, vector(128) /* blockIdx.x threadIdx.x */
この実行バイナリを実行すると、以下に示すとおり 192 秒掛かっている。アクセラレータ上で並列実行しているにもかかわらず、CPU の 1コアで実行した時の 131 秒よりも遅い。この理由は、while ループ 1 回毎に、A[] と Anew[] 配列のデータコピーが行われており、実行経過時間のほとんどをデータのコピーで消費しているからである。その様子を見てみよう。実行前に、PGI の環境変数 PGI_ACC_TIME に 1 をセットしておくと、実行終了後に、アクセラレータの使用に関する性能プロファイル結果が出力される。まず、ここで気がつくことは、実測した経過時間が 192 秒にも拘わらず、簡易プロファイルの「Accelerator Kernel Timing data」が示す時間は、90 秒である。この差は何か?アクセラレータ・デバイス側で捕捉したプロファイル時間 90 秒は基本的に正しい。となると、192 - 90 = 102秒は CPU サイドで消費した経過時間となる。実はこの時間は CPU 側でデータを転送する際に生じるオーバーヘッドである。具体的に言えば、ホスト~デバイス間のデータ転送は、大きなデータをブロックに分けて、それを順番に送っている。転送はストリーム型で流れるわけではなく、ブロック間に何も転送処理を行っていない間隙が生まれる。この積算時間が 100 秒近くになっていると言うことになる(なお、この時間の中には、PGI_ACC_TIME をセットしてプロファイル情報を取得するためのオーバーヘッドも含まれる)。そもそも、データ転送回数が多いためこうしたオーバーヘッドも目立つ結果となっている。従って、データ転送を極力少なくするように、一度、アクセラレータ側に送ったデータはそこで常駐化してデータを使用することが必要となる。これが、アクセラレータを使う際のコツである。 以下のプロファイル情報の中に下線を引いたところがデバイス側で捕捉したデータコピーに関するプロファイル情報である。総計すると約 85 秒、純粋にデバイスとの間でデータ転送に費やされていたことになる。それ以外は、アクセラレータ上での並列実行処理を行った時間であるため、高々 5 秒程度でこの処理が終わっていることになる。
(以下の環境変数は、実行時の簡易プロファイル情報を表示する際に 1 を指定)
[kato@photon29 Laplase]$ export PGI_ACC_TIME=1
[kato@photon29 Laplase]$ ./laplace1-C
Jacobi relaxation Calculation: 4096 x 4096 mesh
0, 0.250000
100, 0.002397
200, 0.001204
300, 0.000804
400, 0.000603
500, 0.000483
600, 0.000403
700, 0.000345
800, 0.000302
900, 0.000269
total: 192.115189 s 全経過時間
(簡易プロファイル結果)
Accelerator Kernel Timing data
main NVIDIA devicenum=0
time(us): 90,086,723 GPUデバイス側で消費した経過時間
54: compute region reached 1000 times
54: data copyin reached 8000 times 8000回転送(論理的に分割したデータブロックの転送回数)
device time(us): total=22,482,897 max=2,835 min=2,804 avg=2,810
57: kernel launched 1000 times
grid: [32x4094] block: [128]
device time(us): total=3,029,920 max=3,263 min=3,022 avg=3,029
elapsed time(us): total=3,038,940 max=3,274 min=3,032 avg=3,038
57: reduction kernel launched 1000 times
grid: [1] block: [256]
device time(us): total=264,735 max=322 min=263 avg=264
elapsed time(us): total=273,700 max=332 min=272 avg=273
65: data copyout reached 8000 times
device time(us): total=20,106,650 max=2,543 min=2,498 avg=2,513
65: compute region reached 1000 times
65: data copyin reached 8000 times
device time(us): total=22,505,711 max=2,921 min=2,794 avg=2,813
68: kernel launched 1000 times
