OpenACC ディレクティブによるプログラミング
8章 Loop 構文
- collapse clause
- gang clause
- worker clause
- vector clause
- seq clause
- auto clause
- tile
- device_type clause
- independent clause
- private
- reduction
loop 構文
loop 構文については、5 章で概要を説明した。loop ディレクティブは、ループを実行する際に使用する並列性のタイプを指定するために使用される他、ループ・プライベートな変数、配列の宣言、リダクション処理を行う変数の指定等を行うためにも使われる。このディレクティブは、直下のループに対して有効である。
以下の例は、loop ディレクティブを挿入した一例である。3 重のネストループのそれぞれが、データの依存性がないこと(independent) をコンパイラに伝えるために使用した例である。

以下の例は、gang と vector clause を使用して、各ループに使用する並列性を指定すると共に、並列分割のサイズを指定した例である。

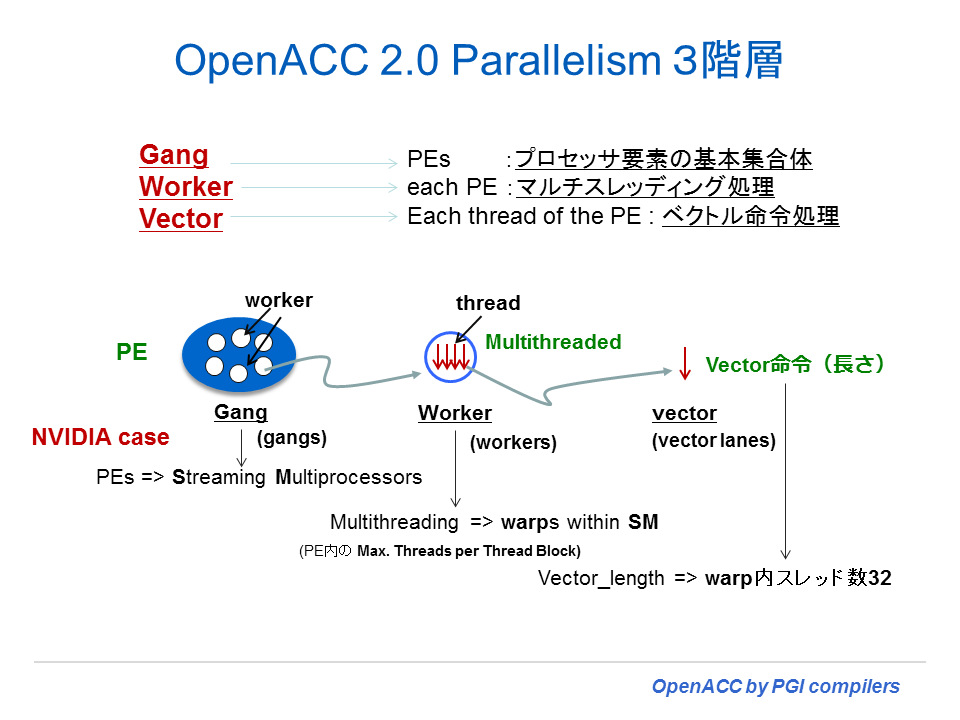
以下の clause の説明では、OpenACC モデルで使用される「並列3階層」、すなわち、gang、worker、vectorの概念が必要となる。これをプログラミングの観点から言うと、(ネスト)ループに対して、どの並列性の階層を適用するかと言うことを考える時のモデルである。「並列 3 階層」に関しては、5 章で説明しているので参照のこと。OpenACC 2.0 規格で、並列 3 階層のモデルが明確に定義された。しかし、一つの注意事項がある。OpenACC 1.0 の PGI の実装では、入れ子のループ構造で、例えば gang で指定したループの内側のループにおいても gang を指定することができた。PGI コンパイラの OpenACC 2.0 準拠以降のバージョンでも、従来通り、内側のループにおいても gang を指定することを許している(PGI extension 機能)。すなわち gang の入れ子となっていたとしても、ユーザ指定が指定したままで認識されコード化される。

loop ディレクティブのシンタックスと clauses(節)
loop 構文のシンタックスと利用可能な clause(節)を以下に示した。
【Syntax】 C and C++の場合 #pragma acc loop [clause-list] new-line for loop Fortranの場合 !$acc loop [clause-list] do loop !$acc end parallel Clause(節)は、次のものを指す collapse( n ) gang [( gang-arg-list )] worker [( [num:] int-expr )] vector [( [length:] int-expr )] seq auto OpenACC 2.0 tile( size-expr-list ) OpenACC 2.0 device_type( device-type-list ) OpenACC 2.0 independent private( var-list ) reduction( operator : var-list ) ここで、 gang-arg は以下のどちらかを指定 OpenACC 2.0 [num:] int-expr static: size-expr gang-arg-list は、少なくとも一つの num か一つの static 引数を持たなければならない また、size-expr は以下のどちらかを指定 * int-expr
以上の clause のいくつかは、parallel 構文内で使用されるもの、あるいは、 kernels 構文内で使用されるものがあるため、詳細は、以下の clause の説明を参照のこと。
制限事項
- collapse, gang, worker, vector, seq, auto と tile clauses は、device_type clause の後に指定すること。
- worker と vector clause の引数値 int-expr は、kernels 領域内では不変値でなければならない。
loop ディレクティブの clauses(節)の説明
collapse (n)
collapse clauseは、tightly なネストループを対象として、下に続く n 番目までのループを一つにまとめて並列化するようにコンパイラに指示するために使用する。引数 n は、正の整数定数とする。この collapse clause の指定がない場合は、直後のループだけに当該 loop ディレクティブの内容が作用する。もし、当該 loop 構文が一つ以上のループをまとめている場合、その全てのループに関するイテレーションに関して、他の clauses の効果を含めてスケジューリングされる。 collapse clauseに関係する全てのループのトリップカウントは、計算が可能で不変式でなければならない。なお、ディレクティブ上の gang、worker、vector 節が各ループに適用されるかどうか、あるいは、collapse による線形化されたイテレーション空間(linearized iteration space of the loops)へ適用されるかどうかは、実装依存となる。
gang [( gang-arg-list )]
Accelerator Parallel 構文による領域内において gang clause が指定された場合について説明する。gang clause は、parallel 構文によって生成される gang 間でループのイテレーションを分割することにより、当該ループのイテレーションが並列に実行されることを指示するものである。gang clause を有する loop 構文は、compute 領域を gang-redundant モード から gang-partitioned モードへ移行するためのタイミングのポイントでもある。gang の数は、parallel 構文の中で制御される(static 引数のみが許される)。当該ループ・イテレーションは、reduction clause で指定された変数を除いて、データ独立でなければならない。gang clause を有したループの領域は、ネストされた parallel あるいは kernels 領域内でない限り、gang clause を有した別のループを含んではならない。
Accelerator kernels 構文による領域内において gang clause が指定された場合について説明する。gang clause は、ループ内部に含まれる任意のカーネルのために生成される gang で、当該ループのイテレーションが並列に実行される指示するものである。もし、キーワードなしの引数、あるいは num キーワードの後の引数が指定されている場合、それは、このループのイテレーションを実行するために使用する gang の数を意味する。gang clause を有するループの領域は、ネストされた parallel あるいは kernels 領域内でない限り、gang clause を有した別のループを含んではならない。
