OpenACC ディレクティブによるプログラミング
5章 OpenACC ディレクティブの概説
PGI コンパイラの OpenACC の準拠状況
PGI Accelerator Compiler 製品の OpenACC の準拠レベルは以下のようになっている。
- PGI 13.10 以前: OpenACC 1.0 に準拠する
- PGI 14.1 以降: OpenACC 2.0 に準拠する(但し、14.1 以降、OpenACC 2.0 の機能を順次取込)
- PGI 15.1 以降: OpenACC 2.5 を順次取込
- PGI 18.1 以降: OpenACC 2.6 を取込
PGI 14.1 以降の機能追加については 10 章を参考のこと。なお、本プログラミング・ガイドは、OpenACC 2.0/2.5 仕様を基にドキュメント化している。
OpenACC プログラムのコンパイルの方法
PGI Accelerator コンパイラを使って、OpenACC プログラムをコンパイルするためのオプションを説明する。OpenACC に構文を解釈し、アクセラレータ用のコンパイルを行うためには、 -acc オプションを必要とする。また、コンパイルとリンクを別々に行う場合は、リンク時にも -acc オプションを必要とする。なお、OpenACC 用コンパイル・オプションの詳細については、こちらのページをご参照のこと。以下は、PGI 14.1 以降のオプションを使用した例です。
● Fortranコンパイルの一例
pgfortran -O2 -Minfo=accel -acc test.f90 -o {executable名}
-acc の他に、-ta=tesla or -ta=radeon のサブオプションを付加することも可能
pgfortran -O2 -Minfo=accel -acc -ta=tesla,cuda5.5,cc20,kepler test.f90 -o {executable名}
● C11 コンパイルの一例
pgcc -O2 -Minfo=accel -acc test.c -o {executable名}
-acc の他に、-ta=tesla or -ta=radeon のサブオプションを付加することも可能
pgcc -O2 -Minfo=accel -acc -ta=tesla,cc35,keep test.c -o {executable名}
● C++ コンパイルの一例
pgc++ -O2 -Minfo=accel -acc test.cpp (Linux only GNU g++ ABI互換コンパイラ)
OpenACC プログラム実行時の環境変数
OpenACC の実行モジュール(executable)を実行する際に利用可能な環境変数を以下に示す。
-
ACC_DEVICE_TYPE : ACC_DEVICE_TYPE 環境変数は、プログラムの実行モジュールが一つ以上の異なるデバイスタイプを使用して実行できるように生成されていた場合(PGI Unified Binary)、「アクセラレータ・リージョン」を実行する際に使用するデフォルトのデバイスタイプを指定するものである。この環境変数の値は、コンパイラ・リリースのおける実装時に定義されている。OpenACC 2.0 では、Target device として、NVIDIA GPU、AMD GPU、Intel Xeon Phi Coprocessor が定義されている。2014 年 1 月現在の PGI の実装では、ACC_DEVICE_TYPE として NVIDIA と AMD の RADEON が実装されている。
例:
export ACC_DEVICE_TYPE=NVIDIA
export ACC_DEVICE_TYPE=RADEON
setenv ACC_DEVICE_TYPE NVIDIA
setenv ACC_DEVICE_TYPE RADEON - ACC_DEVICE_NUM : ACC_DEVICE_NUM 環境変数は、「アクセラレータ・リージョン」を実行する際に使用するデフォルトのデバイス番号を指定するものである。環境変数の値は、0~正の整数でなければならない。システム内に複数のGPUデバイスが実装されている場合、その論理番号が 0 から順番に付されて管理されている。pgaccelinfo コマンドを実行すると、各GPUデバイスのロプロパティが論理番号順に表示できる。0 を指定した場合、システム実装時のデフォルトが使用される。
例:
export ACC_DEVICE_NUM=1
setenv ACC_DEVICE_NUM 1 -
ACC_NOTIFY - (PGI 13.10 まで)ACC_NOTIFY 環境変数は、Kernel がアクセラレータ上で実行された際に、そのイベントを標準出力としてショートメッセージで印字するために使用される。環境変数の値は、負の整数であってはなりません。0を指定するとこの機能を抑止する(デフォルト)。0以外の正数の場合は、カーネルを実行する毎に、ショートメッセージを標準出力に印字する。
例:
export ACC_NOTIFY=1
setenv ACC_NOTIFY 1
(メッセージ一例)
launch kernel file=/home/kato/GPGPU/OpenMP/jacobi4.F function=jacobi line=229 device=1 grid=2500 block=128x4 -
PGI_ACC_NOTIFY - (PGI 14.1 以降新設)PGI_ACC_NOTIFY 環境変数は、ビットマスクとして利用する整数定数をセットして、デバイス上の実行イベントの情報を出力するためのものです。整数値 1 をセットすると Kernel launch のイベントを標準出力として出力します。整数値 2 は、データ転送のイベントの出力、整数値 4 の場合は、region の entry/exit 情報、整数値 8 は、デバイス上の wait/sync のイベントを出力します。0を指定するとこの機能を抑止します(デフォルト)。
例:
export PGI_ACC_NOTIFY=2
setenv PGI_ACC_NOTIFY 2
(メッセージ一例)
upload CUDA data file=acc_f2a.f90 function=main line=37 device=0 variable=a bytes=4000000
download CUDA data file=acc_f2a.f90 function=main line=41 device=0 variable=r bytes=4000000 -
PGI_ACC_TIME - PGI_ACC_TIME 環境変数は、実行後に簡易プロファイル情報を標準出力に出力するために使用される。PGI 12.x まで有効であった -ta=time の "time" sub-option は廃止された。環境変数の値は、負の整数であってはなりません。0 を指定するとこの機能を抑止します(デフォルト)。0 以外の正数の場合は、プロファイル情報を標準出力に印字する。(PGI 13.1 以降)なお、Linux の場合、この機能を有効にするには LD_LIBRARY_PATH 環境変数に、PGI のライブラリパスを設定する必要がある。具体的には、64ビット環境では、$PGI/linux86-64/{バージョン番号}/libをセット、32ビット環境では、$PGI/linux86/{バージョン番号}/libをセットして、当該プログラムを実行する。
例:
export PGI_ACC_TIME=1
setenv PGI_ACC_TIME 1 -
PGI_ACC_BUFFERSIZE - (PGI 14.1 以降新設)PGI_ACC_BUFFERSIZE 環境変数は、NVIDIA デバイスにおけるホストとデバイス間のデータ転送で使用される pinned buffer(Pinned memory上)のサイズを指定するものである。
例:
export PGI_ACC_BUFFERSIZE=32M (32MBを指定した場合)
setenv PGI_ACC_BUFFERSIZE 32M - PGI_ACC_CUDA_GANGLIMIT - (PGI 14.1 以降新設)PGI_ACC_CUDA_GANGLIMIT 環境変数は、NVIDIA デバイスにおける、kernel によってラウンチされる gang(CUDA thread block) の最大数を指定するものである。
- PGI_ACC_DEV_MEMORY - (PGI 14.1 以降新設)PGI_ACC_DEV_MEMORY 環境変数は、AMD Radeon デバイスにおける、アロケートされる OpenCL のバッファの最大値を指定するものである。この最大値は、ターゲット・デバイスによって制限される場合がある。
ディレクティブのフォーマット
C、C++ では、OpenACC ディレクティブは、#pragma を使って指定される。その指定方法は以下の形をとる。directive-name(構文名)は必ず一つ指定すること。その後の clause(節)は任意で指定することが可能で、複数の clause を指定する場合はカンマあるいは空白で区切る。clause(節)とは、構文の細かな機能を指定するためのオプションと考えれば良い。なお、以下に記載している「構造化ブロック」の意味については、こちらを参照のこと。
#pragma acc directive-name [clause(節) [[,] clause]…]
{
構造化ブロック
}
(一例)
#pragma acc kernels copy(a)
for( int j = 1; j < n-1; j++)
{
.....