grid: [32x4094] block: [128]
device time(us): total=1,593,490 max=1,649 min=1,584 avg=1,593
elapsed time(us): total=1,602,653 max=1,658 min=1,593 avg=1,602
74: data copyout reached 8000 times
device time(us): total=20,103,320 max=2,542 min=2,497 avg=2,512
NVIDIA/CUDA の場合、もう一つ、プロファイリングを行う方法がある。CUDA 5.0 以降の utility にコマンドベースで使用できる nvprof コマンドが提供された(これは、PGI とは別のソフトウェアのため、NVIDIA の toolkit/utility 等をインストールした場合に使用できる)。もちろん、コマンドベース以外に従来の NVIDIA Visual Profiler も使用できる。ここでは、nvprof の例を以下に示す。データのコピー(HtoD、DtoH)に関する時間、並列ループのカーネルが消費した時間が表示される。カーネルに関して、例えば、main_57_gpu とはソースの 57 行目のループをカーネル化したものという意味である。この結果でも、ほとんどがデータのコピーに関する時間となっていることが分かる。
[kato@photon29 Laplase]$ which nvprof /usr/local/cuda-5.5/bin/nvprof [kato@photon29 Laplase]$ nvprof ./laplace1-C (前略) ==14446== Profiling application: laplace1-C ==14446== Profiling result: Time(%) Time Calls Avg Min Max Name 49.96% 44.8411s 17000 2.6377ms 960ns 2.8134ms [CUDA memcpy HtoD] 44.59% 40.0236s 17000 2.3543ms 2.5600us 2.5152ms [CUDA memcpy DtoH] 3.43% 3.08076s 1000 3.0808ms 3.0737ms 3.0886ms main_57_gpu 1.74% 1.55899s 1000 1.5590ms 1.5491ms 1.5801ms main_68_gpu 0.29% 257.03ms 1000 257.03us 255.33us 259.33us main_61_gpu_red
Fortran プログラムの場合
Fortranプログラムの例の場合は、上記 C プログラムの場合と同様な見方をすることが出来る。実際の作業としては、ソースコードのリスティング と-Minfo によるコンパイル・メッセージを見て、「データのコピーの場所」や「並列化対象部分」を確認する。実行においては、プロファイリングを行って、デバイス上での性能情報を確認すると言うのが、一般的な作業の手順となる。以下の内容に関する説明は、上述した C プログラムの場合と同様であるため、ここでは割愛する。
( 42) iter = 0 ( 43) do while ( iter .le. iter_max-1 .and. error .gt. tol ) ( 44) ( 45) error =0.d0 ( 46) !$acc kernels !以下の nest loop の並列化コードとデータコピーのためのコードを作成する ( 47) do j = 2, m-1 ( 48) do i = 2, n-1 ( 49) Anew(i,j) = 0.25 * ( A(i,j+1) + A(i,j-1) & ( 50) + A(i-1,j) + A(i+1,j) ) ( 51) error = max(error, abs(Anew(i,j) - A(i,j))) ( 52) end do ( 53) end do ( 54) !$acc end kernels !Fortranでは kernels directive の終了を指示する必要有り ( 55) ( 56) !$acc kernels !以下の nest loop の並列化コードとデータコピーのためのコードを作成する ( 57) do j = 2, m-1 ( 58) do i = 2, n-1 ( 59) A(i,j) = Anew(i,j) ( 60) end do ( 61) end do ( 62) !