OpenACC ディレクティブによるプログラミング
7章 Data 構文とその他のデータに係わる構文
データの属性
まず最初に、OpenACC における変数のデータ属性について説明する。変数に対するデータの属性は、
predetermined(既定)、implicitly determined (暗黙に決定されるもの)、explicitly determined (明示的に指定されているもの)と言う 3 種類に分類される。
predetermined のデータ属性を持つ変数とは、OpenACC の loop ディレクティブを有した C 言語の for ループ、あるいは Fortran 言語であれば do ループのループ(インデックス)変数を言う。一般にループ変数は、ループの各イテレーションを実行する各スレッドにおいてプライベートな変数となる。従って、parallel or kernels の並列領域内の Fortran do 文におけるループ変数は、ループを実行するスレッドにおいては「プライベート」な変数として予めセットされる。C の場合も同様で、こうしたループ変数は「プライベート」な変数として予めセットされる。OpenACC 2.0 以降においての概念であるが、Accelerator Compute 構文内から call されるプロシジャー(サブルーチン)内で宣言されている変数は、そのプロシジャー・コールを実行するスレッドにおいて「プライベート」な変数として予めセットされる。これについても、predetermined な属性の変数として分類される。
implicitly determined (暗黙に決定されるもの)な属性を有する変数とは、コンパイラが parallel or kernels の並列領域内で使用する変数を調べ、アクセラレータ上で使用する変数として暗黙に定義されたものを言う。なお、このデータ属性であっても、この変数が data 構文、declare 構文、あるいは、Accelerator Compute 構文の data clause(節)で明示的に指定された場合、明示的に設定された変数の設定が優先される。
explicitly determined (明示的に指定されているもの)な属性を有する変数とは、 data 構文、declare 構文、あるいは、Accelerator Compute 構文の data clause(節)で明示的に指定されているものを言う。
データ領域 (data region) とデータのライフタイム
OpenACC における「データ領域 (data region)」には、以下の4つのタイプが存在する。その中にデータの「ライフタイム」(存続時間)という概念がある。
- プログラムが data 構文に到達した時、データ領域が生成される。data 構文で指定されたアクセラレータ上に生成されるデータは、その data 構文の領域における「ライフタイム」を持つ。そのライフタイムは、プログラムがデータ領域を終了させるまで生き続ける。
- プログラムが、明示的な data clause を有した Accelerate compute 構文に到達した時、あるいはコンパイラがアクセラレータ上に implicitly determined 変数をアロケーションする Accelerate compute 構文に到達した時、その compute 構文内の「ライフタイム」を有するデータ領域が生成される。アクセラレータ上に生成されたデータは、kernels あるいは parallel 構文の領域内でライフタイムを有する。
- (OpenACC 2.0) プログラムがプロシジャーに実行を移す時に、プロシジャーの「ライフタイム」を有する暗黙のデータ領域が生成される。すなわち、プロシジャーがコールされた時点で暗黙のデータ領域が生成され、プロシジャーの実行が終了した時点でそのデータ領域は終了する。暗黙なデータ領域としてアクセラレータ上に生成されたデータは、プロシジャーの呼び出しを行われている時だけライフタイムを有する。
- (OpenACC 2.0) さらにもう一つ、プログラムそれ自身の実行に関連した暗黙のデータ領域がある。プログラムの暗黙のデータ領域は、そのプログラム実行におけるライフタイムを有する。アクセラレータ上で生成された静的データあるいはグローバルデータは、そのプログラム実行におけるライフタイムを有する。あるいは、プログラムがアクセラレータにアタッチされ初期化されてから、そのアクセラレータがデタッチ、シャットダウンされるまでの間、そのライフタイムが継続する。
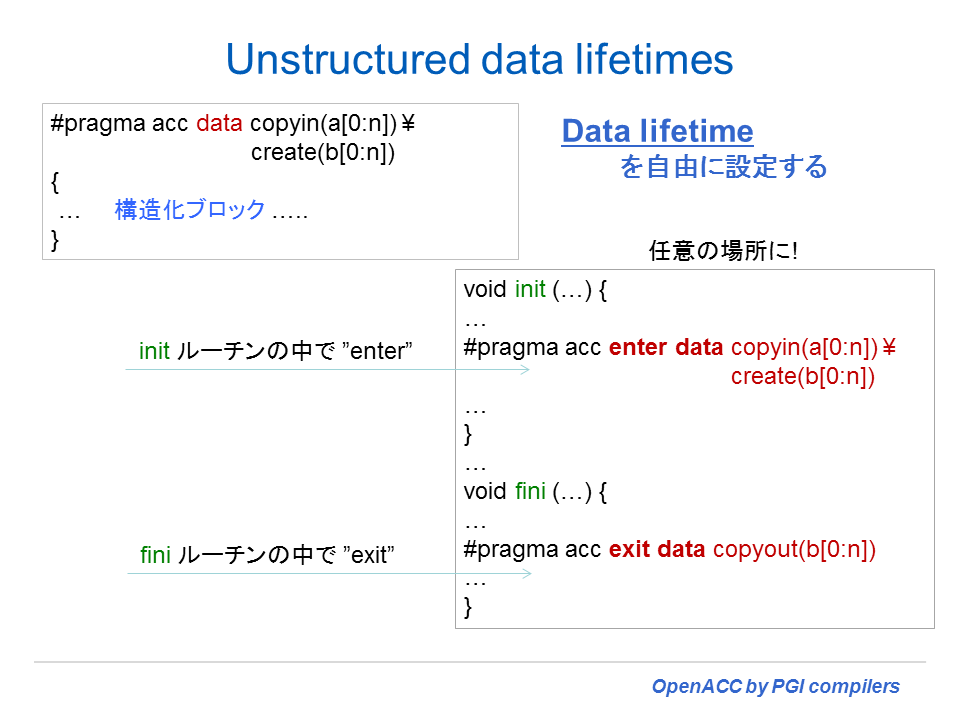
OpenACC 2.0 から、上記の「データ領域」の概念に加えて、プログラムは任意の場所で、enter data と exit data ディレクティブを使用してアクセラレータ上のデータを生成したり、削除することが出来るようになった。この機能は同等なランタイム API 関数を使用しても同様に機能する。プログラムが enter data ディレクティブあるいは、acc_copyin、acc_create 等のランタイム API ルーチンを実行した時点で、指定された各変数、配列、サブ配列のデータのアクセラレータ上のライフタイムが開始される。そして、exit data ディレクティブあるいは、acc_copyout、acc_delete 等の API ルーチンが実行されるまで各当該データのライフタイムは継続され、この時点で終了する。もし、exit data ディレクティブあるいは、適切なランタイム API が記述されないプログラムの場合は、プログラムが終了するまでそのライフタイムは継続する。
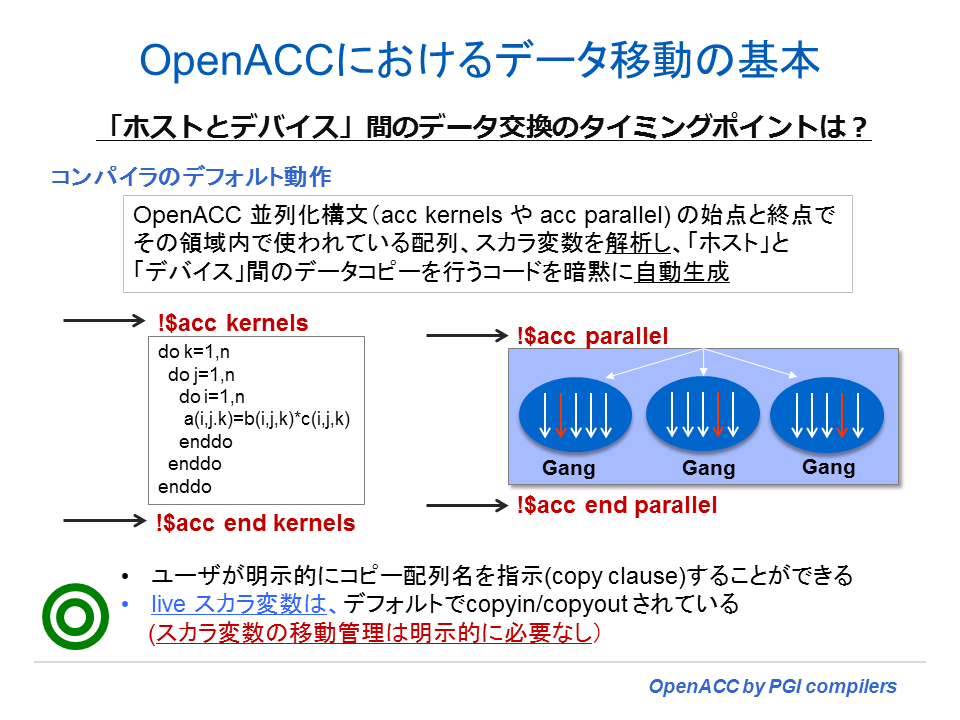
データ移動のタイミング
上記の項の 1 と 2 で示したコンパイラが行うデータ領域の生成とそれに伴うデータ転送のためのコード生成に関して、少なくとも以下の二つの点に関しては理解しておく必要がある。
- プログラムが data 構文に到達すると、当該構文の data clause を使って明示的(explicitly determined) に指定された変数、配列に関して、アクセラレータへコピーするためのデータ転送用のコードを生成する。また、その data 構文の構造化ブロックが終了した時点で、アクセラレータからホストがへデータを戻す必要のある変数、配列のためのデータ転送のためのコードを生成する。
- コンパイラは kernels 構文や parallel 構文による並列領域内で使用している変数、配列の解析を行う。コンパイラは当該並列領域が始まる時点で、アクセラレータへコピーが必要な変数、配列のデータ転送のためのコードを生成する。また、並列領域の終了時点でアクセラレータからホストがへデータを戻す必要のある変数、配列のためのデータ転送のためのコードを生成する。これらの操作は、ユーザが data clause を使って明示的に指定していない限り、暗黙 (implicitly determined) かつ自動的に行われる。
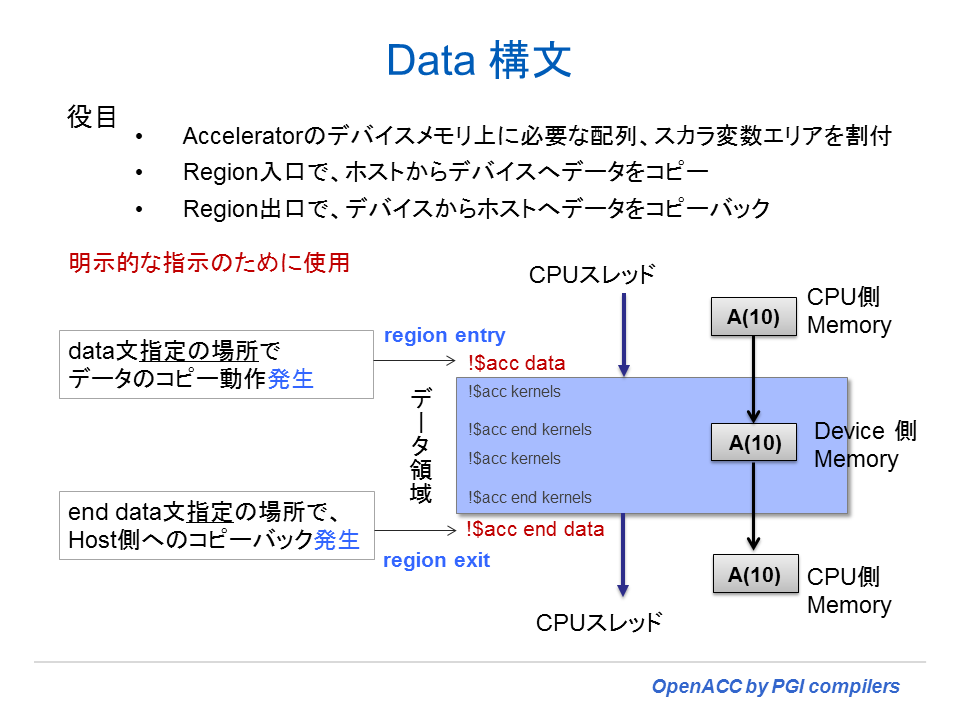