}
Fortran では、OpenACC ディレクティブは、!$acc を使って指定される。その指定方法は以下の形をとる。! は、Fortran 言語のコメント用のプリフィックスである。これを先頭に付けて "!$acc" は一つの単語として指定する。この文字の間に空白を入れてはならない。なお、Fortran の自由形式で記述されたプログラムの場合、"!$acc" の前が空白かタブである限り、どのカラムから記述を開始しても良い。
72 カラム固定形式で記述されたプログラムの場合は、"!$acc"、"c$acc"、"*$acc" のいずれかを 1~5 カラムまでに記述することが必要である。6 カラム目は継続記述子用のカラムとなる。directive-name(構文名)は必ず一つ指定すること。その後の clause(節)は、任意で指定することが可能で、複数の clause を指定する場合は、カンマあるいは空白で区切る。
!$acc directive-name [clause(節) [[,] clause]…]
構造化ブロック
!$acc end directive-name
(一例)
!$acc kernels copy(a)
do i = 1, n
do j = 1, m
...
end do
end do
!$acc end kernels
72カラム固定形式で記述されている場合は、以下の形態となる。
!$acc directive-name [clause [[,] clause]…]
c$acc directive-name [clause [[,] clause]…]
*$acc directive-name [clause [[,] clause]…]
Fortran において OpenACC ディレクティブを継続する場合は、以下のような形態をとる。Fortran では、FORTRAN77 以前の 固定形式(実行文は7カラム目から 72カラム目までと言う書式)と Fortran90 以降の自由形式の二つの記述書式がある。古いレガシーなプログラムでは、固定形式で記述したプログラムが多いと思うが、この二つの書式の違いによって、アクセラレータ・ディレクティブを「継続」するための書式の書き方が異なる。
一般に、FORTRAN77 スタイルの固定形式の場合は、その継続行の示し方は 6カラム目に任意の文字を入れる方法となる。!$acc のディレクティブでも同様で、その clauses を複数行に渡って定義する場合は、!$acc の継続を行わなければならない。その方法は以下の通り。6カラム目に「継続文字」を入れて、継続することを指示する。ここでは、一例として "+" 文字を継続文字として使っている。
!$acc kernels !$acc+copyin (...) !$acc+copyout(...) 以下のように、7カラム目に空白欄を入れた方が見えやすいかもしれない。 !$acc kernels !$acc+ copyin (...) !$acc+ copyout(...)
一方、Fortran90 以降の自由形式の記述形式の場合は、一般に、継続する際の文字として "&" を使用する。継続する行の前の行の末尾に "&" を入れることで、継続することを指示する。!$acc のディレクティブでも同様で、末尾に "&" を入れると、次の行は継続することを意味する。
!$acc kernels & !$acc copyin (...) & !$acc copyout(...)
PGIコンパイラでは、 固定形式のソースファイルであるか、自由形式のソースファイルかは、.f(.F) の suffix か、.f90 or .f95 等の suffix かによって区別する。.f(.F) の場合だけは、固定形式となる。必ず、72 カラム形式で記述したプログラムでなければならない。.f90 (.F90, F95) の場合は、固定形式あるいは自由形式のどちらの書式であってもソースファイルとして認識する。
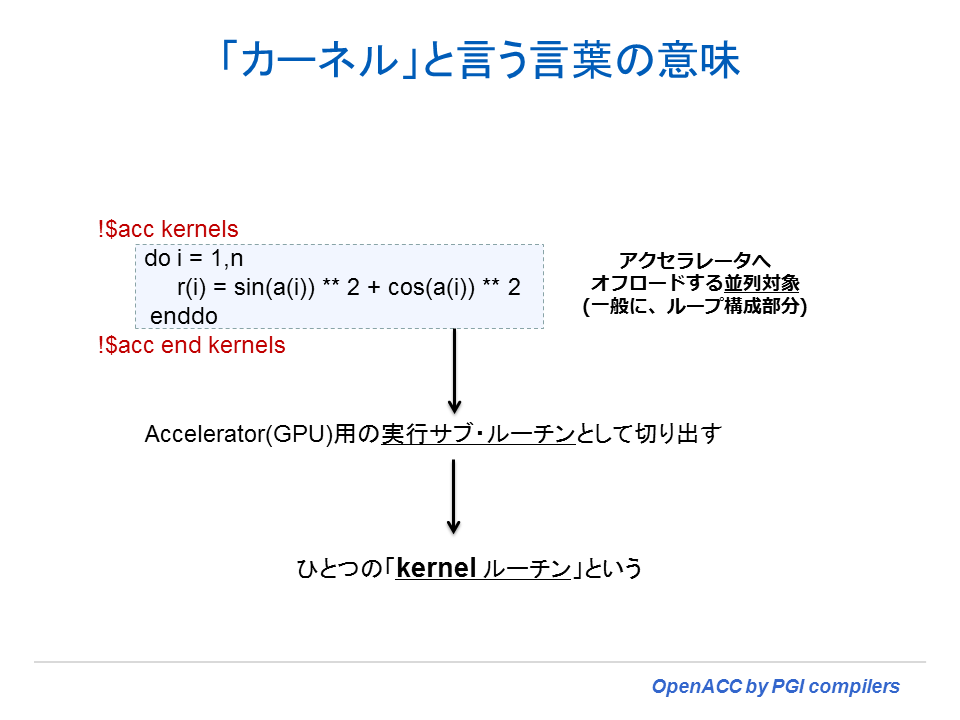
「カーネル」とは
これからの OpenACC ディレクティブの説明の中に、「カーネル」あるいは「カーネルコード」という言葉が頻繁に現れる。この言葉の意味を最初に説明しておく。以下の図で説明しているとおり、「カーネル」とはアクセラレータ側で動作するコードのことを意味する。OpenACC の場合、並列化の対象とする部分は「ループ」であり、この部分をコンパイラは procedure(ルーチン)として切り出し、アクセラレータの並列構造に応じたデバイス・コードとして生成する。
三つのディレクティブ構文を覚える
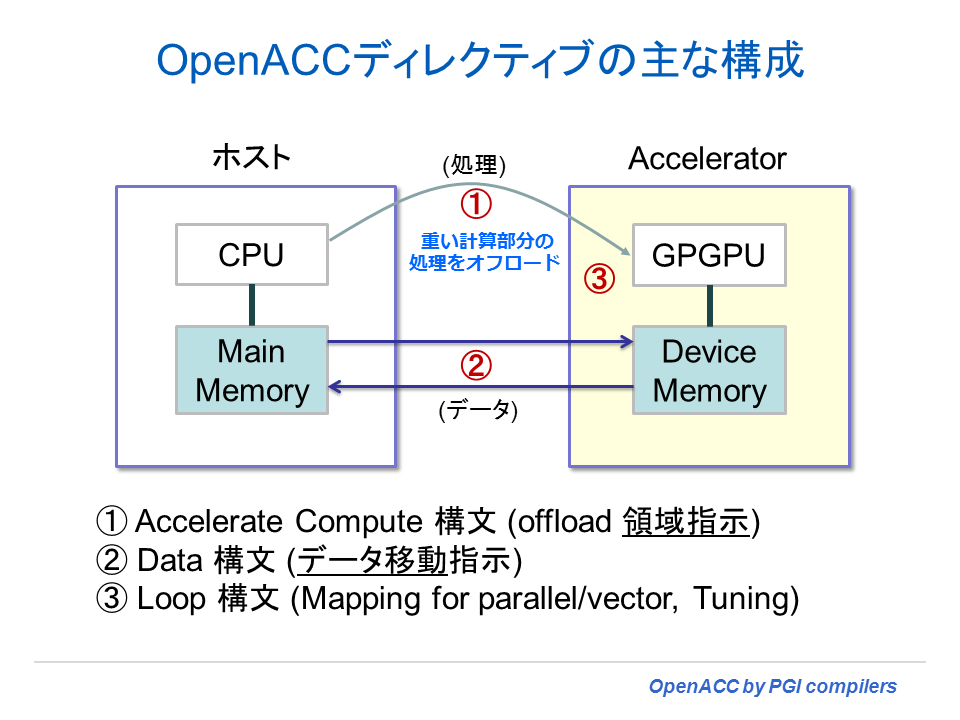
CPUホストからアクセラレータ側に処理をオフロードするために策定された OpenACC ディレクティブの全体像を掴むために、この章では主なディレクティブの機能について概説する。プログラミングの前に、OpenACC ディレクティブとして三つの構文を覚えることから始めることをお勧めする。以下の図を見て欲しい。
①は、Accelerator Compute 構文で、アクセラレータ上にオフロードするループ対象部分を指定するためのディレクティブである。当該対象とするものは、ベクトル化・並列化可能なループであり、ループ文の直前にディレクティブを置くことにより、コンパイラは、自動的にアクセラレータ用の並列化コードを生成する。
②は、Data 構文で、ホストとアクセラレータ間のメモリデータの転送(場所)を明示的に指示するためのディレクティブである。このディレクティブを使って適切な場所でデータ転送を行うようにすることは、OpenACC を使ったプログラミングにおいて最も重要な作業タスクとなる。
③は、Loop 構文で、①の Accelerator Compute 構文で指示したループに対して、当該ループのベクトル長や並列分割の方法をユーザが明示的に指示するために使用される。これを使って並列実行単位をハードウェアの並列演算コアにマッピングする際の分割等の調整を行うことができる。一般的には、性能をチューニングする際に使用する。
ユーザが行うプログラミング・タスクとして、上記の①~③を具体的に述べると以下のようなことになる。
- ① どのループをオフロードの対象とするか?これは、ユーザが行う最初のステップとなる。
- ② データ転送マネージメントを行う。データ転送の指示を行う。データ転送の最小化を行うために必要な措置。
- コンパイラが自動的に行う
- ユーザが明示的に行う
- update 実行文で適宜、アップデート・コピーを行う