gang に対するループ・イテレーションのスケジューリングは、引数として static 引数が指定されていなければ、指定されることはない。static の引数が整数式で指定されていると、その式は当該ループの(分割)チャンクサイズとして使用される。もし、static の引数にアスタリスク(*) が指定されている場合、コンパイラがチャンクサイズを選択する。「チャンク」とは、一つの gang が処理を行う際のその最小単位となる「ループの反復回数」である。イテレーションは、選択されたチャンクサイズの「チャンク」に分割される。その「チャンク」は、gang 0 から開始し、ラウンド・ロビンで各 gang に割り当てられる。同一の parallel 領域内に同じイテレーション数を持ち、かつ、同じサイズ引数を持つ static clause を有する二つの gang ループがある場合、同じマナーでその gang へのイテレーションを割り当てる。同一の kernels 領域内に同じイテレーション数を持ち、かつ、同じ数の gang を使用し、同じサイズ引数を持つ static clause を有する二つの gang ループがある場合、同じマナーでその gang へのイテレーションを割り当てる。
PGI 13.10 以前のコンパイラは、OpenACC 1.0 準拠のため、gang の引数は scalar-integer-expression となる。これは、使用する gang の数を意味する。
worker [( [num:] int-expr )]
Accelerator Parallel 構文による領域内において、worker clause は一つの gang 内の複数の worker 間でイテレーションを分割することにより、当該ループのイテレーションが並列に実行されることを指示するものである。worker clause を有する loop 構文は、gang を worker-single モード から worker-partitioned モードへ移行させる。gang clause とは対照をなして、worker clause は最初に追加する worker-level 並列実行体をアクティベートし、そして、これらの worker 間でループ・イテレーションを分割するように働く。worker clause は引数無しの指定は許されない。当該ループ・イテレーションは、reduction clause で指定された変数を除いて、データ独立でなければならない。worker clause を有したループの領域は、ネストされた parallel あるいは kernels 領域内でない限り、gang あるいは worker clause を有したループを含んではならない。
Accelerator kernels 構文による領域内において、worker clause は、ループ内部に含まれる任意のカーネルのために生成される gang 内にある worker 間で、当該ループのイテレーションが並列に実行される指示するものである。もし、引数が指定されたら、それは、このループのイテレーションを実行するために使用する gang 当たりの worker の数を意味する。worker clause を持つループの領域は、ネストされた parallel あるいは kernels 領域内でない限り、gang あるいは worker clause を有したループを含んではならない。 全ての worker は、任意の worker がループの終点を終えて次に進む前に、割り当てられたイテレーションの実行を全て完了する。
PGI 13.10 以前のコンパイラは、OpenACC 1.0 準拠のため、worker の引数は scalar-integer-expression となる。これは、使用する worker の数を意味する。
vector [( [length:] int-expr )]
Accelerator Parallel 構文による領域内において、vector clause は、当該ループのイテレーションが、ベクトルあるいは SIMD モードで実行されることを指定するものである。vector clause を有する loop 構文は、worker に vector-single モードから vector-partitioned モードに移行させる。worker clause と同じように、vector clause は最初に追加する vector-level 並列実行体をアクティベートし、そして、これらの vector レーン間でそのループ・イテレーションを分割する働きをする。このオペレーションは、当該並列領域のために選択、あるいは指定されたベクトル長を用いて実行される。vector clause を持つループの領域は、ネストされた parallel あるいは kernels 領域内でない限り、gang あるいは work あるいは vector clause を有したループを含んではならない。
Accelerator kernels 構文による領域内において、vector clause は、当該ループのイテレーションが、ベクトルあるいは SIMD モードで実行されることを指定するものである。引数が指定されている場合、そのイテレーションは、そのベクトル長を単位としてストリップ・マイニング(分割)して処理される。引数が指定されていない場合は、コンパイラが適切なベクトル長を選択する。vector clause を持つループの領域は、ネストされた parallel あるいは kernels 領域内でない限り、gang あるいは work あるいは vector clause を有したループを含んではならない。
全ての vectorレーンは、任意の vector レーンがループの終点を終えて次に進む前に、割り当てられたイテレーションの実行を全て完了する。
PGI 13.10 以前のコンパイラは、OpenACC 1.0 準拠のため、vector の引数は scalar-integer-expression となる。これは、ベクトル長を意味する。
seq
seq clause は、当該ループがアクセラレータによって、シーケンシャルに実行されることを指定するものである。この clause は自動並列化、あるいはベクトル化を無効にする。
auto (OpenACC 2.0、PGI 15.1以降)