Data ディレクティブのシンタックスとその clauses(節)
data 構文は、その領域においてデバイスメモリ中にアロケートされるスカラ、配列、サブ配列を定義するためのものである。また、データがデータ領域のエントリにおいてホストからデバイスメモリにコピーされるものなのか、あるいは、領域の終了時点でデバイスメモリからホストへコピーされるものなのかを含めて定義するために使用される。なお、OpenACC 2.0 以降では、従来の「CPU メモリ」あるいは「ホストメモリ」と言った言い方を「ローカルメモリ」という表現方法に変えた。「ローカルメモリ」とは、「ローカルなスレッド」がアクセスするメモリを言い、必ずしもホスト上のメモリとは限らない(デバイス上でもそのような状況が発生する)。また、「デバイスメモリ」とは論理的にも物理的にもホストメモリから分離されたアクセラレータ上のメモリのことを意味する。OpenACC 2.0 以降、「ローカルスレッド」と言う言葉が新たに定義された。ロカールスレッドとは、OpenACC ディレクトリあるいは構文を実行するアクセラレータ上のスレッドもしくは、ホスト上のスレッドのことを意味する。この言い方に変えた理由は、OpenACC 2.0 以降に、ネストされた並列領域のサポートがなされたことにより、アクセラレータスレッドからさらにその配下のカーネル並列領域が呼ばれることが出来るようになったため、ホスト側のメモリだけの概念ではなくなったことによるものである。
【Syntax】 C and C++ の場合 #pragma acc data [clause-list] new-line { 構造化ブロック(ループ)} Fortranの場合 !$acc data [clause-list] 構造化ブロック(ループ) !$acc end data Clause(節)は、次のものが指定できる if( condition ) copy( var-list ) copyin( var-list ) copyout( var-list ) create( var-list ) present( var-list ) present_or_copy( var-list ) present_or_copyin( var-list ) present_or_copyout( var-list ) present_or_create( var-list ) deviceptr( var-list )
if clause
if clause は、必須ではなくオプションである。if の指定がない場合、コンパイラは必要とされるデータのためにデバイスメモリ上にアロケートし、ローカルメモリとの間でデータ移動を行うためのコードを生成する。if が現れるとコンパイラは、その条件に従い、アロケートとデータ移動のコードを生成するかどうかを決める。C/C++ の場合は、その条件判定においてノンゼロである場合、Fortran では .true. である場合、上記の動作を行う。C/C++ の場合のゼロ、あるいは Fortran の場合 .false. の条件判定の場合は、アロケートもデータ移動も行わない。
data clause(コピーの方法を指示する clauses)
copy、cpoyin 等のデータのコピー、アロケートに関する属性は以下の data clause の項で説明する。
Enter Data と Exit Data ディレクティブ (OpenACC 2.0)
enter data ディレクティブは、プログラムが実行している間、あるいは、データのデアロケートを指示する exit data ディレクティブに到達するまでの間、デバイスメモリ中にアロケートされるスカラ、配列、サブ配列を定義するために使用される。また、データが enter data ディレクティブの時点でホスト(ローカル)からデバイスメモリにコピーされるべきものなのか、あるいは exit data ディレクティブの時点でデバイスメモリからホスト(ローカル)へコピーされるべきものなのかを含めて指示するために使用される。このディレクティブで指定された変数のライフタイムは、enter data ディレクティブからそれに対応する exit data ディレクティブまでの間となる。なお、そのデータ・ライフタイム内に現れる OpenACC 構文上においては、その対象となる変数を present clause と同じ状態として扱われる。本機能は OpenACC 2.0 の機能であるため、PGI 13.10 以前のバージョンではこの機能は使用できない。
具体的な使用プログラム例は、13章に説明してあるのでこれを参照して欲しい。

【Syntax】 C and C++の場合の enter data ディレクティブ #pragma acc enter data [clause-list] new-line Fortranの場合 !$acc enter data [clause-list] Clause(節)は、次のものが指す async [( int-expr )] wait [( int-expr-list )] if( condition ) copyin( var-list ) create( var-list ) C and C++ の場合の exit data ディレクティブ #pragma acc exit data [clause-list] new-line Fortranの場合 !$acc exit data [clause-list] Clause(節)は、次のものが指定できる async [( int-expr )] wait [( int-expr-list )] if( condition ) finalize copyout( var-list ) delete( var-list )
if clause
if clause は、必須ではなくオプションである。if の指定がない場合、コンパイラはデバイスメモリ上にアロケートあるいはデアロケートを行うためのコードを生成する。また、ローカルメモリとの間でデータ移動を行うためのコードも生成する。if が現れるとコンパイラは、その条件に従い、アロケート/デアロケートとデータ移動のコードを生成するかどうかを決める。C/C++ の場合は、その条件判定においてノンゼロである場合、Fortran では .true. である場合、上記の動作を行う。C/C++ の場合のゼロ、あるいは Fortran の場合 .false. の条件判定の場合は、アロケート/デアロケートもデータ移動も行わない。
async clause と wait clause
async cluase は parallel 構文、kernels 構文、enter data、exit data、update あるいは wait ディレクティブと共に指定可能な clause である。これら全てのケースで、この clasue はオプションである。 async が指定されていない場合、ローカル(ホスト)スレッドは、当該構文あるいは data 処理が終了するまで、次のコードを実行することを待つ。wait ディレクティブの場合もこれと同じ動作を行う。wait ディレクティブの場合は、対応する非同期実行キューの全ての処理が完了するまで待つ。一方、async clause があるとき、ローカルスレッドは非同期に parallel 構文、kernels 構文、data 処理の次に置かれているコード部分の処理を継続する。さらに詳細は、OpenACC 仕様書を参考にすること。