- ③ 並列処理の分割方法を明示的に指示する。チューンングを行う目的で使用。
オフロードの対象となるループ構造の形態
アクセラレータ上に処理をオフロードする対象部分に関する概要は、1章において説明した。基本的に「Do / For」ループを対象とするが、そのループ構造はネスティングの状態により以下の図に表すような形態となる。ループ内の処理においてデータ依存性がなければ、OpenACC 並列化の対象とすることが出来る。当該ループ文の直前に OpenACC Accelerator Compute 構文を挿入することにより、コンパイラはアクセラレータ上の並列化コードを作成する。

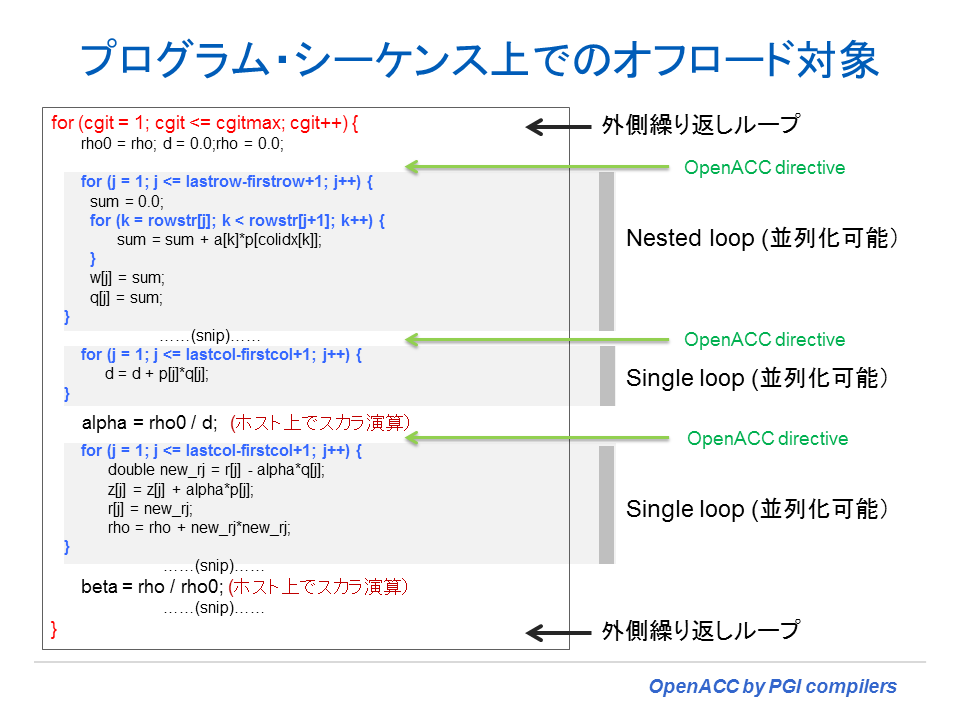
実際のプログラムの流れを例にとり、OpenACC Accelerator Compute 構文を挿入する部分を具体的に示してみよう。以下の図に示したプログラムは、CG 反復法のプログラムを一部切り出したものである。一番外側のループ内に、個々に線形計算を行う並列化可能なループが順番に記述されている。こうした場合は、個々のループの直前に OpenACC Accelerator Compute (kernels や parallel) 構文を挿入する形となる。
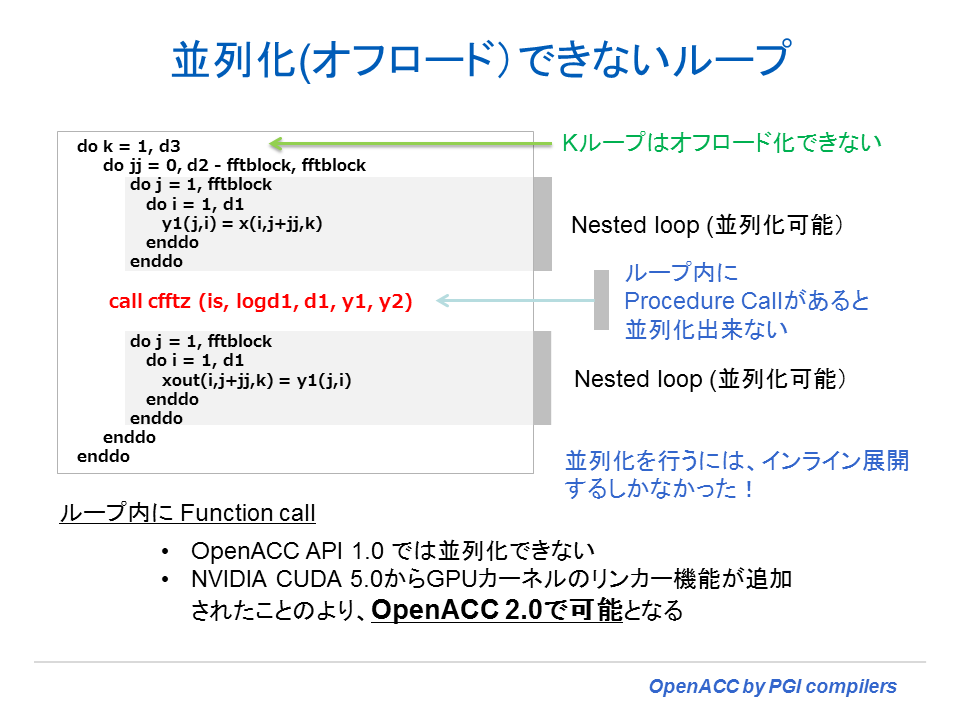
OpenACC 1.0 の仕様においては、ループ内に procedure call が存在する場合、そのループは OpenACC による並列化はできない。例えば、以下の図に示すような形態である。k ループ内には、複数の i と j のネスト・ループが存在しているが、ループ内で cfftz と言うサブルーチンを call している。こうした場合は、OpenACC 1.0 においては、cfftz ルーチンのソース内容をインライン展開して並列化するしかない。しかし、OpenACC 2.0 の仕様では、この制約がなくなる。ループ内部に procedure call があっても OpenACC による並列化が出来るようになる。なお、OpenACC 2.0 に準拠したコンパイラは、PGI の場合、PGI 2014 以降でリリースされる予定である。
① Accelerator Compute 構文
並列化対象となるループの前に、Accelerator Compute 構文を挿入することにより、コンパイラはアクセラレータ用のコードを作成する。下図に、単純なシングルループを有する Fortran プログラムの一部を示した。こうした単純なループは、そもそも CPU 側で処理するよりも遅くなるのが一般的であるが、ここでは単に説明の目的のために使用することにする。以下の例では、Accelerator Compute 構文として kernels 構文を使用している。Fortran の場合は、対象となるループを !$acc kernels ~ !$acc end kernels のディレクティブで囲むだけである。コンパイラはこのヒントをもとに、当該ループのアクセラレータ用の並列コードのみならず、ホスト~アクセラレータ間のデータ転送のためのコードも生成する。最低限、ユーザは Accelerator Compute 構文を指示するだけで、アクセラレータ用のコードを生成することが出来る。以下で説明する ② の Data 構文や ③ の Loop 構文は、必要に応じて指定するものであり、特に Data 構文は、本来「個々のループ本体」に対して指定するために使うものではない。

Accelerator Compute 構文は、以下に示すように「parallel 構文」と「kernels 構文」の二つが用意されている。この機能の違いに関しては、改めて 6 章で説明する。ここでは簡単に説明しておこう。

kernels 構文
- kernels 構文が対象とするループ形態は、基本的に tightly nested loop である。kernels 構文の領域にあるネストループは、アクセラレータ上の(複数の)カーネルのシーケンスに分解される。基本的に各ループネストは、個別のカーネルとなる。プログラムが、kernels 構文に到達すると「カーネル」のシーケンスを順番に実行する形となる。初めて OpenACC によるプログラミングを行う場合は、kernels 構文から使い始めることをお勧めする。
- コンパイラは、自身の自動ベクトル化・並列化技術により(ネスト)ループのベクトル化・並列化解析を詳細に行い、積極的に 3 階層の並列化を試みる。並列化できない場合は、コンパイルメッセージにその旨を出力し、並列化コードを生成せず、デバイス上の(遅い)スカラコード(scaler kernel) を生成する。
- kernels 構文の適用対象は基本的に tightly nested loops であるため、non-tightly なネストループの場合は、並列化コードの生成を行わない場合がある。あるいは、実行結果に影響しない live-out 変数が存在すると、そのままだとコンパイラは並列化を行わない。こうした場合、以下に述べる parallel 構文を利用することができる。
- コンパイラはループ内で「カーネル」を生成する場所を特定し、その並列マッピングを通してループ・スケジューリングを実施する。さらに、ユーザが指定する loop 構文等で、ループ・スケジューリング等を明示的に変更することもできる。
parallel 構文
- parallel 構文が対象とするループ形態は、Non-tightly nested loop を含む全てのループである。コンパイラは当該ループの全体を「シングル・カーネル」コードとして生成する。たとえ、対象としたループの中にネストされた複数のループ存在しても、個々のループのカーネルは作成せず、当該ループ全体を一つのカーネルコードとして作成する。kernels 構文との大きな違いの一つに、まずはこの点が挙げられる。この構文は、OpenMP の parallel 構文とほぼ同じような挙動を想定したものである。すなわち、parallel 構文の時点で、gang 等の並列実行主体が冗長実行を開始し、work-sharing を指示された(ループの)時点で、予め指定されている gang/worker を使って並列処理を行うモデル(「work-sharing モデル」と言う。)である。