auto clause は、コンパイラがこのループに対して gang、worker、vector 並列性を適用出来るかどうかを選択することを指定するものである。外側あるいは内側ループに対して gang、worker あるいは、vector clauses を有する loop ディレクティブの存在によっては、コンパイラは適用できる並列性のタイプが制限されるかもしれない。この clause は、それ自身でそのループ・イテレーションは独立であると言うことをコンパイラに伝える訳ではない。従って、ループに independent clause が指定されていない限り、コンパイラは任意の並列性を適用出来ない。あるいは、ループが parallel 構文内にあるため、暗黙にデータ独立であることが自明な場合、あるいは、コンパイラがループを解析することが出来て、そのループ・イテレーションがデータ独立であることを決めることが出来る場合は、auto clause の機能を実施することが出来る。kernels 構文では、 gang、worker、vector あるいは seq clause 有していないloop ディレクティブは、デフォルトで auto clause を持つものとして扱われる。
tile( size-expr-list ) (OpenACC 2.0、PGI 15.1以降)
tile clause は、tightly nested loop に対して loop tiling を行うように指示するためのものである。すなわち、入れ子ループの中の各ループを、tile ループの外側のセットと、element ループとしての内側のセットを備えた形で二つに分割することをコンパイラに指示するものである。tile clause の引数は、一つ以上のタイルサイズのリストを指定するが、各タイルサイズは正の整数定数かアスタリスクで指定する。もし、そのリスト上に “n” tile size が指定されているとしたら、その loop ディレクティブの後に “n” tightly-nested ループ が続かなければならない。size-expr-list の最初の引数は、当該ループの最内側のループに対応し、次の引数は外側ループに対するものとなる。もし、タイルサイズがアスタリスクで指定されていたら、コンパイラが適切な値を選択する。入れ子の各ループは外側 tile ループと内側 element ループの二つに分離あるいはストリップマインされる。element ループのトリップカウントは size-expr-list の tile サイズに応じて制限される可能性がある。tile ループは、全ての element ループの外側になるために順序が入れ替わる可能性もある。そして、element ループは全て、tile ループの内側に置かれることになる。
もし、vector clause が loop ディレクティブ上に指定されている場合、vector clause は element ループに適用される。gang clause が loop ディレクティブ上に指定されている場合、gang clause は tile ループに適用される。もし、worker clause が loop ディレクティブ上に指定されている場合で vector clause がない時、worker clause は element ループに適用される。それ以外は、tile ループに適用される。

device_type clause( device-type-list ) (OpenACC 2.0)
device_type clauseは、 6 章を参照のこと。
independent
Accelerator kernels 構文内では、independent clause はコンパイラに対して、このループのイテレーションは、互いにデータ独立であることを知らせるために使用する。これは、コンパイラは、同期無しに並列でイテレーションを実行するコードを生成する。Accelerator parallel 構文内では、independent clause は seq clause を有していない全ての loop ディレクティブ上でデータ独立であることを暗黙に宣言する意味合いを持つ。
【制限事項】
reduction clause 内の変数を除いて、任意の変数あるいは配列要素が他のイテレーションから参照されたり更新されたりするような状況が存在する場合、kernel 構文上のループに対して independent clause を使用することはプログラミング・エラーである。
private( var-list )
loop ディレクティブ上の private clause は var-list 上の項目(変数、配列)のコピーを当該ループのイテレーションを実行する各スレッド用に生成することを指示するために使用する。
reduction( operator : var-list )
reduction clause には、リダクション・オペレータと一つ以上の変数を指定する。各リダクション変数に対して、当該ループのイテレーションを実行する各スレッド用のプライベートなコピーが生成される。そして、それはそのオペレータ用に初期化される。このオペレータの種別は、以下の表に示した。ループの終点で各スレッドの値が指定されたリダクション・オペレータによって集約され、その結果は、parallel あるいは kernels 領域の最後の時点でオリジナルの変数にストアされる。
parallel 構文の領域では、もし、reduction clause が vector あるいは worker clause を持つループ上(gang clause を有する ループでは使用できない)で使用されており、そのスカラ変数がparallel 構文の private clause で指定されている場合、そのスカラのプライベートな値がループの終点で更新される。もし、そのスカラ変数が parallel 構文の private clause で指定されていない場合、あるいは、reduction clause が gang clause を有するループ上で使用されている場合、そのスカラの値は、「Parallel 領域の終点」まで更新されない。
制限事項
- リダクション変数は 配列の要素であってはならない。
- リダクション変数は、Cの構造体メンバ、 C++ のクラスあるいは構造体メンバ、Fortran の派生型メンバであってはならない。
- gang clause を有する Orphaned loop内のリダクション操作(reduction clauseの使用)は、OpenACC 2.5 から明確に禁止されましため、その実装となりました。なお、routine gang clause を有した形でコンパイルされた手続き内で gang 並列性を生成するような orphaned loop も同様です。
C and C++ Fortran
-----------------------------------------------------------
operator initialization operator initialization
value value
-----------------------------------------------------------
+ 0 + 0
* 1 * 1
max least max least
min largest min largest
& ~0 iand all bits on
| 0 ior 0
^ 0 ieor 0
&& 1 . and. .true.