data clause(コピーの方法を指示する clauses)
copyin、cpoyout 等のデータのコピー、アロケートに関する属性は以下の data clause の項で説明する。データ領域が entering する際に、もしすでに当該データがデバイス上に存在していた場合、デバイスデータは生成されることはないが、内部的にそのデータに対する「参照カウント」を一つ増加させる。その後、exit data ディレクティブに指示されたポイントで、デバイスデータの「参照カウント」を一つ減じて、もし、そのカウントがゼロであればデータもデバイスから削除される。
finalize clause
当該データの「参照カウント」をゼロにセットして、デバイスデータを削除する。
data clause(節)とは
data clause(節)は、parallel 構文、kernels 構文、data 構文、そして、enter data と exit data ディレクティブ上に指定できる。各 clause の中の引数リストは、変数名、配列名、サブ配列の指定をコンマで区切ることにより複数指定することができる。deviceptr と present を除くすべての clause は、Fortran のコモンブロック名をスラッシュで囲むことにより、これを指定することができる。また、そのコモンブロック名は declare ディレクティブ内の link clause に現れても構わない。全てのケースにおいて、コンパイラはデータのアロケートとデバイスメモリ内の変数あるいは配列のコピーの管理を行い、その変数あるいは配列の visible device copy (コンパイラがコンパイル段階でコピー挙動が明示的に分かること)の生成を行う役目を果たす。この言葉は、OpenACC仕様の記述で、「プログラムは、visible device copyの状態であることが必要」といった表現で使われることが多い。いわゆる、「暗黙のデータコピー」に対する言葉として使われる。
制限事項
- data clause は、device_type clause の後に指定してはならない
data clause における配列要素範囲の指定方法
C/C++ において「サブ配列」の指定方法は、配列名の後にブラケット[括弧]を記述しその中に配列要素の範囲を記述する。その書式(notation) は、以下のように 「開始添字番号」と「その長さ」を使用する方式を採用している。下記の例では、サブ配列 AA[2:n] の表記は、AA[2], AA[3], ..., AA[2+n-1] のことを意味する。
AA[2:n] = AA[開始添字番号:長さ]
もし、開始添字番号の記述がなければ、その値は、デフォルト 0 であるとする。また、明示的な長さの指定がなくてそれがコンパイラが知り得る場合、その配列のサイズが適用される。もし、配列の長さをコンパイラが知ることができない配列の場合は、必ずその長さの指定が必要となる。

C/C++ においては二次元配列の指定方法は少なくとも以下の4つの方法がある。
- 静的にサイズを指定する: float AA[100][200];
- 静的なサイズを有するデータ型に対するポインタ記述: typedef float row[200]; row* BB;
- 静的なサイズを有するポインタ配列: float* CC[200];
- ポインタのポインタ: float** DD;
各次元は、静的なサイズで指定する方法、あるいは動的にアロケートされたメモリへのポインタで指定する方法がある。なお、これらは長方形配列 (rectangular array) を指定するために、以下のようにサブ配列の書式(notation) を使用して data clause の中に記述することも可能である。なお、各次元の配列の長さの指定であるが、以下のような二次元配列の場合、一次元目の添字以外は、「フルの長さ」を必ず指定する必要がある。OpenACC では、配列の部分転送の場合であっても、メモリアドレス上、連続で転送が行われるように配列添字の notation 指定を行う必要がある(C 言語の場合は Row-major なメモリ配置であるため)。以下の例では二次元目の配列添字が、全て 0 から開始されていることに注意されたし。
- AA[2:n][0:200]
- BB[2:n][0:m]
- CC[2:n][0:m]
- DD[2:n][0:m]

C/C++ における multidimensional rectangular サブ配列は、静的なサイズの次元、あるいは動的にアロケートされた次元を任意に組み合わせて指定することができる。静的なサイズの次元に対しては、1次元目を除いた全ての次元においてフルサイズの要素を指定しなければならない。これは、データのメモリ上の並びが連続であることを保証するためである。一方、動的にアロケートされた次元に対しては、コンパイラはホスト上のポインタに対応するデバイス上のポインタを割り付けるようにする。また、コンパイラは必要に応じて、これらのポインタを埋めるようにする。
Fortran におけるサブ配列の指定方法は、一般的な Fortran 規約に則った notation で指定する。各次元をカンマで区切り、各次元の要素の範囲は、以下のようにコロン(:)で区切り要素の下限と上限値を指定する。もし、下限値、あるいは上限値が省略されている場合は、配列の宣言文やアロケート時の境界値を元にこれらの数値がデフォルトで使われる。Fortran では、メモリ上カラムメジャー(Colomn-major)な配置となるため、最後の次元を除き他の全ての次元では、その要素範囲を「フルの長さ」で指定しなければならない。これは、メモリアドレス上、連続で転送が行われるようにするためである。
arr(1:high,low:100)
制限事項
- Fortran において、大きさ引継ぎ配列(assumed-size array)が仮引数として使用されている場合、最後の次元の要素上限値は必ず指定する必要がある
- C/C++ において、動的にアロケートされる配列は、その次元の長さは明示的に指定されなければならない
- C/C++ において、データのライフタイムの間に、ホスト上あるいはデバイス上を問わず、ポインタ配列内のポインタが修正されると、結果的に未定義の(予期せぬ)挙動を示すことになる
- サブ配列が data clause 内に指定された場合、コンパイラの実装によっては、そのサブ配列のサイズのみをアクセラレータ上にアロケートする場合がある
- Fortranにおいて、配列ポインタが指定されたとしても、そのポインタ結合(pointer association)はデバイスメモリ上に保持されない。(Deep copy ができない)