$acc end kernels ( 63) ( 64) if ( mod (iter,100) == 0 ) print *, iter, error ( 65) iter = iter + 1 ( 66) ( 67) end do[kato@photon29 Fortran]$ pgfortran -acc -O2 -Minfo=accel laplace1.f90 -o laplace1-F laplace: 46, Generating present_or_copyout(anew(2:4095,2:4095)) データコピーのコード生成 Generating present_or_copyin(a(:,:)) Generating NVIDIA code Generating compute capability 1.3 binary Generating compute capability 2.0 binary Generating compute capability 3.0 binary 47, Loop is parallelizable 並列化可能 48, Loop is parallelizable Accelerator kernel generated 「並列化コード生成した」と言うメッセージ 47, !$acc loop gang, vector(4) ! blockidx%y threadidx%y 48, !$acc loop gang, vector(64) ! blockidx%x threadidx%x 51, Max reduction generated for error リダクション max の並列化 56, Generating present_or_copyin(anew(2:4095,2:4095)) データコピーのコード生成 Generating present_or_copyout(a(2:4095,2:4095)) Generating NVIDIA code Generating compute capability 1.3 binary Generating compute capability 2.0 binary Generating compute capability 3.0 binary 57, Loop is parallelizable 並列化可能 58, Loop is parallelizable Accelerator kernel generated 「並列化コード生成した」と言うメッセージ 57, !$acc loop gang ! blockidx%y 58, !$acc loop gang, vector(128) ! blockidx%x threadidx%x [kato@photon29 Fortran]$ ./laplace1-F Time measurement accuracy : .10000E-05 Jacobi relaxation Calculation: 4096 x 4096 mesh 0 0.2500000000000000 100 2.3970623764720811E-003 200 1.2043203299441085E-003 300 8.0370630064013904E-004 400 6.0346074818462547E-004 500 4.8300191812361559E-004 600 4.0251372422966947E-004 700 3.4514687472469996E-004 800 3.0211701794469192E-004 900 2.6855145615783949E-004 total : 134.6178450000000 sec Accelerator Kernel Timing data laplace NVIDIA devicenum=0 time(us): 67,520,889 46: compute region reached 1000 times 46: data copyin reached 8000 times device time(us): total=22,482,737 max=2,860 min=2,803 avg=2,810 48: kernel launched 1000 times grid: [64x1024] block: [64x4] device time(us): total=3,092,183 max=3,338 min=3,079 avg=3,092 elapsed time(us): total=3,101,602 max=3,775 min=3,089 avg=3,101 48: reduction kernel launched 1000 times grid: [1] block: [256] device time(us): total=136,836 max=196 min=135 avg=136 elapsed time(us): total=145,897 max=205 min=143 avg=145 56: kernel launched 1000 times grid: [32x4094] block: [128] device time(us): total=1,586,117 max=1,643 min=1,574 avg=1,586 elapsed time(us): total=1,594,878 max=1,652 min=1,583 avg=1,594 60: data copyout reached 17000 times device time(us): total=40,223,016 