- work-sharing モデルにおける parallel 構文は、本来、そのループ対象に並列性を求めているものではない。なぜなら、アクセラレータ内の並列実行主体に対して、単に冗長に同じプログラムを実行させることが parallel 構文の役目だからである。大事なのはプログラム上で work-sharing を行う対象ループ(loop 構文を指定したループ)に到達した時点で並列実行処理されるため、この時点でデータの依存性の存在が問題となる。従って、並列実行で正しい答えを導くためには、ユーザ自身が当該ループ内に並列処理によるデータ依存性がないことを保証して使用することが必要である。もし、仮に依存性が存在してもプログラムの並列処理は実施されるため、この場合、誤った結果を生むことになる。
- parallel 構文は、プログラマの責任による依存性等の詳細な解析を必要とし、parallel 領域内で loop 構文を使用して gang/worker 並列化とベクトル化の指示を明示的に行って使用されるものである。ユーザが loop 構文を指定していない場合のコンパイラの挙動、すなわちコンパイラが自動でベクトル化・並列化解析を行うかどうかは、コンパイラメーカ依存となる。PGI コンパイラのデフォルトの挙動は、ループ内のベクトル化可能なループに対しては常に自動ベクトル化を試みる。しかし、gang/worker 並列化は自動では行われないことに注意する必要がある。従って、parallel 構文内では、loop 構文が明示的に指定されて初めてコンパイラは gang/worker 並列化コードを生成する。
- parallel 構文は、基本的にユーザが、冗長あるいは並列で実行される領域をコンパイラに知らせるためのものであり、loop 構文を使って work-sharing を開始する場所や並列化の分割を含めたループ・スケジューリングもユーザが全て責任を持つ。
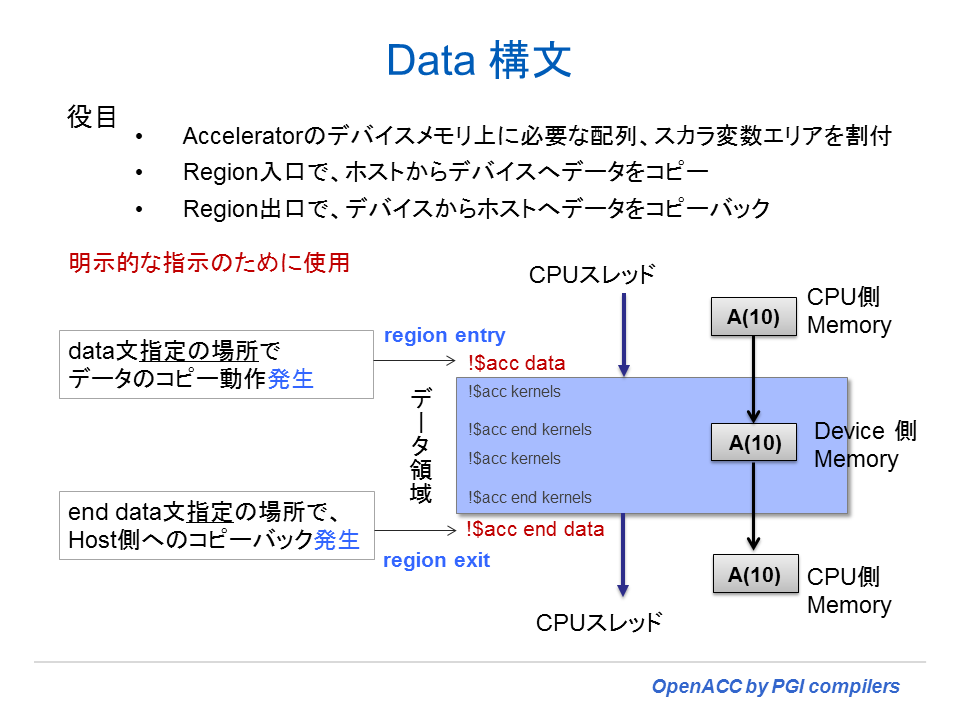
② Data 構文
Data 構文は、前述の通り「個々のループ本体」に対して指定するものではないが、ユーザがデータ転送の指示を「明示的に行う」ためのものであることを示すために、以下の図のシングルループに対しても、あえて data 構文を挿入した様子を示した。この場合、kernels 構文の前に指定する。!$acc data に続いて、データ転送の属性を指示する「clause (節)」を指定する。copyin(a(1:n)) と言う節は、ホスト側からアクセラレータ側へ a 配列の 1 から n までの要素をコピーすることを指示するものである。この copyin 節を指定した場合、!$acc end kernels の時点では、アクセラレータ側の a 配列の内容をホスト側に戻すことは行わない。プログラムを見ての通り、a 配列は、ループ内で参照のみ行われる配列であるため、ホスト側にその値を戻す必要がない。もう一つ、copyout(r) と言う節は、アクセラレータ上に r 配列をアロケートし、計算した結果を格納しているアクセラレータ側の r 配列の全要素の内容をホスト側にコピーせよと言う意味となる。 in と out と言う言葉は、アクセラレータから見ての方向性を意味している。また、単に copy 節で指定した場合は、in/out の両方向でコピーを行うと言う意味となる。

アクセラレータへデータ転送を行うタイミングは、data 構文が指定された時点で行われ、アクセラレータからホスト側へのデータ転送を行うタイミングは、Fortran の場合は、!$acc end data を指定している時点、C/C++ の場合は #pragma acc data のブロック範囲の終了時点で行われる。
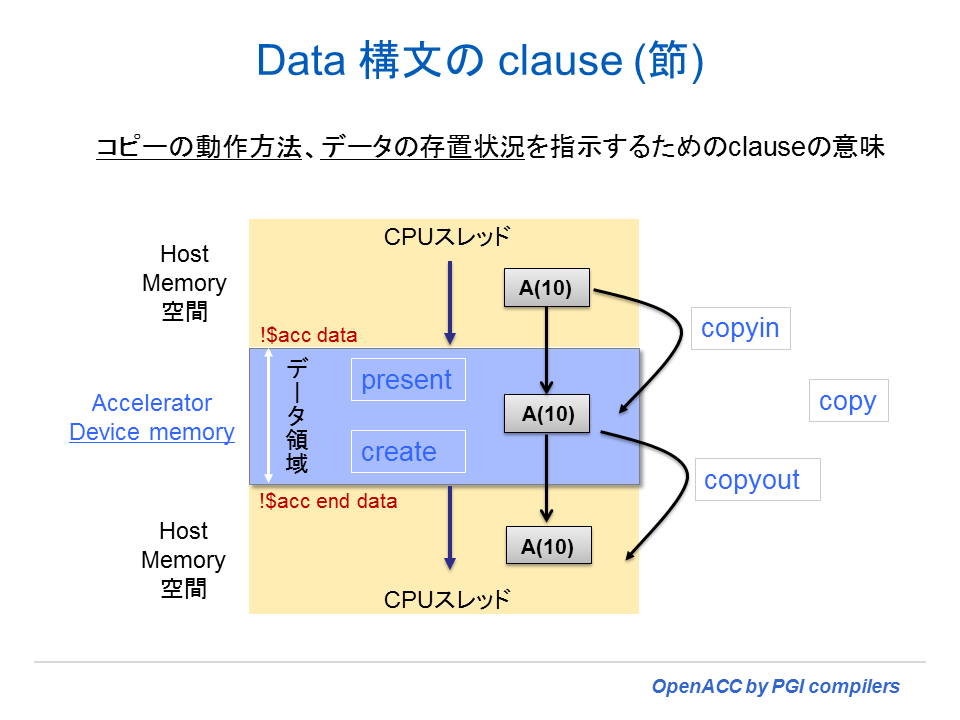
data 構文の節 (clause) には、上述したとおり copy / copyin / copyout 等がある。これらは、二つのメモリ間のデータコピーの転送方向を表すものである。さらに、present と言う節と create と言う節がある。前者の意味は、「すでにデバイスメモリ上にデータは存在しているので、データのコピーは必要ない」と言うことをコンパイラに指示するものである。後者の create 節は、「デバイス側で一時的に使用する配列データであるため、デバイスの上だけで配列をアロケートして使用するものである」と言うことを指示するものである。data 構文はこうした節を指定して、明示的にデータの転送のコントロールや明示的なデータ割付、デバイス上に当該データが存置されているかどうかの確認等の処理を指示するために使用される。
③ Loop 構文
loop 構文は、Accelerator Compute 構文の後に指定する。kernels 構文を使用した場合は任意であるが、parallel 構文を使用した場合は、この loop 構文を指定したループが work-sharing を開始する場所となるため必須となる。この構文は、ループのベクトル長や並列分割の方法等をユーザが明示的に指示するために使用される。work-sharing と言う言葉を初めて聞く人もいるかと思う。この言葉は、OpenMP のプログラミングモデルでも良く使う概念である。これは、「分割した処理を複数の実行主体(スレッド等)が各々分担して、真に並列処理を行う」ことを意味する。OpenMP でも OpenACC でも Parallel リージョンが開始されてから、全ての実行主体が同じプログラムを冗長に実行し始める。その後、loop ディレクティブ等で指定された work-sharing ループに到達した時点で、初めて並列実行のモードとなる。
kernels 構文配下で loop 構文を使用した場合、コンパイラは自動的に並列実行単位をハードウェアの並列演算コアにマッピングするが、プログラムの特性によっては、コンパイラが決めた並列分割の方法やベクトル長の指定が最善ではない場合がある。こうした場合を想定して、ユーザは明示的に並列性能に関わるパラメータを各種「節」を指定して指示できる。下図の中の ③ の !$acc loop gang(32),vector(64) は、gang 分割 32 でベクトルの長さを 64 と言う単位で実行する並列分割を行えと言う意味となる。このディレクティブについては、性能チューニングする際に試行錯誤で gang/vector 値を変えながら、性能変化があるかどうかを確認することをお勧めする。loop 構文の clause の詳細に関しては、後章で説明する。

loop 構文の clause(節)を以下に示す。なお、OpenACC 2.0 において、auto、tile、device_type が追加された。loop 構文の詳細説明は、8 章を参考されたし。