|| 0 .or. .false.
.eqv. .true.
.neqv. .false
----------------------------------------------------------
リダクションの指定の例 !$acc loop vector(256) reduction( + :sum) do i= 1, n sum = sum + a(i) end do
姫野ベンチマークへの適用(Fortran)
kernels 構文を用いる場合
姫野ベンチマークを例題に、実際に OpenACC kernels ディレクティブを適用した例をソースプログラムと共に提供する。Main プログラム上で Data 領域を設定して、サブルーチン jacobi の中で kernels ディレクティブ並びに loop ディレクティブを適用している。ここでは詳細な説明は割愛するが、ソースプログラムを見て、実際の OpenACC ディレクティブの使用法の感触を得て欲しい。ここでは、PGI 13.10 (2013年版)バージョンを使用して、Linux上で NVIDIA tesla K20c を使用した際の例である。なお、実行時のデータサイズは、M サイズを使用し、その性能を例示した。
ソースプログラム: himenobench_kernels.F90
$ pgaccelinfo CUDA Driver Version: 5050 NVRM version: NVIDIA UNIX x86_64 Kernel Module 319.37 Device Number: 0 Device Name: Tesla K20c Device Revision Number: 3.5 Global Memory Size: 5368512512
( 362) !$acc data present(a,b,c, p, bnd) & ( 363) !$acc present (wrk1,wrk2) ( 364) ( 365) do loop=1,nn ( 366) gosa = 0.0 ( 367) ( 368) !$acc kernels ( 369) !$acc loop gang ( 370) do k=2,kmax-1 ( 371) do j=2,jmax-1 ( 372) !$acc loop vector(256) reduction( + :gosa) ( 373) do i=2,imax-1 ( 374) s0=a(I,J,K,1)*p(I+1,J,K) & ( 375) +a(I,J,K,2)*p(I,J+1,K) & ( 376) +a(I,J,K,3)*p(I,J,K+1) & ( 377) +b(I,J,K,1)*(p(I+1,J+1,K)-p(I+1,J-1,K) & ( 378) -p(I-1,J+1,K)+p(I-1,J-1,K)) & ( 379) +b(I,J,K,2)*(p(I,J+1,K+1)-p(I,J-1,K+1) & ( 380) -p(I,J+1,K-1)+p(I,J-1,K-1)) & ( 381) +b(I,J,K,3)*(p(I+1,J,K+1)-p(I-1,J,K+1) & ( 382) -p(I+1,J,K-1)+p(I-1,J,K-1)) & ( 383) +c(I,J,K,1)*p(I-1,J,K) & ( 384) +c(I,J,K,2)*p(I,J-1,K) & ( 385) +c(I,J,K,3)*p(I,J,K-1)+wrk1(I,J,K) ( 386) ss=(s0*a(I,J,K,4)-p(I,J,K))*bnd(I,J,K) ( 387) gosa= gosa + ss*ss ( 388) wrk2(I,J,K)=p(I,J,K)+OMEGA *SS ( 389) enddo ( 390) enddo ( 391) enddo ( 392) ( 393) !$acc loop gang ( 394) do k=2,kmax-1 ( 395) do j=2,jmax-1 ( 396) !$acc loop vector(256) ( 397) do i=2,imax-1 ( 398) p(I,J,K)=wrk2(I,J,K) ( 399) enddo ( 400) enddo ( 401) enddo ( 402) !$acc end kernels ( 403) ( 404) enddo ( 405) ( 406) !$acc end data
$ pgfortran -Minfo=accel -acc -O -Mvect=sse -ta=nvidia,cuda5.5 (下に続く)
himenobench_kernels.F90 -o kernels.exe
(前略)
jacobi:
362, Generating present(wrk2(:,:,:))
Generating present(wrk1(:,:,:))
Generating present(bnd(:,:,:))
Generating present(p(:,:,:))
Generating present(c(:,:,:,:))
Generating present(b(:,:,:,:))
Generating present(a(:,:,:,:))
..(snip)..