max=2,597 min=8 avg=2,366 (nvprof を使用してプロファイルを取得した例) [kato@photon29 Fortran]$ nvprof laplace1-F Time(%) Time Calls Avg Min Max Name 59.47% 40.0338s 18000 2.2241ms 2.5600us 2.5040ms [CUDA memcpy DtoH] 33.30% 22.4147s 9000 2.4905ms 960ns 2.8042ms [CUDA memcpy HtoD] 4.69% 3.15774s 1000 3.1577ms 3.1524ms 3.1642ms laplace_48_gpu 2.34% 1.57630s 1000 1.5763ms 1.5645ms 1.5870ms laplace_56_gpu 0.19% 129.97ms 1000 129.96us 128.74us 131.17us laplace_51_gpu_red
(3) OpenACC のデータ・ディレクティブを明示的に挿入する
OpenACC data ディレクティブの役目
このステップでは、OpenACC モデルの本丸と言ってよい「データコピーを行う適切な場所」についてを考えてみる。デバイス(GPU)側の計算で必要な配列・データは while ループ実行前にデバイス側にコピーし常駐させ、while ループの内側の計算処理では、ホストとデバイス間でデータをコピーしないようにすると、上述 (2) で述べたような「データ転送の嵐」が避けられる。こうしたデータのコピーを行う場所の明示的な指定は、OpenACC data ディレクティブ(構文)を用いて行う。これを説明する前に、以下のポイントを理解しておいて欲しい。
- OpenACC の並列化を指示するためのディレクティブである kernels や parallel 構文の役目の一つは、その対象とするループ中で使用されている配列、スカラ変数を調べて、ホストとデバイス間のデータコピーを行うためのコード生成を「暗黙」に行うことである。従って、これらの構文を指定するとデフォルトの動作として、ホストとデバイス間のデータコピーを必ず行う。
- その際に用いている「データのコピーの方法」のデフォルトは、OpenACC data 構文の clause(節) である present_or_copy 節、present_or_copyin 節、present_or_copyout 節、present_or_create 節のいずれかを使用している。 present_***** 節の挙動は、コピーの対象となる配列が「アクセラレータ上のメモリ」上にアロケートされているかどうかのチェックを行い、その正否でデータコピーを行うかの判断を行うと言ったものである。事前に、かつ明示的に data 構文を用いてデータのアロケートとコピーを実施している場合に限り、kernels や parallel 構文の時点におけるデータコピーは行わない。この場合、アクセラレータ側では、すでにデバイス上にアロケートされているデータを使用して処理を行う形となる。present clause の詳細は、第7章 data 構文の clauses の項を参照のこと。
- ループ内にデータのコピーを伴う kernels や parallel 構文が配置される場合は、当該ループの外側で予め必要なデータの領域をアロケートし、コピーしておく必要がある。これを行うのが data ディレクティブの役目である。
以下に、説明した内容を具体的に図で表した。外側の loop ループの中に、kernels ディレクティブが存在している。この場合は、loop ループの周回毎に、kernels が生成した「データコピー」が実行される。データ転送の嵐となる。
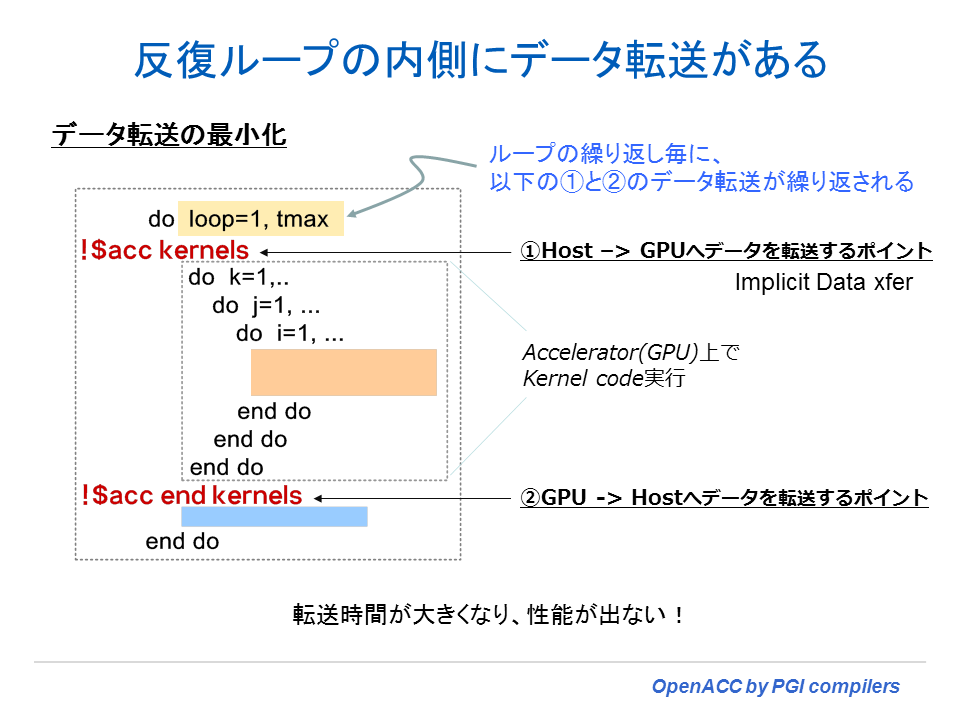
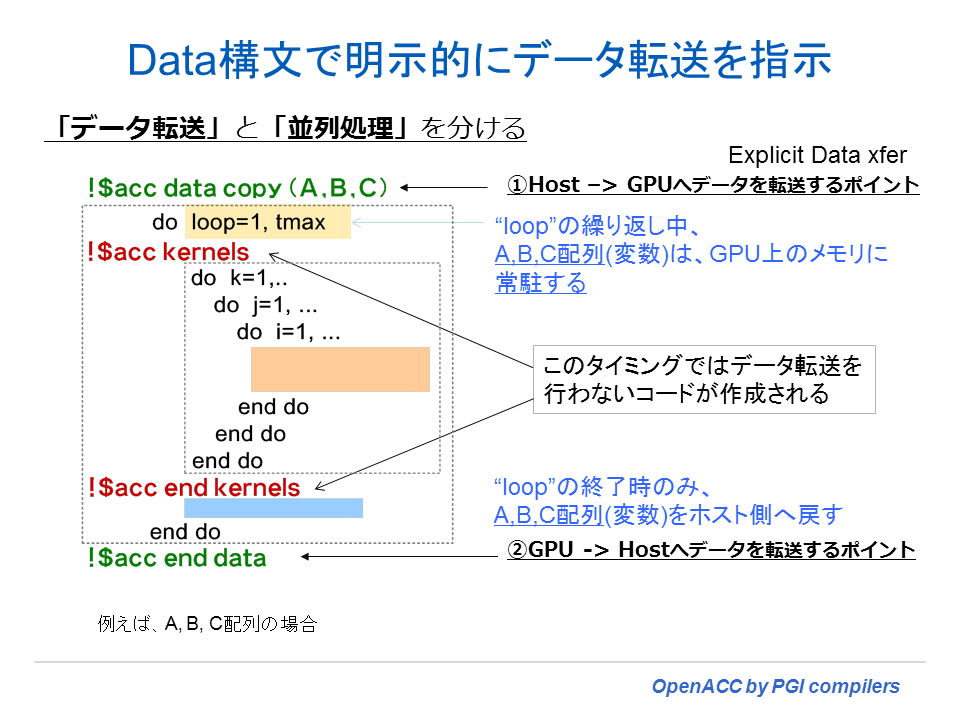
一方、外側のループの前に、data 構文を使い、当該ループ内で使用される配列のコピー属性を指定すると、この時点で、必要とする配列データのアロケートとホスト~デバイス間のデータ転送処理を行う。外側ループの内部の kernels 構文指定場所においては、データコピーは発生せず、すでにアクセラレータ側にあるデータを使用するようになる。そして外側ループの終端で、ホスト側で必要とされるデータがデバイス側からコピーされると言う形となる。
C プログラムの場合
OpenACC data ディレクティブを使用して、データ転送を行う場所を変更したプログラムを以下に示す。(2) で述べたプログラムに、以下の 50行目で示す 1 行だけ追加しただけである。while ループの直前に A 配列をデバイス側にコピーして、かつ、while ループが終了した時点で、A 配列の内容をデバイス側からホスト側に戻すと言う指示が #pragma acc data の copy(A) 節の表す意味となる。もう一つ、create(Anew) と言う節は、ホスト側~デバイス間のデータコピーは発生しないが、デバイス側に Anew 配列の領域をアロケートして、デバイス上の一時的配列として使いなさいと言う意味となる。下記のプログラムを見て、Anew 配列は、確かに一時的に使用する配列であり、これはデバイス上にのみ存在すればよいものであることが分かる。