- data clause 内の任意の配列あるいはサブ配列(Fortranの配列ポインタを含む)は、メモリ上の連続したブロックとして指定しなければならない。但し、動的にアロケートされる複数次元の C 配列はその例外となる。(筆者補足:動的にアロケートされた多次元配列の場合、アロケートの方法如何で配列要素の並びが連続しない場合があるため、コンパイラ側でデータの連続する部分の転送を複数繰り返すコードを生成する)
- C/C++において、構造体やクラス型の変数あるいは配列の場合は、必要に応じて、構造体あるいはクラスの全てのデータ・メンバー(要素)がアロケートされコピーされる。もし、構造体あるいはクラスメンバーがポインタ型の場合、そのポインタの指すデータは暗黙にはコピーされない(Deep copy ができない)
- Fortran において、派生型の変数あるいは配列の場合、必要に応じて、その派生型の全てのメンバー(要素)がアロケートされコピーされる。また、任意のメンバーが allocatable あるいは pointer の属性を持つ場合、そのメンバーを通してアクセスされるデータは、コピーされない
- data 構文上の clause 内の配列のサブスクリプトあるいはサブ配列表現が演算式で記述されている場合、たとえ、データ領域内で当該演算式に用いている変数が変更された場合でも、当初の演算式の値がデータ領域の終端におけるデータ・コピーにおいても使用される
各 data clause の説明
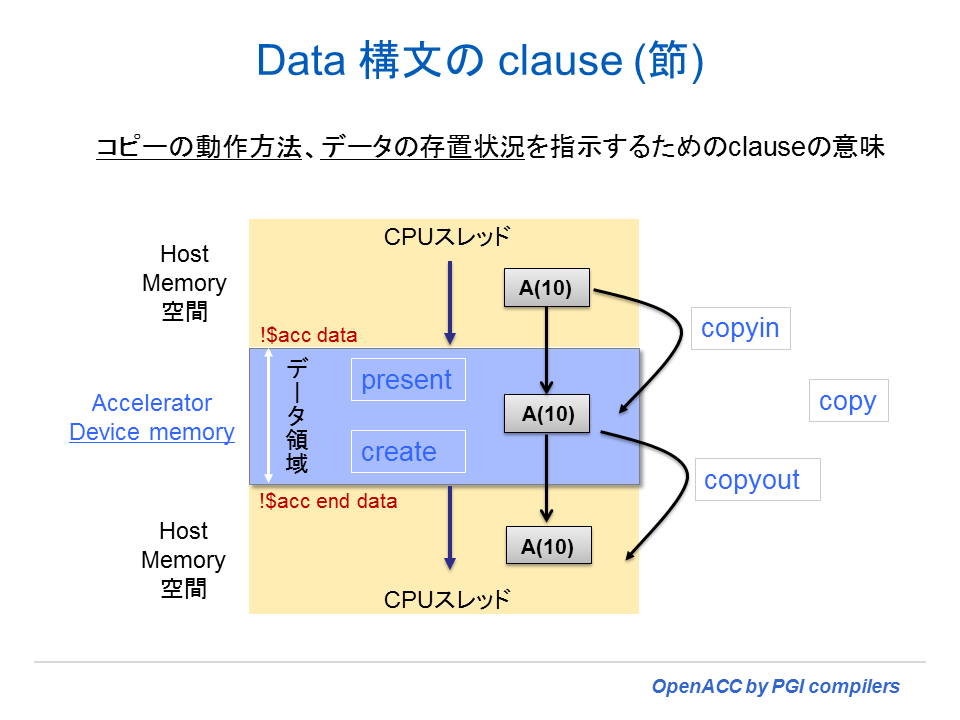
copy( var-list )
copy clause は、var-list に記された変数、配列、サブ配列、あるいはコモンブロックを宣言するために使用される。この var-list は、デバイスメモリへコピーされる必要のあるローカルメモリ内の変数等を示すリストであり、さらに、アクセラレータ上で変更された当該内容をローカルメモリへコピーバックする必要のあるものとして定義される。もし、サブ配列が指定された場合、その配列のそのサブ配列のみがコピーされる。data 構文や compute 構文上では、その領域の入り口でそのデータはデバイスメモリ上にアロケートされ、かつコピーが実施される。また、当該領域の出口で、当該データはローカルメモリへコピーバックされ、かつ、デバイスメモリ上でデアロケートが行われる。もし、デバイスがローカルスレッドと共有するメモリを有するものである場合、copy clause 内のデータは共有され、メモリ上でのアロケートもコピーも行われない。
copyin( var-list )
copyin clause は、var-list に記された変数、配列、サブ配列、あるいはコモンブロックを宣言するために使用される。この var-list は、デバイスメモリへコピーされる必要のあるローカルメモリ内の変数等を示すリストである。もし、サブ配列が指定された場合、その配列のそのサブ配列のみがコピーされる。copyin clause 内に変数、配列、サブ配列が指定されている場合、たとえ、アクセラレータ上で当該変数等の値が変更されているとしても、この clause は、デバイスメモリからローカルメモリへのコピーバックは行う必要のないものとして扱う。data 構文や compute 構文上では、その領域の入り口でそのデータはデバイスメモリ上にアロケートされ、かつコピーが実施される。また、当該領域の出口で当該データのデアロケートが行われる。enter data clause 上では、当該データはデバイスメモリ上にアロケートされ、コピーされる。もし、デバイスがローカルスレッドと共有するメモリを有するものである場合、copyin clause 内のデータは共有され、メモリ上でのアロケートもコピーも行われない。
copyout( var-list )
copyout clause は、var-list に記された変数、配列、サブ配列、あるいはコモンブロックを宣言するために使用される。この var-list は、アクセラレータ領域の終点でデバイスメモリ内にある変数や値が変更された変数をローカルメモリへコピーされる必要のある変数等を示すリストである。もし、サブ配列が指定された場合、その配列のそのサブ配列のみがコピーされる。copyout clause 内に変数、配列、サブ配列が指定されている場合、たとえ、アクセラレータ上で当該変数等の値が使用されているとしても、この clause は、ローカルメモリからデバイスメモリへのコピーは行う必要のないものとして扱う。data 構文や compute 構文上では、その領域の入り口でそのデータのアロケートが実施される。また、当該領域の出口で当該データのロカールメモリへのコピーとデアロケートが行われる。exit data clause 上では、当該データはローカルメモリ上にコピーバックされ、デアロケートが実施される。もし、デバイスがローカルスレッドと共有するメモリを有するものである場合、copyout clause 内のデータは共有され、メモリ上でのアロケートもコピーも行われない。
create( var-list )
create clause は、var-list に記された変数、配列、サブ配列、あるいはコモンブロックを宣言するために使用される。この var-list はデバイスメモリ上にアロケート(生成)される必要のある変数等を示すリストである。これらの変数等は、ローカルメモリ上の当該変数値はアクセラレータ上では必要とされず、また、アクセラレータ上で当該変数の値が変更されたとしても、ロカールメモリへコピーバックする必要のないものである。data 構文や compute 構文上では、その領域の入り口でデバイスメモリ上で当該データのアロケートが実施される。また、当該領域の出口で当該データのデアロケートが行われる。enter data clause 上では、当該データはデバイスメモリ上にアロケートされる。この clause 内のデータは、ローカルメモリとデバイスメモリ間でのコピーは行われない。もし、デバイスがローカルスレッドと共有するメモリを有するものである場合、create clause 内のデータは共有され、メモリ上でのアロケートもコピーも行われない。
delete( var-list )
delete clause は、exit data clause 上で使用される。この var-list で指定された配列、サブ配列、コモンブロックは、ローカルメモリへのコピーバックが行われずに、アクセラレータデバイス上の当該データがデアロケートされる。もし、デバイスがローカルスレッドと共有するメモリを有するものである場合は、この clause は何のアクションも実施されない。
present( var-list )