370, Loop is parallelizable
371, Loop is parallelizable
373, Loop is parallelizable
Accelerator kernel generated
370, !$acc loop gang ! blockidx%y
373, !$acc loop gang, vector(256) ! blockidx%x threadidx%x
394, Loop is parallelizable
395, Loop is parallelizable
397, Loop is parallelizable
Accelerator kernel generated
394, !$acc loop gang ! blockidx%y
397, !$acc loop gang, vector(256) ! blockidx%x threadidx%x
実行結果は以下の通りである。
$ ./kernels.exe The loop will be excuted in 800 times. This will take about one minute. Wait for a while. Loop executed for 800 times Gosa : 8.3822053E-04 MFLOPS: 43383.55 time(s): 2.528242000000000 Score based on Pentium III 600MHz : 523.7029 FORTRAN PAUSE: enteror d to continue> Accelerator Kernel Timing data himenobmtxp_f90 NVIDIA devicenum=0 time(us): 2,701 99: data region reached 1 time 139: data copyout reached 2 times device time(us): total=2,701 max=2,632 min=69 avg=1,350 ..(snip).. jacobi NVIDIA devicenum=0 time(us): 2,466,175 362: data region reached 2 times 368: compute region reached 803 times 373: kernel launched 803 times grid: [1x126] block: [256] device time(us): total=2,237,368 max=2,850 min=2,645 avg=2,786 elapsed time(us): total=2,244,492 max=2,860 min=2,653 avg=2,795 373: reduction kernel launched 803 times grid: [1] block: [256] device time(us): total=7,882 max=36 min=9 avg=9 elapsed time(us): total=15,522 max=46 min=18 avg=19 397: kernel launched 803 times grid: [1x126] block: [256] device time(us): total=220,925 max=333 min=268 avg=275 elapsed time(us): total=228,340 max=404 min=277 avg=284
parallel 構文を用いる場合
kernels 構文ではなく、parallel 構文を使用した場合のディレクティブの使用例を以下に示す。parallel 構文は、対象となるループは、コンパイラがデータ依存性解析は行わないため、データ独立でなければならない。なお、このプログラムの中では、一部、OpenACC の複合ディレクティブ を使用している。
ソースプログラム: himenobench_parallel.F90
( 362) !$acc data present(a,b,c, p, bnd) &
( 363) !$acc present (wrk1,wrk2)
( 364)
( 365) do loop=1,nn
( 366) gosa = 0.0
( 367)
( 368) !$acc parallel loop collapse(3) reduction( + :gosa) 複合ディレクティブ 第9章参照
( 369) do k=2,kmax-1
( 370) do j=2,jmax-1
( 371) do i=2,imax-1
( 372) s0=a(I,J,K,1)*p(I+1,J,K) &
( 373) +a(I,J,K,2)*p(I,J+1,K) &
( 374) +a(I,J,K,3)*p(I,J,K+1) &
( 375) +b(I,J,K,1)*(p(I+1,J+1,K)-p(I+1,J-1,K) &
( 376) -p(I-1,J+1,K)+p(I-1,J-1,K)) &
( 377) +b(I,J,K,2)*(p(I,J+1,K+1)-p(I,J-1,K+1) &
( 378) -p(I,J+1,K-1)+p(I,J-1,K-1)) &
( 379) +b(I,J,K,3)*(p(I+1,J,K+1)-p(I-1,J,K+1) &
( 380) -p(I+1,J,K-1)+p(I-1,J,K-1)) &
( 381) +c(I,J,K,1)*p(I-1,J,K) &
( 382) +c(I,J,K,2)*p(I,J-1,K) &
( 383) +c(I,J,K,3)*p(I,J,K-1)+wrk1(I,J,K)
( 384) ss=(s0*a(I,J,K,4)-p(I,J,K))*bnd(I,J,K)
( 385) gosa= gosa + ss*ss
( 386) wrk2(I,J,K)=p(I,J,K)+OMEGA *SS
( 387) enddo
( 388) enddo
( 389) enddo
( 390) !$acc end parallel loop
( 391)
( 392) !$acc parallel vector_length(128)
( 393) !$acc loop collapse(3)
( 394) do k=2,kmax-1
( 395) do j=2,jmax-1
( 396) do i=2,imax-1
( 397) p(I,J,K)=wrk2(I,J,K)
( 398) enddo
( 399) enddo
( 400) enddo
( 401) !$acc end parallel
( 402)
( 403) enddo
( 404)
( 405) !$acc end data
$ pgfortran -Minfo=accel -acc -O -Mvect=sse -ta=nvidia,cuda5.5 (下に続く)
himenobench_parallel.F90 -o parallel.exe
(前略)
jacobi:
362, Generating present(wrk2(:,:,:))
Generating present(wrk1(:,:,:))
Generating present(bnd(:,:,:))
Generating present(p(:,:,:))
Generating present(c(:,:,:,:))
Generating present(b(:,:,:,:))
Generating present(a(:,:,:,:))
368, Accelerator kernel generated
369, !$acc loop gang ! blockidx%x
371, !$acc loop vector(256) ! threadidx%x
..(snip)..