( 50) #pragma acc data copy(A), create(Anew)
// while ループの前に A[] とAnew[] 配列のアロケート&コピーを行う
( 51) while ( error > tol && iter < iter_max )
( 52) {
( 53) error = 0.0;
( 54)
( 55) #pragma acc kernels
( 56) for( int j = 1; j < n-1; j++)
( 57) {
( 58) for( int i = 1; i < m-1; i++ )
( 59) {
( 60) Anew[j][i] = 0.25 * ( A[j][i+1] + A[j][i-1]
( 61) + A[j-1][i] + A[j+1][i]);
( 62) error = fmax( error, fabs(Anew[j][i] - A[j][i]));
( 63) }
( 64) }
( 65)
( 66) #pragma acc kernels
( 67) for( int j = 1; j < n-1; j++)
( 68) {
( 69) for( int i = 1; i < m-1; i++ )
( 70) {
( 71) A[j][i] = Anew[j][i];
( 72) }
( 73) }
( 74)
( 75) if(iter % 100 == 0) printf("%5d, %0.6f\n", iter, error);
( 76)
( 77) iter++;
( 78) }
[kato@photon29 Laplase]$ pgcc -acc -O2 -Minfo=accel laplace2.c -o laplace2-C
main:
50, Generating create(Anew[0:][0:]) while ループの前の明示的な A[] とAnew[] 配列の
Generating copy(A[0:][0:]) アロケート&コピー
55, Generating present_or_create(Anew[0:][0:]) すでに存在しているため、コピー動作は行わない
Generating present_or_copy(A[0:][0:])
Generating NVIDIA code
Generating compute capability 1.3 binary
Generating compute capability 2.0 binary
Generating compute capability 3.0 binary
56, Loop is parallelizable 並列化可能
58, Loop is parallelizable
Accelerator kernel generated 「並列化コード生成した」と言うメッセージ
56, #pragma acc loop gang /* blockIdx.y */
58, #pragma acc loop gang, vector(128) /* blockIdx.x threadIdx.x */
62, Max reduction generated for error リダクション max の並列化
66, Generating present_or_create(Anew[0:][0:]) すでに存在しているため、コピー動作は行わない
Generating present_or_copy(A[0:][0:])
Generating NVIDIA code
Generating compute capability 1.3 binary
Generating compute capability 2.0 binary
Generating compute capability 3.0 binary
67, Loop is parallelizable
69, Loop is parallelizable
Accelerator kernel generated 「並列化コード生成した」と言うメッセージ
67, #pragma acc loop gang /* blockIdx.y */
69, #pragma acc loop gang, vector(128) /* blockIdx.x threadIdx.x */実行性能を見てみよう。劇的に性能が向上したことが分かる。5.1 秒の経過時間で終了した。プロファイルの結果を見ても、データ移動にかかわる時間は、ほとんど無視できる程度までになり、経過時間のほとんどがアクセラレータ上における並列化処理に要した時間となっている。さらに性能を伸ばしたいのであれば、並列分割の方法を変更すると言った OpenACC loop 構文を使ったチューニングを行うこととなる。
[kato@photon29 Laplase]$ ./laplace2-C