present clause は、ロカールメモリとデバイスメモリが共有されていない場合のハードウェア環境において、var-list に記された変数あるいは配列が、すでにデバイスメモリ上に存在していることを(コンパイラ)実装に対し知らせるために使用する。こうした状態は、「data 構文によるデータ領域」あるいは「データライフタイム」の中で起こり得る。例えば、単純には data 構文内、あるいはデータライフタイム内で、Accelerator Compute 構文が存在している場合である。あるいは、data 構文、enter data ディレクティブあるいは、その機能と同等なランタイム API などを含んでいる「プロシジャー(手続き)」を call しているその上位のプロシジャーの中で、data 構文がある場合などが考えられる。(コンパイラ)実装は、その存在するアクセラレータ・データを調べて使用する方法をとる(ローカルメモリとデバイスメモリ間のデータコピーは行わない)。もし、このようなデータライフの中でアクセラレータ上にこうした変数や配列が存在していない場合、その振る舞いは未定義となるため、プログラムはランタイムにおいてエラーを起こす場合がある。
もし、「データライフタイム」内で、データがサブ配列として指定されている場合、present clause は同じサブ配列あるいは、データライフタイム内のサブ配列の適切なサブセットである当該サブ配列を指定しなければならない。もし、present clause 内にあるサブ配列がデータライフタイム内に指定されたサブ配列の部分ではない配列要素を含むものであった場合、ランタイムエラーとなる。
present_or_copy( var-list )
present_or_copy clause は、ロカールメモリとデバイスメモリが共有されていない場合のハードウェア環境において、var-list に記された変数あるいは配列の各々が、すでにデバイスメモリ上に存在しているかどうかを確認(テスト)するように(コンパイラ)実装に対し指示するために使用する。もし、データがすでに存在している場合、プログラムは、上記の present clause の動作と同じように振る舞う。従って、この場合はデータのデバイス上へのアロケートやローカルメモリとデバイスメモリ間のデータコピーは行われない。もしテストの結果、データが存在していない場合は プログラムは copy clause と全く同じ振る舞い方をする。
この clause の省略記述は、pcopy である。サブ配列に関する制約事項は、present clause で説明した内容と同じである。
present_or_copyin( var-list )
present_or_copyin clause は、ロカールメモリとデバイスメモリが共有されていない場合のハードウェア環境において、var-list に記された変数あるいは配列の各々が、すでにデバイスメモリ上に存在しているかどうかを確認(テスト)するように(コンパイラ)実装に対し指示するために使用する。もし、データがすでに存在している場合、プログラムは、上記の present clause の動作と同じように振る舞う。従って、この場合はデータのデバイス上へのアロケートやローカルメモリとデバイスメモリ間のデータコピーは行われない。もしテストの結果、データが存在していない場合は プログラムは copyin clause と全く同じ振る舞い方をする。
この clause の省略記述は、pcopyin である。サブ配列に関する制約事項は、present clause で説明した内容と同じである。
present_or_copyout( var-list )
present_or_copyout clause は、ロカールメモリとデバイスメモリが共有されていない場合のハードウェア環境において、var-list に記された変数あるいは配列の各々が、すでにデバイスメモリ上に存在しているかどうかを確認(テスト)するように(コンパイラ)実装に対し指示するために使用する。もし、データがすでに存在している場合、プログラムは、上記の present clause の動作と同じように振る舞う。従って、この場合はデータのデバイス上へのアロケートやローカルメモリとデバイスメモリ間のデータコピーは行われない。もしテストの結果、データが存在していない場合は プログラムは copyout clause と全く同じ振る舞い方をする。
この clause の省略記述は、pcopyout である。サブ配列に関する制約事項は、present clause で説明した内容と同じである。
present_or_create( var-list )
present_or_create clause は、ロカールメモリとデバイスメモリが共有されていない場合のハードウェア環境において、var-list に記された変数あるいは配列の各々が、すでにデバイスメモリ上に存在しているかどうかを確認(テスト)するように(コンパイラ)実装に対し指示するために使用する。もし、データがすでに存在している場合、プログラムは、上記の present clause の動作と同じように振る舞う。従って、この場合はデータのデバイス上へのアロケートやローカルメモリとデバイスメモリ間のデータコピーは行われない。もしテストの結果、データが存在していない場合は プログラムは create clause と全く同じ振る舞い方をする。
この clause の省略記述は、pcreate である。サブ配列に関する制約事項は、present clause で説明した内容と同じである。
deviceptr( var-list )
deviceptr clause は、var-list 内にあるポインタは、デバイスポインタであることを宣言するために使用する。すなわち、そのデータはデバイスメモリ上にアロケートする必要がなく、このポインタに対するホストとデバイス間のデータ転送も必要ないことを知らせるものである。これは、CUDA C/C++、Fortran とのインターオペラビリティによるプログラミングにおいて利用される。C/C++ においては、va-list 内の変数はポインタ変数でなければならない。Fortran においては、var-list 内の変数は仮引数(配列、スカラ変数)でなければならない。また、これは、Fortran の pointer、allocatable あるいは、value 属性を持ってはならない。デバイスがローカルスレッドと共有するメモリを有するものである場合、ホストポインタはデバイスポインタと同じものとなるため、この clause は無視される。
その他のデータに係わる構文
その他のデータ管理に係わる構文について以下に纏める。
Host_Data 構文
host_data 構文は、ホスト上でデバイスデータのアドレスを有効にさせるための構文である。この構文の活用方法については、後章の「相互運用性」の章で説明する。
【Syntax】 C and C++の場合の host_data ディレクティブ #pragma acc host_data clause-list new-line { 構造化ブロック(ループ)} Fortranの場合 !$acc host_data clause-list 構造化ブロック(ループ) !$acc end host_data Clause(節)には、次のものが指定できる use_device( var-list )
use_device( var-list )