今まで Fortran の例で説明したが、C プログラムの場合は、同じように #pragma を用いたディレクティブの設定を行う。

並列性三階層の定義(OpenACC 2.0以降)
loop 構文の中に、gang、worker, vector と言う clause(節)がある。この三つは、OpenACC の実行モデルの中で使用される「並列性の概念」である。この言葉の意味を説明する前に、一般的なアクセラレータ(NVIDIA に限らない)のハードウェアが備えている parallelism(並列性)の話をしよう。アクセラレータは、2 もしくは 3 つのレベルの並列性に対する実行モードを有している。一つは、ほとんどのアクセラレータがサポートする並列性であるが、「粗粒度の並列性(coarse-grain)」がある。これは、デバイス内に実装されている個々の「実行ユニット」を使って、完全に独立して並列実行を行うモードを言う。但し、粗粒度の並列処理を行っている実行ユニット間では、その同期処理の機能は限定されている。もう一つの並列性として「細粒度の並列性(fine-grain)」があるが、これも多くのアクセラレータがサポートしている。このメカニズムは、一つの実行ユニット内でマルチスレッド実行による方法で実現されている。典型的には長いメモリアクセスの遅延を隠すために、実行するスレッドを頻繁にスイッチすることにより、実行可能なスレッドを常にアクティブにして、実行多重度を増やし、かつ実行ストールを隠す形で実現される。そして三つ目の並列性として、ほとんどのアクセラレータが実装している機能であるが、一つの実行ユニット内で 「SIMD あるいはベクトル処理」をサポートしている。
以下の図は、gang、worker, vector の概念を説明したものである。特に、OpenACC 2.0 の仕様において、これらの概念が明確に定義されたので、ここでは OpenACC 2.0 に準拠した形で説明する。gang は大きなタスク(粗粒度の並列性)のレベルで完全な並列実行を実現する並列単位である。これは、ハードウェア上の同期機構のない「実行ユニット」毎に独立に実行される単位となる。worker は、同期機構のある「実行ユニット」内で細粒度並列性の実行を実現する並列単位とも言える。各 gang は一つ以上の worker を有する。vector は worker 内部で実行される SIMD あるいはベクトル処理のための並列単位となる。
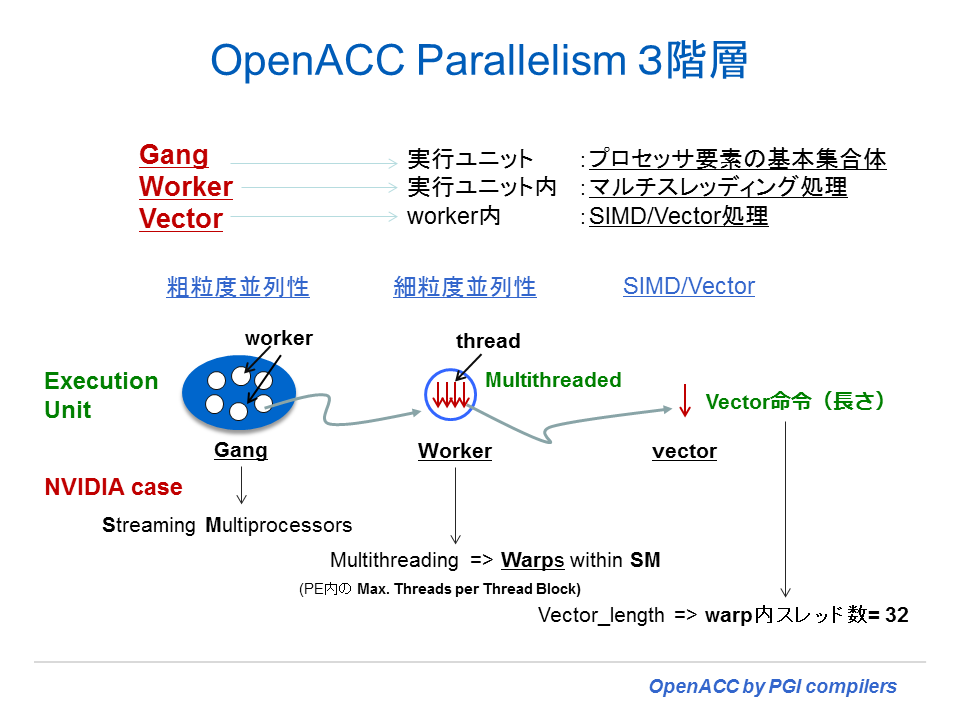
上記のように OpenACC 2.0 において gang, worker, vector の定義を行った場合、実際のプログラム上では、以下に示すように gang はネストループの一番外側で指定する clause となる。また、vector は、一番内側のループで指定できる clause と言うことになる。また、OpenACC 2.0 では、gang ループの内側には、gang clause を含んだループがあってはならない。同様に、worker ループの内側に gang、worker clause のループがあってはならない。さらに、Vector ループの内側には、gang、worker、vector clause のループがあってはならないと言う約束事ができた。OpenACC 1.0 仕様においては、この辺りの定義が曖昧であったため、gang の内側に gang ループがあっても良かった。もし、現在こうしたディレクティブ実装を明示的に行っている場合は、OpenACC 2.0 準拠になってから変更する必要がある。
さらに、OpenACC 2.0 では、gang、worker, vector の実行モードを明確に定義した。これは、OpenACC 1.0 において、parallel 構文における実行モードの定義が曖昧であったために行ったものである。parallel 構文では並列実行時に、gang による「冗長実行(gang redundant = GR mode)」で開始されて、work-sharing を行う loop 構文の実行時点で、gang 並列モード(gang partitioned mode = GP mode) が実行される。gang の場合と同様に worker、vector 実行モードにおいても、同じように worker-single(WS mode) / vector-single(VS mode) と言う言葉で、work-sharing されていない場合の実行モードを表現する。この場合は、一つの worker / vector lane だけがアクティブに実行される。並列に実行するモード、すなわち、work-sharing のモードに移行した場合、worker partitioned mode(WP mode) / vector partitioned mode(VP mode) と言う並列の実行形態となる。
もう少し、具体的に gang~worker~vectorへの partitioned mode に遷移する際の動きを具体的に説明しよう。先に述べたように、gang が冗長実行モード(GR) から work-sharing を行う時点に到達して、並列実行のための GP モードに移行する。但し、その際は、一つの active gang 当たり一つの worker single(WS) でかつ、worker 当たり一つの vector lane だけの動作モードとなっている。これが GP モードの状態となる。
GR モードあるいは GP モードの時に、gang が worker の work-sharing を行うループに到達した時点で、今度は worker レベルの並列実行である WP モードに移行する。この時点で、gang 内の全ての worker がアクティベートされる。各 gang 内の worker によってループを並列分割し実行される。もし、同じループに対して GP と WP の両方が指定されている場合は、全ての gang と worker を使ってループのイテレーションを並列分割して実行される。
もし、worker が vector レベルの work-sharing のループに到達した時、worker は、VP モードに移行する。WP モードと同じように、 VP モードに移行する際に、 worker の全ての vector lane がアクティベートされる。そのループのイテレーションは、ベクトルあるいは SIMD オペレーションを使った vector lane によって並列に分割され実行される。もし、一つのループに対して、gang、worker、vector が指定されている場合は、これらgang、worker、vector の全てを利用した並列分割を実施して実行する。