Jacobi relaxation Calculation: 4096 x 4096 mesh
0, 0.250000
100, 0.002397
200, 0.001204
300, 0.000804
400, 0.000603
500, 0.000483
600, 0.000403
700, 0.000345
800, 0.000302
900, 0.000269
total: 5.176240 s
Accelerator Kernel Timing data
main NVIDIA devicenum=0
time(us): 4,911,997
50: data region reached 1 time DATA 領域のプロファイル
50: data copyin reached 8 times
device time(us): total=22,490 max=2,817 min=2,809 avg=2,811
80: data copyout reached 9 times
device time(us): total=20,112 max=2,514 min=11 avg=2,234
55: compute region reached 1000 times 計算領域のプロファイル
58: kernel launched 1000 times
grid: [32x4094] block: [128]
device time(us): total=3,019,989 max=3,253 min=3,011 avg=3,019
elapsed time(us): total=3,028,498 max=3,265 min=3,019 avg=3,028
58: reduction kernel launched 1000 times
grid: [1] block: [256]
device time(us): total=264,445 max=318 min=263 avg=264
elapsed time(us): total=273,440 max=327 min=271 avg=273
66: compute region reached 1000 times 計算領域のプロファイル
69: kernel launched 1000 times
grid: [32x4094] block: [128]
device time(us): total=1,584,961 max=1,643 min=1,574 avg=1,584
elapsed time(us): total=1,593,822 max=1,652 min=1,583 avg=1,593
[kato@photon29 Laplase]$ nvprof ./laplace2-C
Jacobi relaxation Calculation: 4096 x 4096 mesh
==28655== NVPROF is profiling process 28655, command: laplace2-C
0, 0.250000
100, 0.002397
200, 0.001204
300, 0.000804
400, 0.000603
500, 0.000483
600, 0.000403
700, 0.000345
800, 0.000302
900, 0.000269
total: 5.326739 s
==28655== Profiling application: laplace2-C
==28655== Profiling result:
Time(%) Time Calls Avg Min Max Name
62.31% 3.07718s 1000 3.0772ms 3.0709ms 3.0944ms main_58_gpu
31.59% 1.55993s 1000 1.5599ms 1.5487ms 1.5797ms main_69_gpu
5.18% 255.61ms 1000 255.61us 254.14us 257.70us main_62_gpu_red
0.47% 23.398ms 1008 23.212us 960ns 2.8118ms [CUDA memcpy HtoD] データコピー
0.45% 22.226ms 1009 22.027us 2.1760us 2.5026ms [CUDA memcpy DtoH] データコピー
Fortran プログラムの場合