use_device clause は、host_data 構文内にあるコード内で var-list にある変数あるいは配列のデバイスアドレスを使用するようにコンパイラに指示するためものである。特に、これは低レベル API(CUDA Cあるいは CUDA Fortran) 等で記述された最適化された手続き(プログラム)に対して当該変数や配列のデバイスアドレスを渡すために使用される。var-list 内の変数あるいは配列は、この構文を含むデータ領域あるいはデータライフタイム内においてアクセラレータのメモリ内に存在していなければならない。もし、デバイスがローカルスレッドと共有するメモリを有するものである場合、デバイスアドレスは、ホストアドレスと同じものとなる。
data 構文の使用例
実際のプログラム上での data 構文を活用方法の概略については、第4章の「OpenACC data ディレクティブの役目」で述べた。ここではサブルーチンあるいはプロシジャーの呼び出しを含む場合の data 構文の使用法の概略を説明する。まず、以下の Fortran プログラムの例は、メインプログラムにおいて時間進展の loop ループがあり、そのループ内で、各計算モジュールがサブルーチンとして call されている形をとっている。各サブルーチン内では、アクセラレータ側で処理するために、Accelerator compute 構文(kernels あるいは parallel)が適用されているものとする。サブルーチンへ引数として渡されている x、y、z は、全てのサブルーチンで使用されるものとして、時間進展の loop ループの開始前に予め、data 構文を用いてデバイス側に各変数の領域をアロケートし、コピーを行うようにコンパイラに指示を出す。これによって、時間進展の loop ループの前に1回のみ、当該変数・配列等のデータがコピーされる。loop ループ内では各サブルーチンに処理が移っても、すでにデバイス側にアロケートされている変数・配列等のデータを使ってデバイス側の処理を行う。一方、時間進展の loop ループが終了した後、ホスト側に計算された結果データ等を戻す必要があるが、これは、!$acc end data 構文の時点で1回行われる。こうして、ホスト~デバイス間の無駄なデータ交換を行わないようにする。
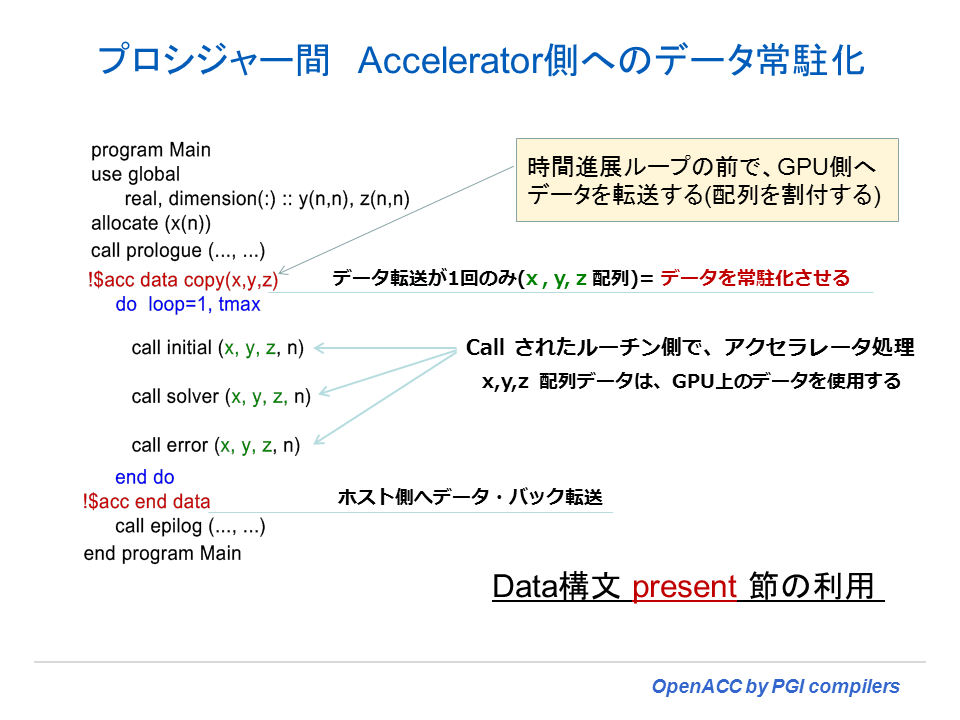
C/C++ プログラムの場合も同じような考え方で data 構文を使う。以下の C プログラムは、全て静的にサイズが指定された配列を使用している例である。main プログラム内で、各計算モジュールのプロシジャーを call している形態である。各プロシジャー内では、アクセラレータ側で処理するために、kernel 構文が適用されており、各々で共通に使用される変数・配列を使用する。main プログラムのプロシジャーの実行の流れの中に OpenACC data 構文による「データ領域」ブロックを作成する。以下の例では、setbv()~ssor() までのプロシジャーの実行の中で共通な data 領域を生成する。これによって、個々のプロシジャー内で行われるホスト~デバイス間のデータ交換を避けることができる。data 構文はこうした用途で使用される。

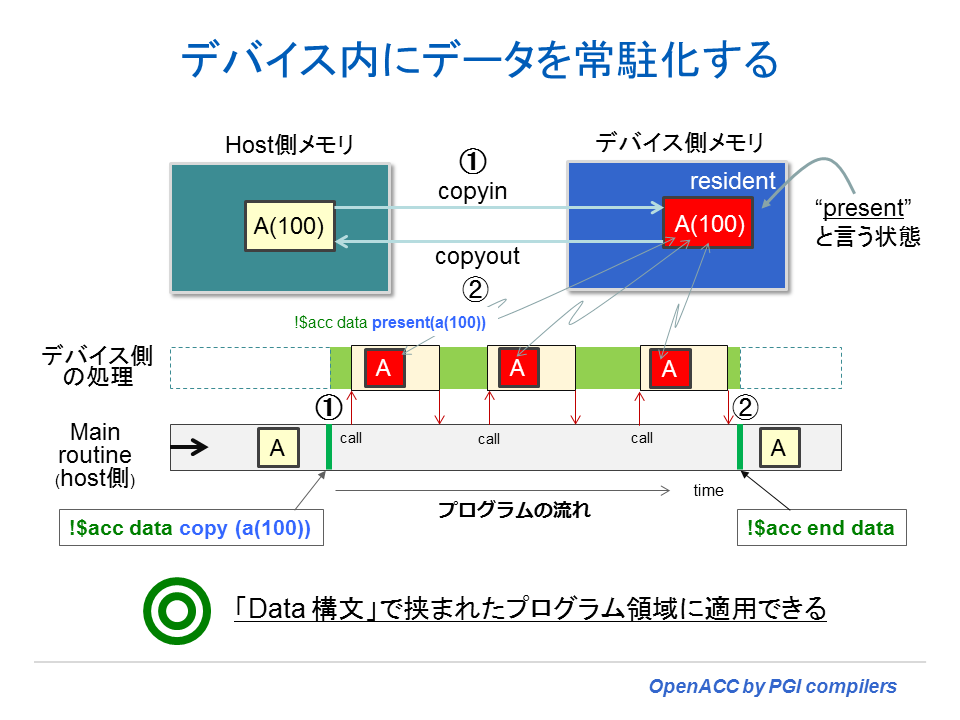
data 構文を使ってデバイス側にデータをアロケートしている状態を模式的に示すと以下のような形となる。以下の図の例では、A(100) と言う配列がデータ構文の始点にてデバイス側のメモリ上にアロケートされ、コピーされる。これは、このまま data 構文の終点の時点まで、デバイス側のメモリ上で常駐化する。その間、異なるサブルーチンやプロシジャーにおいてもデバイス上の A 配列を参照し値の変更もできる。A 配列のこの状態をデバイス上での「present」の状態という。
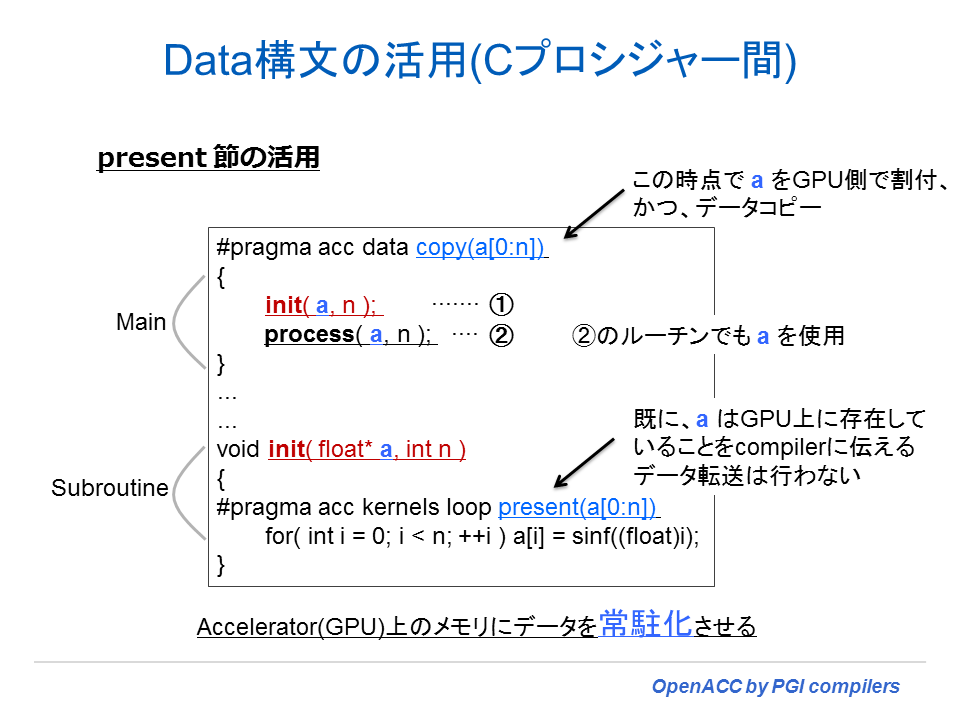
以下の例は、C プログラムにおける present cluase の使う例を簡単に示した。
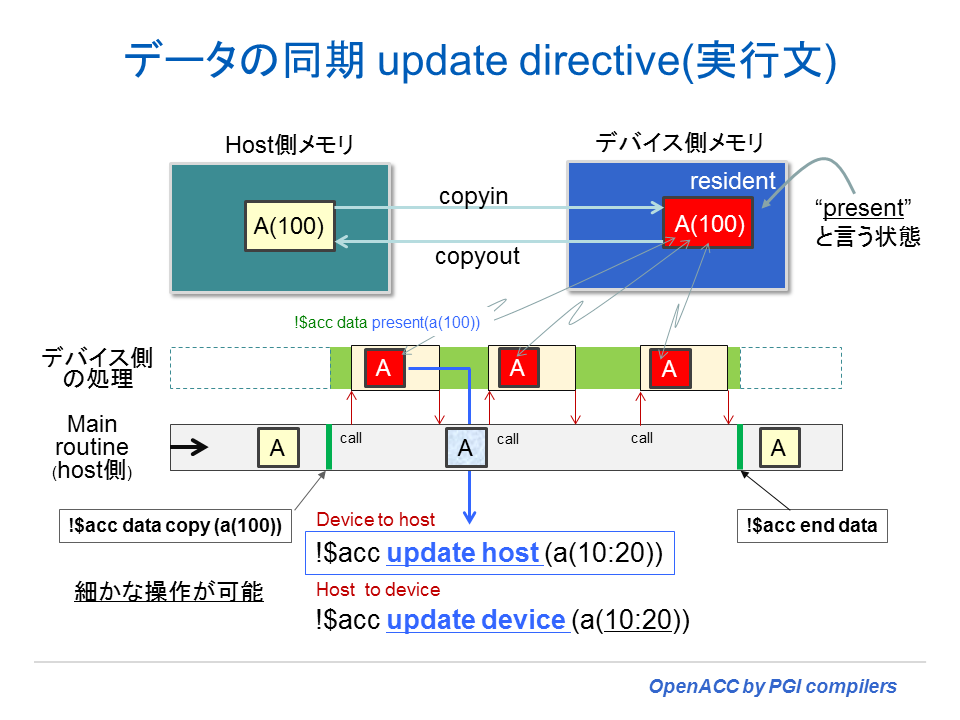
話を戻すと、実際のプログラムでは、A 配列が常にデバイス側で常駐していれば事足りるとは限らない。一時的に A 配列の全部あるいは、その一部をホスト側でも使用して計算処理を行う必要も多々ある。こうした場合の対策として、以下の図に示すような acc update host あるいは、acc update device と言う update ディレクティブ(実行文)が用意されている。この詳細に関しては、後の章で説明する。
動的にアロケートされた多次元配列(Cプログラム)の data 構文の clause の指定方法
この項では、メインプログラムから「手続き」を呼ぶ Cプログラム(C11)を実例として、data clause の指定の方法と C 言語特有の配列要素のアドレスの連続性について復習することにする。以下の C プログラムは Main ルーチンで a 配列、 b配列をアロケートし、b 配列にはその初期値をセットしている。この b 配列の内容を手続き smooth ルーチンへ引数で渡し、その計算結果として a 配列と b 配列の内容を得る。この smooth 手続きをデバイス上で計算する場合、ホスト側から b 配列をデバイスにコピーし、デバイスで実行後、a と b 配列の内容をデバイスからホスト側にコピーバックする必要がある。すなわち、ここでは、手続きに対して引数渡しの場合の data 構文、data clause の指定の仕方を説明する。また、Fortran 言語環境にはない C 言語特有のアロケートされた配列要素の「メモリ内での連続性」についても説明し、これがどのような影響があるかを考えてみる。
ソースプログラム: c3.c
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <sys/time.h>
#include <math.h>
#include <accel.h>
#include <accelmath.h>
typedef float *restrict *restrict MAT;
typedef float *restrict VEC;
void smooth( float **a, float *b[100], float w0, float w1, float w2, int n, int m, int niters );
void
smooth( MAT a, VEC b[100], float w0, float w1, float w2, int n, int m, int niters )
{
int i, j, iter;
#pragma acc data present(a[1:n-2][0:m],b[0:n][0:n])
#pragma acc kernels
{
for( iter = 1; iter < niters; ++iter ){
for( i = 1; i < n-1; ++i ){
for( j = 1; j < m-1; ++j ){