そして、OpenACC における「アクセラレータのスレッド(thread)」という言葉の定義であるが、これは、「a single vector lane of a single worker of a single gang 」とされている。すなわち、一つの gang 内の一つの worker 内にある一つの vector レーンの実行体を thread として定義されている。

例題のコンパイルと実行
上記で使用したプログラムを以下に示した。同じプログラムを kernels 構文で実装した場合と parallel 構文で実装した場合の例を示す。
| 内容 | C | Fortran |
|---|---|---|
| kernels 構文で実装 | c2.c | f2.f90 |
| parallel 構文で実装 | c2-parallel.c | f2-parallel.f90 |
| C プログラム用ヘッダーファイル | timer.h | -- |
なお、Winodws 環境の C コンパイラでコンパイルする場合は、時間計測関数を変更するためコンパイルオプションに "-DWIN32" を付けてコンパイルする必要がある。Fortran の場合はその必要はない。
(Windows の場合) $ pgcc -O2 -DWIN32 -acc -Minfo=accel c2.c
以下は、kernels 構文を用いた Fortran のプログラム例である。太字で示した kernels 構文だけしか挿入していない。data 構文や loop 構文は、コンパイラが自動的に設定するため、ここではあえて明示していない。
program main
use accel_lib
integer :: n ! size of the vector
real,dimension(:),allocatable :: a ! the vector
real,dimension(:),allocatable :: r ! the results
real,dimension(:),allocatable :: e ! expected results
integer :: i
integer :: c0, c1, c2, c3, cgpu, chost
character(10) :: arg1
if( iargc() .gt. 0 )then
call getarg( 1, arg1 )
read(arg1,'(i10)') n
else
n = 100000
endif
if( n .le. 0 ) n = 100000
allocate(a(n))
allocate(r(n))
allocate(e(n))
do i = 1,n
a(i) = i*2.0
enddo
call acc_init( acc_device_nvidia )
call system_clock( count=c1 )
!$acc kernels
do i = 1,n
r(i) = sin(a(i)) ** 2 + cos(a(i)) ** 2
enddo
!$acc end kernels
call system_clock( count=c2 )
cgpu = c2 - c1
do i = 1,n
e(i) = sin(a(i)) ** 2 + cos(a(i)) ** 2
enddo
call system_clock( count=c3 )
chost = c3 - c2
! check the results
do i = 1,n
if( abs(r(i) - e(i)) .gt. 0.000001 )then
print *, i, r(i), e(i)
endif
enddo
print *, n, ' iterations completed'
print *, cgpu, ' microseconds on GPU'
print *, chost, ' microseconds on host'
end program
コンパイルをしてみる。-acc オプションとコンパイル情報を出力するためのオプション -Minfo=accel を指定する。コンパイル・コマンドを実行するとアクセラレータ関係のみのメッセージが出力される。以下の中で、赤字のメッセージに着目して欲しい。データの転送に関するメッセージとループが並列化されて「Accelerator kernel generated」というメッセージを見ることが出来る。並列化出来ない場合は、その理由と「Accelerator scaler kernel generated」と言うメッセージが出力される。これは、スカラ実行のカーネルコードは生成したが、「遅い」コードであることを意味しているので、アクセラレータ用のコードではないと認識して欲しい。なお、並列化が実施された場合は、「26, !$acc loop gang, vector(128)」と言った並列マッピングに関するメッセージも必ず確認して欲しい。この例では、gang 並列を実施して、その中で vector(ベクトル化)が実施されるコードを生成したことを表している。すなわち、2階層の並列性を利用している。一般に、アクセラレータの性能を最大限活かすためには、こうした 2 階層以上の並列性を利用したコードの生成が必要である。
[kato@photon29 ACC]$ pgfortran -o f2.exe f2.f90 -acc -Minfo=accel -fast
main:
25, Generating present_or_copyin(a(1:n))
Generating present_or_copyout(r(1:n))
Generating NVIDIA code
Generating compute capability 1.0 binary
Generating compute capability 2.0 binary
Generating compute capability 3.0 binary
26, Loop is parallelizable
Accelerator kernel generated
26, !$acc loop gang, vector(128) ! blockidx%x threadidx%x
実行をしてみよう。このプログラムは引数に「ループの繰り返し数」を指定できるようにしている。これを変更して GPU 上と CPU 上での実行時間を比べて見る。繰り返し数を増やしていくと GPU 時間と CPU 時間が逆転することが分かる。計算量が多くなればなるほど、GPU 向きのコードとなっていくことが分かる。