( 43) !$acc data copy(A), create(Anew) while ループの前の明示的な A[] とAnew[] 配列の ( 44) do while ( iter .le. iter_max-1 .and. error .gt. tol ) アロケート&コピー ( 45) ( 46) error =0.d0 ( 47) !$acc kernels ( 48) do j = 2, m-1 ( 49) do i = 2, n-1 ( 50) Anew(i,j) = 0.25 * ( A(i,j+1) + A(i,j-1) & ( 51) + A(i-1,j) + A(i+1,j) ) ( 52) error = max(error, abs(Anew(i,j) - A(i,j))) ( 53) end do ( 54) end do ( 55) !$acc end kernels ( 56) ( 57) !$acc kernels ( 58) do j = 2, m-1 ( 59) do i = 2, n-1 ( 60) A(i,j) = Anew(i,j) ( 61) end do ( 62) end do ( 63) !$acc end kernels ( 64) ( 65) if ( mod (iter,100) == 0 ) print *, iter, error ( 66) iter = iter + 1 ( 67) ( 68) end do ( 69) !$acc end data[kato@photon29 Fortran]$ pgfortran -acc -O2 -Minfo=accel laplace2.f90 -o laplace2-F laplace: 43, Generating create(anew(:,:)) while ループの前の明示的な A[] とAnew[] 配列の Generating copy(a(:,:)) アロケート&コピー 47, Generating present_or_create(anew(:,:)) すでに存在しているため、コピー動作は行わない Generating present_or_copy(a(:,:)) Generating NVIDIA code Generating compute capability 1.3 binary Generating compute capability 2.0 binary Generating compute capability 3.0 binary 48, Loop is parallelizable 並列化可能 49, Loop is parallelizable Accelerator kernel generated 「並列化コード生成した」と言うメッセージ 48, !$acc loop gang, vector(4) ! blockidx%y threadidx%y 49, !$acc loop gang, vector(64) ! blockidx%x threadidx%x 52, Max reduction generated for error 57, Generating present_or_create(anew(:,:)) すでに存在しているため、コピー動作は行わない Generating present_or_copy(a(:,:)) Generating NVIDIA code Generating compute capability 1.3 binary Generating compute capability 2.0 binary Generating compute capability 3.0 binary 58, Loop is parallelizable 並列化可能 59, Loop is parallelizable Accelerator kernel generated 「並列化コード生成した」と言うメッセージ 58, !$acc loop gang ! blockidx%y 59, !$acc loop gang, vector(128) ! blockidx%x threadidx%x [kato@photon29 Fortran]$ ./laplace2-F Time measurement accuracy : .10000E-05 Jacobi relaxation Calculation: 4096 x 4096 mesh 0 0.2500000000000000 100 2.3970623764720811E-003 200 1.2043203299441085E-003 300 8.0370630064013904E-004 400 6.0346074818462547E-004 500 4.8300191812361559E-004 600 4.0251372422966947E-004 700 3.4514687472469996E-004 800 3.0211701794469192E-004 900 2.6855145615783949E-004 total : 5.108804000000000 sec Accelerator Kernel Timing data laplace NVIDIA devicenum=0 time(us): 4,850,648 43: data region reached 1 time DATA 領域のプロファイル 43: data copyin reached 8 times device time(us): total=22,486 max=2,819 min=2,808 avg=2,810 69: data copyout reached 9 times device time(us): total=20,117 max=2,516 min=11 