a[i][j] = w0 * b[i][j] +
w1*(b[i-1][j] + b[i+1][j] + b[i][j-1] + b[i][j+1]) +
w2*(b[i-1][j-1] + b[i-1][j+1] + b[i+1][j-1] + b[i+1][j+1]);
}
}
for( i = 1; i < n-1; ++i ){
for( j = 1; j < m-1; ++j ){
b[i][j] = a[i][j];
}
}
}
}
}
void
smoothhost( MAT a, VEC b[100], float w0, float w1, float w2, int n, int m, int niters )
{
int i, j, iter;
{
for( iter = 1; iter < niters; ++iter ){
for( i = 1; i < n-1; ++i ){
for( j = 1; j < m-1; ++j ){
a[i][j] = w0 * b[i][j] +
w1*(b[i-1][j] + b[i+1][j] + b[i][j-1] + b[i][j+1]) +
w2*(b[i-1][j-1] + b[i-1][j+1] + b[i+1][j-1] + b[i+1][j+1]);
}
}
for( i = 1; i < n-1; ++i ){
for( j = 1; j < m-1; ++j ){
b[i][j] = a[i][j];
}
}
}
}
}
void
doprt( char* s, MAT a, MAT ah, int i, int j )
{
printf( "%s[%d][%d] = %g = %g\n", s, i, j, a[i][j], ah[i][j] );
}
int
main()
{
MAT aa;
VEC bb[100];
MAT aahost;
VEC bbhost[100];
int i,j;
float w0, w1, w2;
int n, m, aerrs, berrs;
float dif, tol;
n = 100;
m = 100;
// Array 'aa' allocation -- Array address is not contiguous
aa = (float**) malloc( sizeof(float*) * n );
aahost = (float**) malloc( sizeof(float*) * n );
for( i = 0; i < n; ++i ){
aa[i] = (float*)malloc(sizeof(float) * m );
aahost[i] = (float*)malloc(sizeof(float) * m );
}
// Array 'bb' allocation -- Array address is contiguous
bb[0] = (float*)malloc(sizeof(float) * m * 100);
bbhost[0] = (float*)malloc(sizeof(float) * m * 100);
for( i = 1; i < 100; ++i ){
bb[i] = bb[i-1] + m;
bbhost[i] = bbhost[i-1] + m;
}
for( i = 0; i < n; ++i ){
for( j = 0; j < m; ++j ){
aa[i][j] = 0;
aahost[i][j] = 0;
bb[i][j] = i*1000 + j;
bbhost[i][j] = i*1000 + j;
}
}
w0 = 0.5;
w1 = 0.3;
w2 = 0.2;
#pragma acc data copyout(aa[1:n-2][0:m]),copy(bb[0:n][0:n])
{
smooth( aa, bb, w0, w1, w2, n, m, 100 );
}
smoothhost( aahost, bbhost, w0, w1, w2, n, m, 100 );
// verify a result
aerrs = berrs = 0;
tol = 0.000005;
for( i = 1; i < n-1; ++i ){
for( j = 1; j < m-1; ++j ){
dif = fabsf(aa[i][j] - aahost[i][j]);
if( aahost[i][j] ) dif = fabsf(dif / aahost[i][j]);
if( dif > tol ){
++aerrs;
if( aerrs < 10 ){
printf( "aa[%d][%d] = %12.7e != %12.7e\n", i, j,
(double)aa[i][j], (double)aahost[i][j] );
}
}
dif = fabsf(bb[i][j] - bbhost[i][j]);
if( bbhost[i][j] ) dif = fabsf(dif / bbhost[i][j]);
if( dif > tol ){
++berrs;
if( berrs < 10 ){
printf( "bb[%d][%d] = %12.7e != %12.7e\n", i, j,
(double)bb[i][j], (double)bbhost[i][j] );
}
}
}
}
if( aerrs == 0 && berrs == 0 ){
printf( "no errors found\n" );
return 0;
}else{
printf( "%d ERRORS found\n", aerrs + berrs );
return 1;
}
}
プログラムの構成は単純である。以下の模式図のように Main ルーチンから手続き smooth を呼ぶ形となっている。使用する配列は aa と bb であり、Main ルーチン側で bb の内容を設定しているため、この bb 配列をホストからデバイス側にコピーする必要がある。ホストとデバイス間のデータの流れは、まずここからスタートする。

ここで、実際の Data 構文並びに data clause を使ってみよう。Main ルーチンの中の手続き smooth を呼び出す部分で data 構文のプラグマを挿入する。また、Callee 側である smooth ルーチンの中では、転送されるデータがすでに、デバイスメモリに存在していることになるため、smooth ルーチン上で再度 copy 操作を行う必要がないことを指示する(present節を利用)。以下に示すようなディレクティブの挿入となる。
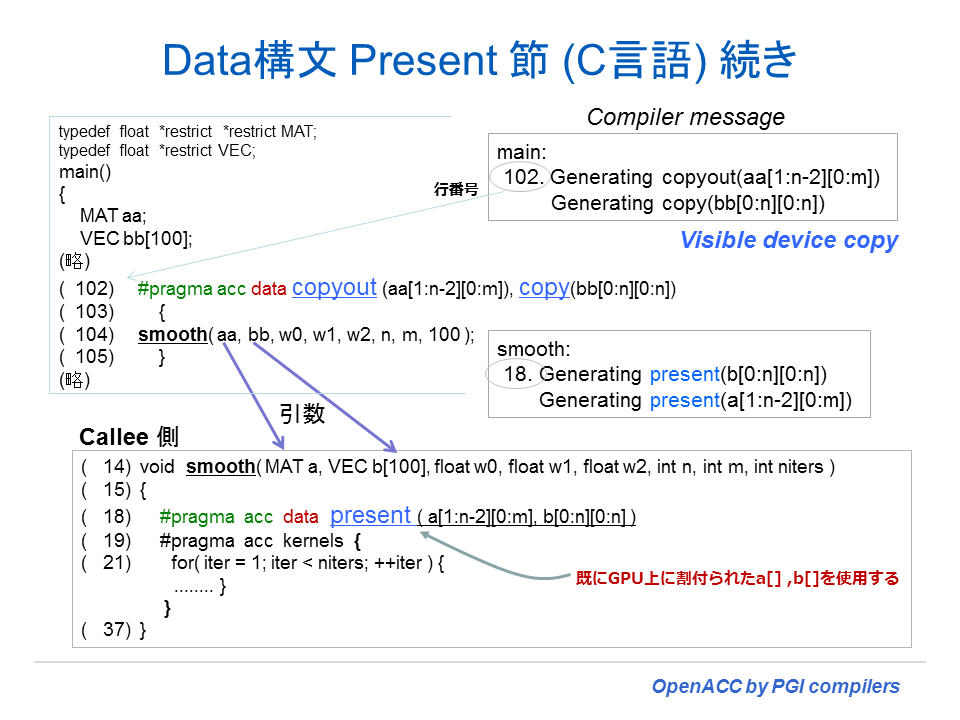