[kato@photon29 ACC]$ f2.exe
100000 iterations completed
25169 microseconds on GPU
1352 microseconds on host
[kato@photon29 ACC]$ f2.exe 1000000
1000000 iterations completed
25976 microseconds on GPU
34451 microseconds on host
[kato@photon29 ACC]$ f2.exe 10000000
10000000 iterations completed
50063 microseconds on GPU
557515 microseconds on host
以下の例は、C プログラムで kernels 構文を利用した場合のプログラムである。Fortranの場合と同じように、一連の出力例を以下に示す。
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <math.h>
#include <accelmath.h>
#include <openacc.h>
#include "timer.h"
int main( int argc, char* argv[] )
{
int n; /* size of the vector */
float *restrict a; /* the vector */
float *restrict r; /* the results */
float *restrict e; /* expected results */
float s, c;
struct timeval t1, t2, t3;
double cgpu, chost;
int i;
if( argc > 1 )
n = atoi( argv[1] );
else
n = 100000;
if( n <= 0 ) n = 100000;
a = (float*)malloc(n*sizeof(float));
r = (float*)malloc(n*sizeof(float));
e = (float*)malloc(n*sizeof(float));
for( i = 0; i < n; ++i ) a[i] = (float)(i+1) * 2.0f;
/*acc_init( acc_device_nvidia );*/
StartTimer();
#pragma data copyin(a[0:n]), copyout(r)
{
#pragma acc kernels
#pragma acc loop gang, vector(128)
for( i = 0; i < n; ++i ){
s = sinf(a[i]);
c = cosf(a[i]);
r[i] = s*s + c*c;
}
}
cgpu = GetTimer();
StartTimer();
cgpu = (t2.tv_sec - t1.tv_sec)*1000000 + (t2.tv_usec - t1.tv_usec);
for( i = 0; i < n; ++i ){
s = sinf(a[i]);
c = cosf(a[i]);
e[i] = s*s + c*c;
}
chost = GetTimer();
chost = (t3.tv_sec - t2.tv_sec)*1000000 + (t3.tv_usec - t2.tv_usec);
/* check the results */
for( i = 0; i < n; ++i )
assert( fabsf(r[i] - e[i]) < 0.000001f );
printf( "%13d iterations completed\n", n );
printf( "%13g microseconds on GPU\n", cgpu*1000 );
printf( "%13g microseconds on host\n", chost*1000 );
return 0;
}
[kato@photon29 ACC]$ pgcc -o c2.exe c2.c -acc -Minfo=accel -fast
main:
34, Generating present_or_copyout(r[0:n])
Generating present_or_copyin(a[0:n])
Generating NVIDIA code
Generating compute capability 1.0 binary
Generating compute capability 2.0 binary
Generating compute capability 3.0 binary
36, Loop is parallelizable
Accelerator kernel generated
36, #pragma acc loop gang, vector(128) /* blockIdx.x threadIdx.x */
[kato@photon29 ACC]$ c2.exe
100000 iterations completed
183329 microseconds on GPU
1437 microseconds on host
[kato@photon29 ACC]$ c2.exe 1000000
1000000 iterations completed
179438 microseconds on GPU
33796 microseconds on host
[kato@photon29 ACC]$ c2.exe 10000000
10000000 iterations completed
200065 microseconds on GPU
560842 microseconds on host
OpenACC へのポーティング時の心得
OpenACC を適用する際の作業心得を以下に示すが、段階的に OpenACC の適用範囲を広げていくことをお勧めする。
- 一番最初は、kernels 構文を使って、非常に小さなループ範囲でその適用を試みる。コンパイラコマンドに、