385, Sum reduction generated for gosa
392, Accelerator kernel generated
394, !$acc loop gang ! blockidx%x
396, !$acc loop vector(128) ! threadidx%x
parallel 構文を使用しての実行結果は以下の通りである。このプログラムの場合、kernels 構文を使用した場合よりも高い性能を得た。
$ ./parallel.exe The loop will be excuted in 800 times. This will take about one minute. Wait for a while. Loop executed for 800 times Gosa : 8.3822053E-04 MFLOPS: 48775.37 time(s): 2.248760000000000 Score based on Pentium III 600MHz : 588.7901 FORTRAN PAUSE: enteror d to continue> Accelerator Kernel Timing data himenobmtxp_f90 NVIDIA devicenum=0 time(us): 2,700 99: data region reached 1 time 139: data copyout reached 2 times device time(us): total=2,700 max=2,633 min=67 avg=1,350 ..(snip).. jacobi NVIDIA devicenum=0 time(us): 2,182,713 362: data region reached 2 times 368: compute region reached 803 times 368: kernel launched 803 times grid: [126] block: [256] device time(us): total=1,936,260 max=2,500 min=2,374 avg=2,411 elapsed time(us): total=1,943,551 max=2,510 min=2,382 avg=2,420 368: reduction kernel launched 803 times grid: [1] block: [256] device time(us): total=8,041 max=51 min=9 avg=10 elapsed time(us): total=15,633 max=60 min=18 avg=19 392: compute region reached 803 times 392: kernel launched 803 times grid: [126] block: [128] device time(us): total=238,412 max=352 min=293 avg=296 elapsed time(us): total=245,868 max=361 min=302 avg=306
GPUボードを tesla K20c ではなく、旧型の GeForce GTX 580 で実行すると性能は 60GFLOPS を超える。これは、動作クロックが 1.5GHz と言う高速なボードであることによるもので、K20c の2倍のクロックで動作する。
$ pgaccelinfo CUDA Driver Version: 5050 NVRM version: NVIDIA UNIX x86_64 Kernel Module 319.37 Device Number: 1 Device Name: GeForce GTX 580 Device Revision Number: 2.0 Global Memory Size: 1609760768 Number of Multiprocessors: 16 Number of Cores: 512 Concurrent Copy and Execution: Yes Total Constant Memory: 65536 Total Shared Memory per Block: 49152 Registers per Block: 32768 Warp Size: 32 Maximum Threads per Block: 1024 Maximum Block Dimensions: 1024, 1024, 64 Maximum Grid Dimensions: 65535 x 65535 x 65535 Maximum Memory Pitch: 2147483647B Texture Alignment: 512B Clock Rate: 1544 MHz
$ export ACC_DEVICE_NUM=1 (device 1を使う)
$ ./kernels.exe (kernels 構文)
For example:
Grid-size=
XS (64x32x32)
S (128x64x64)
M (256x128x128)
L (512x256x256)
XL (1024x512x512)
Grid-size =
initialize nvidia GPU
mimax= 257 mjmax= 129 mkmax= 129
imax= 256 jmax= 128 kmax= 128
Time measurement accuracy : .10000E-05
Start rehearsal measurement process.
Measure the performance in 3 times.
MFLOPS: 57574.95 time(s): 7.1439999999999993E-003 1.6939556E-03
Now, start the actual measurement process.
The loop will be excuted in 800 times.
This will take about one minute.
Wait for a while.
Loop executed for 800 times
Gosa : 8.3822053E-04
MFLOPS: 61068.13 time(s): 1.796094000000000
Score based on Pentium III 600MHz : 737.1817
$ ./parallel.exe (parallel 構文)
For example:
Grid-size=
XS (64x32x32)
S (128x64x64)
M (256x128x128)
L (512x256x256)
XL (1024x512x512)
Grid-size =
initialize nvidia GPU
mimax= 257 mjmax= 129 mkmax= 129
imax= 256 jmax= 128 kmax= 128
Time measurement accuracy : .10000E-05
Start rehearsal measurement process.
Measure the performance in 3 times.
MFLOPS: 54703.47 time(s): 7.5189999999999996E-003 1.6939556E-03
Now, start the actual measurement process.
The loop will be excuted in 800 times.
This will take about one minute.
Wait for a while.