avg=2,235 47: compute region reached 1000 times 計算領域のプロファイル 49: kernel launched 1000 times grid: [64x1024] block: [64x4] device time(us): total=3,085,237 max=3,306 min=3,072 avg=3,085 elapsed time(us): total=3,093,842 max=3,316 min=3,080 avg=3,093 49: reduction kernel launched 1000 times grid: [1] block: [256] device time(us): total=135,991 max=191 min=134 avg=135 elapsed time(us): total=144,900 max=200 min=143 avg=144 57: compute region reached 1000 times 計算領域のプロファイル 59: kernel launched 1000 times grid: [32x4094] block: [128] device time(us): total=1,586,817 max=1,639 min=1,578 avg=1,586 elapsed time(us): total=1,595,822 max=1,663 min=1,587 avg=1,595 [kato@photon29 Fortran]$ nvprof laplace2-F Time measurement accuracy : .10000E-05 Jacobi relaxation Calculation: 4096 x 4096 mesh ==29975== NVPROF is profiling process 29975, command: laplace2-F 0 0.2500000000000000 100 2.3970623764720811E-003 200 1.2043203299441085E-003 300 8.0370630064013904E-004 400 6.0346074818462547E-004 500 4.8300191812361559E-004 600 4.0251372422966947E-004 700 3.4514687472469996E-004 800 3.0211701794469192E-004 900 2.6855145615783949E-004 total : 5.296412999999999 sec ==29975== Profiling application: laplace2-F ==29975== Profiling result: Time(%) Time Calls Avg Min Max Name 64.30% 3.15825s 1000 3.1583ms 3.1508ms 3.1652ms laplace_49_gpu 32.11% 1.57709s 1000 1.5771ms 1.5624ms 1.5857ms laplace_59_gpu 2.66% 130.58ms 1000 130.58us 129.31us 131.84us laplace_52_gpu_red 0.48% 23.559ms 1008 23.371us 960ns 2.8277ms [CUDA memcpy HtoD] 0.45% 22.230ms 1009 22.031us 2.1440us 2.5024ms [CUDA memcpy DtoH]
性能のまとめ
OpenACC のプログラミングにおいては、ホスト~デバイス間の「データ転送を行う場所」をプログラム上で明示的に行うことが、性能を向上させるための重要なタスクとなっている。本章では、OpenACC data ディレクティブを活用し、データコピーを行う場所を指定することにより、ループ内部で必要のないデータ転送を避けることができることを示した。その結果、データの転送を最適化することにより大きな性能向上があることも理解できた。実際のプログラムはより複雑なものではあるが、ポーティングにおいては、段階的にディレクティブを挿入してみて、その実行結果を見ながら、順番に OpenACC 化を行っていくことが望ましい。以下に、今回のプログラムを使って性能がどのように変化したかを纏める。なお、性能測定は、簡易プロファイル取得を行わないモードで実施した(上記で説明してきたモードとは異なる)。
| 挿入ディレクティブの内容 | C (秒) | Fortran (秒) |
|---|---|---|
| (1) CPU上での1コア性能 | 131.9 | 73.5 |
| OpenMPスレッド並列(4コア並列) | 52.0 | 53.1 |
| CPU+GPU アクセラレータを使用した性能 | ||
| (2) OpenACC のループ並列化用ディレクティブ挿入 | 168.1 | 120.3 |
| (3) OpenACC のデータ・ディレクティブも挿入 | 5.1 | 5.1 |