-Minfo=accel オプションを付加して、コンパイラが適用部分に対して「並列化」が実施されているかを必ず確認する。kernels 構文の対象としたループの行番号に対して、以下のような並列化のメッセージが現れていることを確認する。重要なことは、「Accelerator kernel generated」と「!$acc loop gang, vector(xxx)」等の並列マッピング情報が示されていることである。なお、「Loop is parallelizable」と言うメッセージは、並列化が可能であると言うことをコンパイラが認識したメッセージであり、「並列化 kernel コードを生成した」と言うことではないため注意が必要である。
Loop is parallelizable Accelerator kernel generated !$acc loop gang, vector(128) ! blockidx%x threadidx%x以下のメッセージは、並列化されていないメッセージであるため、上記と混同しないようにして欲しい。
Accelerator scaler kernel generated
- もう一つ、コンパイラメッセージの中で確認しておきたいことがある。kernels 構文もしくは parallel 構文を設定すると、自動的に当該ループ内で使用される変数、配列のデータ転送処理のコードも生成される。特に配列のデータ転送に関しては、以下のような形でメッセージ(一例)が出力される。ホスト側のメモリとデバイス側のメモリ間でコピーされる配列を列挙してくれるため、今後、data 構文で、データ転送の最適化を実施する時に参考となる。
Generating present_or_copyin(a(1:n)) Generating present_or_copyout(r(1:n)
- 次に、確認するべきことはアクセラレータを使った実行処理の結果が、CPU 上で実施した結果と差異はないかどうかを確認する。これは、Accelerate Compute 構文を追加する度に行う方が良い。後で纏めて行うと、もし誤った結果が出た場合、どこの部分が問題であったかを直ぐ把握できなくなる。
- もう一つ、アクセラレータ上でのカーネルの実行性能も把握しておく必要がある。実行時、簡易プロファイルを行っておき、その結果を常に見るように心がける。簡易プロファイルを取得する方法は二つある。一つは、以下の環境変数を予め実行前にセットする。これによって、実行時に常にプロファイル結果が出力される。
$ export PGI_ACC_TIME=1 (Linux / Windows cygwin/ OS X シェル) $ set PGI_ACC_TIME=1 (Windows のコマンドプロンプト 環境セット) コンパイラが生成した個々のカーネルの実行プロファイルの結果が表示される。 $ ./c2.exe (実行) Accelerator Kernel Timing data .../c2.c main NVIDIA devicenum=0 time(us): 428 34: compute region reached 1 time (34行目で compute 領域の開始) 34: data copyin reached 1 time device time(us): total=83 max=83 min=83 avg=83 (デバイスへのデータコピーの時間) 36: kernel launched 1 time grid: [782] block: [128] (36行目のループを並列化、gridサイズ 782 で、 thread-block が128の並列) device time(us): total=273 max=273 min=273 avg=273 elapsed time(us): total=282 max=282 min=282 avg=282 (実行時間が total 292マイクロ秒) 41: data copyout reached 1 time (ホスト側へデータコピーの時間) device time(us): total=72 max=72 min=72 avg=72NVIDIA の GPU の場合は、NVIDIA 社の nvprof と言うコマンドでプロファイル情報を得ることもできる。
$ nvprof c2.exe 10000000(実行) ==24944== Profiling application: c2.exe ==24944== Profiling result: Time(%) Time Calls Avg Min Max Name 44.51% 670.50us 1 670.50us 670.50us 670.50us [CUDA memcpy HtoD] 39.79% 599.42us 1 599.42us 599.42us 599.42us [CUDA memcpy DtoH] 15.71% 236.64us 1 236.64us 236.64us 236.64us main_36_gpu
- 以上のように、一つのループに対してアクセラレータ上での実行が正しく処理されることを確認してから、次の候補となるループに対して kernels 構文を適用し、その範囲を広げていく。そして同じように検証を繰り返していく。なお、 kernels 構文で並列化できない Non-tightly nested loop の場合は、 parallel 構文を適用してみる。parallel 構文は、シングル・ループ適用から始め、正しい結果が得たら nested ループへの適用を行って行くスタイルの方が結果的に誤りが少ない作業となる。但し、ここまでのステップは、データ転送に関する最適化を行っていないため、CPU上で実行するよりも時間が掛かる場合がほとんどであろう。
- こうしてある程度の並列化適用が成功したら、次に、データ転送の管理を行う。data 構文を使って、出来るだけ使用するデータをアクセラレータ側で常駐化できるようにマネージメントする。データ移動に関するプロファイル情報を見ながら最適化していく。
- アクセラレータ側で常駐化できるものだけではなく、ホスト側にデータを戻しその上で使用するデータもあるため、こうした場合は、!$acc update(#pragma acc update)実行文を使用して、適宜、一部データの移動をホスト~デバイス間で行う。
[Reference]
- Michael Wolfe, The Portland Group, Inc., OpenACC Features in the PGI Accelerator C Compiler—Part 1
- Michael Wolfe, The Portland Group, Inc., OpenACC Features in the PGI Accelerator Fortran Compiler—Part 1