Loop executed for 800 times
Gosa : 8.3822053E-04
MFLOPS: 58579.26 time(s): 1.872405000
姫野ベンチマークへの適用(C)
kernels 構文を用いる場合
姫野ベンチマークの C プログラム(Static Allocation版)を使用して、kernels ディレクティブを使用した例を以下に示す。なお、実行時のデータサイズは M サイズを使用し、その性能を例示した。なお、このプログラムの中では、一部、OpenACC の複合ディレクティブ を使用している。
$ pgaccelinfo CUDA Driver Version: 5050 NVRM version: NVIDIA UNIX x86_64 Kernel Module 319.37 Device Number: 0 Device Name: Tesla K20c Device Revision Number: 3.5 Global Memory Size: 5368512512
ソースプログラム: himenobench_kernels.c
( 214) #pragma acc data present(a,b,c,p,wrk1,wrk2,bnd)
( 215) {
( 216) for(n=0 ; n<nn ; ++n) {
( 217) gosa = 0.0;
( 218)
( 219) #pragma acc kernels loop gang 複合ディレクティブ 第9章参照
( 220) for(i=1 ; i<imax-1 ; i++) {
( 221) for(j=1 ; j<jmax-1 ; j++){
( 222) #pragma acc loop vector(256) reduction ( + : gosa )
( 223) for(k=1 ; k<kmax-1 ; k++){
( 224) s0 = a[0][i][j][k] * p[i+1][j ][k ]
( 225) + a[1][i][j][k] * p[i ][j+1][k ]
( 226) + a[2][i][j][k] * p[i ][j ][k+1]
( 227) + b[0][i][j][k] * ( p[i+1][j+1][k ] - p[i+1][j-1][k ]
( 228) - p[i-1][j+1][k ] + p[i-1][j-1][k ] )
( 229) + b[1][i][j][k] * ( p[i ][j+1][k+1] - p[i ][j-1][k+1]
( 230) - p[i ][j+1][k-1] + p[i ][j-1][k-1] )
( 231) + b[2][i][j][k] * ( p[i+1][j ][k+1] - p[i-1][j ][k+1]
( 232) - p[i+1][j ][k-1] + p[i-1][j ][k-1] )
( 233) + c[0][i][j][k] * p[i-1][j ][k ]
( 234) + c[1][i][j][k] * p[i ][j-1][k ]
( 235) + c[2][i][j][k] * p[i ][j ][k-1]
( 236) + wrk1[i][j][k];
( 237)
( 238) ss = ( s0 * a[3][i][j][k] - p[i][j][k] ) * bnd[i][j][k];
( 239)
( 240) gosa+= ss*ss; リダクション処理
( 242)
( 243) wrk2[i][j][k] = p[i][j][k] + omega * ss;
( 244) }
( 245) }
( 246) }
( 247)
( 248) #pragma acc kernels loop gang 複合ディレクティブ 第9章参照
( 249) for(i=1 ; i<imax-1 ; ++i) {
( 250) for(j=1 ; j<jmax-1 ; ++j) {
( 251) #pragma acc loop vector(256)
( 252) for(k=1 ; k<kmax-1 ; ++k) {
( 253) p[i][j][k] = wrk2[i][j][k];
( 254) }
( 255) }
( 256) }
( 257)
( 258) } /* end n loop */
( 259)
( 260) } /* End openACC data region */
( 261)
( 262) return(gosa);
( 263) }
$ pgcc -Minfo=accel -DMIDDLE -acc -O -Mvect=sse -ta=nvidia,cuda5.5 (下に続く)
himenobench_kernels.c -o kernels.exe
(前略)
jacobi:
214, Generating present(bnd[0:][0:][0:])
Generating present(wrk2[0:][0:][0:])
Generating present(wrk1[0:][0:][0:])
Generating present(p[0:][0:][0:])
Generating present(c[0:][0:][0:][0:])
Generating present(b[0:][0:][0:][0:])
Generating present(a[0:][0:][0:][0:])
220, Loop is parallelizable
221, Loop is parallelizable
223, Loop is parallelizable
Accelerator kernel generated
220, #pragma acc loop gang /* blockIdx.y */
223, #pragma acc loop gang, vector(256) /* blockIdx.x threadIdx.x */
..(nip)..
249, Loop is parallelizable
250, Loop is parallelizable
252, Loop is parallelizable
Accelerator kernel generated
249, #pragma acc loop gang /* blockIdx.y */
252, #pragma acc loop gang, vector(256) /* blockIdx.x threadIdx.x */
実行結果は以下の通りである。
$ ./kernels.exe
mimax = 129 mjmax = 129 mkmax = 257
imax = 128 jmax = 128 kmax =256
(snip)
Now, start the actual measurement process.
The loop will be excuted in 800 times
This will take about one minute.
Wait for a while
Loop executed for 800 times
Gosa : 8.382231e-04
MFLOPS measured : 43268.080769 cpu : 2.534989
Score based on Pentium III 600MHz : 527.659522
Accelerator Kernel Timing data
main NVIDIA devicenum=0
time(us): 2,696
111: data region reached 1 time
151: data copyout reached 2 times
device time(us): total=2,696 max=2,627 min=69 avg=1,348
..(snip)..
jacobi NVIDIA devicenum=0
time(us): 2,498,935
214: data region reached 2 times
219: compute region reached 803 times
223: kernel launched 803 times
grid: [1x126] block: [256]
device time(us): total=2,267,786 max=2,928 min=2,645 avg=2,824
elapsed time(us): total=2,275,051 max=3,004 min=2,653 avg=2,833
223: reduction kernel launched 803 times
grid: [1] block: [256]
device time(us): total=7,756 max=36 min=9 avg=9
elapsed time(us): total=15,398 max=45 min=18 avg=19
248: compute region reached 803 times
252: kernel launched 803 times
grid: [1x126] block: [256]
device time(us): total=223,393 max=325 min=267 avg=278
elapsed time(us): total=230,987 max=469 min=277 avg=287
parallel 構文を用いる場合
kernels 構文ではなく、parallel 構文を使用した場合のディレクティブの使用例を以下に示す。parallel 構文は、対象となるループは、コンパイラがデータ依存性解析は行わないため、データ独立でなければならない。
ソースプログラム: himenobench_parallel.c
( 214) #pragma acc data present(a,b,c,p,wrk1,wrk2,bnd)
( 215) {
( 216) for(n=0 ; n<nn ; ++n) {
( 217) gosa = 0.0;
( 218)
( 219) #pragma acc parallel vector_length(256)
( 220) #pragma acc loop gang reduction ( + : gosa )
( 221) for(i=1 ; i<imax-1 ; i++) {
( 222) for(j=1 ; j<jmax-1 ; j++){
( 223) for(k=1 ; k<kmax-1 ; k++){
( 224) s0 = a[0][i][j][k] * p[i+1][j ][k ]
( 225) + a[1][i][j][k] * p[i ][j+1][k ]
( 226) + a[2][i][j][k] * p[i ][j ][k+1]
( 227) + b[0][i][j][k] * ( p[i+1][j+1][k ] - p[i+1][j-1][k ]
( 228) - p[i-1][j+1][k ] + p[i-1][j-1][k ] )
( 229) + b[1][i][j][k] * ( p[i ][j+1][k+1] - p[i ][j-1][k+1]
( 230) - p[i ][j+1][k-1] + p[i ][j-1][k-1] )
( 231) + b[2][i][j][k] * ( p[i+1][j ][k+1] - p[i-1][j ][k+1]
( 232) - p[i+1][j ][k-1] + p[i-1][j ][k-1] )
( 233) + c[0][i][j][k] * p[i-1][j ][k ]
( 234) + c[1][i][j][k] * p[i ][j-1][k ]
( 235) + c[2][i][j][k] * p[i ][j ][k-1]
( 236) + wrk1[i][j][k];
( 237)
( 238) ss = ( s0 * a[3][i][j][k] - p[i][j][k] ) * bnd[i][j][k];
( 239)
( 240) gosa+= ss*ss; リダクション処理
( 241) /* gosa= (gosa > ss*ss) ? a : b; */
( 242)
( 243) wrk2[i][j][k] = p[i][j][k] + omega * ss;
( 244) }
( 245) }
( 246) }
( 247)
( 248) #pragma acc parallel vector_length(256)
( 249) #pragma acc loop collapse(3)
( 250) for(i=1 ; i<imax-1 ; ++i) {
( 251) for(j=1 ; j<jmax-1 ; ++j) {
( 252) for(k=1 ; k<kmax-1 ; ++k) {
( 253) p[i][j][k] = wrk2[i][j][k];
( 254) }
( 255) }
( 256) }
( 257)
( 258) } /* end n loop */
( 259)
( 260) } /* End openACC data region */
( 261)
( 262) return(gosa);
( 263) }
$ pgcc -Minfo=accel -DMIDDLE -acc -O -ta=nvidia,cuda5.5 (下に続く)
himenobench_parallel.c -o parallel.exe
(前略)
jacobi:
214, Generating present(bnd[0:][0:][0:])
Generating present(wrk2[0:][0:][0:])
Generating present(wrk1[0:][0:][0:])
Generating present(p[0:][0:][0:])
Generating present(c[0:][0:][0:][0:])
Generating present(b[0:][0:][0:][0:])
Generating present(a[0:][0:][0:][0:])
219, Accelerator kernel generated
221, #pragma acc loop gang /* blockIdx.x */
223, #pragma acc loop vector(256) /* threadIdx.x */
..(snip)..
222, Loop is parallelizable
223, Loop is parallelizable
240, Sum reduction generated for gosa
248, Accelerator kernel generated
250, #pragma acc loop gang /* blockIdx.x */
252, #pragma acc loop vector(256) /* threadIdx.x */
parallel 構文を使用しての実行結果は以下の通りである。
$ ./parallel.exe
Now, start the actual measurement process.
The loop will be excuted in 800 times
This will take about one minute.
Wait for a while
Loop executed for 800 times
Gosa : 8.382231e-04
MFLOPS measured : 42584.243721 cpu : 2.575697
Score based on Pentium III 600MHz : 519.320045
Accelerator Kernel Timing data
main NVIDIA devicenum=0
time(us): 2,696
111: data region reached 1 time
151: data copyout reached 2 times
device time(us): total=2,696 max=2,627 min=69 avg=1,348
(snip)
jacobi NVIDIA devicenum=0
time(us): 2,539,966
214: data region reached 2 times
219: compute region reached 803 times
219: kernel launched 803 times
grid: [126] block: [256]
device time(us): total=2,264,447 max=2,943 min=2,635 avg=2,819
elapsed time(us): total=2,271,631 max=2,953 min=2,644 avg=2,828
219: reduction kernel launched 803 times
grid: [1] block: [256]
device time(us): total=7,902 max=36 min=9 avg=9
elapsed time(us): total=15,579 max=88 min=18 avg=19
248: compute region reached 803 times
248: kernel launched 803 times
grid: [126] block: [256]
device time(us): total=267,617 max=389 min=328 avg=333
elapsed time(us): total=275,092 max=412 min=337 avg=342
[Reference]