もう少し具体的に説明しよう。Main ルーチンの方では、smooth の呼び出しに対して data 構文を使って「データ領域」を設定する。さらに、data clause を使って、配列データ等のコピーに関する属性を指定する。ここで、copy、coyin、copyout 等の clause を使うことになる。これらの属性を決めるためには、プログラムの中身を見なければならない。smooth ルーチン内で aa 配列と bb 配列が、参照されるだけのものなのか、あるいは、参照かつ内容の更新がなされるのか、あるいは、単に処理において一時的に使用されるテンポラリ配列なのかが分かれば、ホストとデバイス間のコピーの属性を設定できる。このプログラムでは、実際の計算処理を行う smooth の処理において、aa 配列は一時的な配列の役割を担っているが、演算式の左辺側にあるため、内容の更新を伴う。ホスト上のプログラムの流れと同一の結果を生むためには、「ホストからデバイスへの aa 配列のコピー」は必要ないが、「デバイス側で更新された aa の内容をホスト側に戻す」必要がある。すなわち、すなわち、コピーの属性としては copyout( aa ) を採用するのが妥当である。
一方、bb 配列はどうであろう。これは、Main ルーチンで設定された初期値を持つため、「ホストからデバイスへのデータコピー(copyin)」は必須である。さらに、smooth 上では、bb 配列の値が更新されるため、その結果を「デバイスからホストへデータを戻す(copyout)」必要がある。この場合、コピーの属性は copy( bb )ということになる。
次に考えることは、コピーする際の配列の添字の長さ(各次元の要素数)の指定である。まず最初に大事な点から述べよう。C/C++ 言語において動的にアロケーションされた配列をデータ構文で指定する場合、その次元の長さは明示的に指定されなければならないと言う仕様がある。静的に宣言されたグローバルな多次元配列はコンパイラがそのサイズを理解できるが、動的にアロケートされた配列のサイズはコンパイル時には分からないため、ユーザがディレクティブを使って明示的にコンパイラに指示するしかないのである。もし、添字を明示的に指定しない場合、以下のようなエラーメッセージがコンパイル時に出力される。
PGC-S-0155-Cannot determine bounds for array [配列名]
以下のソース部分は、data 構文を指定している部分を抜き出して示したものである。Main 側、smooth 側共に同じ配列の添字サイズを指定している。呼ぶ側、呼び出し側共に同じ添字サイズの指定を行うことは正しい。さて、ここで注目すべきは、aa[1:n-2][0:m] の添字サイズ指定である(配列添字範囲の notation については上記を参照のこと)。Main プログラムでアロケーションしたサイズは、aa も bb も同じであり、n は、0~n-1 で、m も 0~m-1 の範囲を有する。bb 配列のコピーのサイズに関しては bb[0:n][0:m] としているため、当該対象として bb の全ての配列要素が指定されている。一方、aa 配列は [1:n-2][0:m] と言う部分配列の転送を指示していることになる。この指定方法は、使用する添字範囲だけを「厳密」に指定した場合の記述である。(もちろん、aa 配列も bb 配列と同じように aa[0:n][0:m] として全部の添字範囲をアロケートしコピーしても問題ないのであるが、ここでは OpenACC における「必要とされるデータの転送だけを行う」と言う原理原則を理解して欲しいために説明する。)
smooth ルーチンの for ループを見て欲しい。i と j ループの計算領域の範囲は、i = 1, n-1 で j = 1, m-1 である。ここで a 配列を見るとこのループ内で a[i][j] の値の更新のみを行う形となっている。すなわち、ループの計算領域では、a[1からn-1][1からm-1] の配列範囲の処理となる。これを OpenACC の配列添字の notation で記述すると、その添字範囲は a[1:n-2][1:m-2] と言う部分配列となる。これが、smooth ルーチンで計算時に必要な a 配列の必要とされる添字範囲と言うことになる。この添字範囲を data clause の中に記載する際に、注意して欲しいことがある。OpenACC の仕様(制限事項) では、一般事項として「メモリ上の連続したブロックとして指定しなければならない」という約束事がある。Row-major な並びの C 言語の場合は、copyout(aa[1:n-2][1:m-2]) ではなく、copyout(aa[1:n-2][0:m]) と言う形で指定する必要がある。これが原則論である。但し、動的にアロケーションした配列の場合だけは、この約束事は例外として扱われており、実は必ずしもこれに倣わなくても良い。ただ、どうであれ、共通の data clause の指定方法を採用しておいた方が間違いがないことは確かである。ここで、このプログラムでのデータコピーの動作を纏めると以下のようになる。
ホストからデバイスへ copyin (bb[0:n][0:n])
デバイスからホストへ copyout (bb[0:n][0:n], aa[1:n-2][0:m])
(Main ルーチン)
#pragma acc data copyout(aa[1:n-2][0:m]),copy(bb[0:n][0:n])
{
smooth( aa, bb, w0, w1, w2, n, m, 100 );
}
--------------------------------------------------------
(smooth ルーチン)
#pragma acc data present(a[1:n-2][0:m],b[0:n][0:n])
#pragma acc kernels
{
for( iter = 1; iter < niters; ++iter ){
for( i = 1; i < n-1; ++i ){
for( j = 1; j < m-1; ++j ){
a[i][j] = w0 * b[i][j] +
w1*(b[i-1][j] + b[i+1][j] + b[i][j-1] + b[i][j+1]) +
w2*(b[i-1][j-1] + b[i-1][j+1] + b[i+1][j-1] + b[i+1][j+1]);
}
}(以下、省略)
smooth ルーチン側の data clause の指定では、present 節を指定する。これは、すでに、a 配列と b 配列は、デバイス上のアロケーションとホスト側から必要なデータのコピーは終了していることをコンパイラに指示するものである。これによって、smooth ルーチンに入ってから、kernels 構文によってデフォルトで行われる、ホストとデバイス間のデータコピーは避けられることになる。

smooth ルーチンでは、#pragma acc data 構文のプラグマを明示的に記述したが、これが #pragma acc kernels 構文の「構造化ブロック」に対してだけ作用させるものであれば、以下のように kernels 構文の data clause として記述しても良い。この場合は、ディレクティブ(プラグマ)は 1 行で済む。
#pragma acc kernels present(a[1:n-2][0:m],b[0:n][0:n])
このプログラムをコンパイルすると、以下のコンパイル情報が得られる。data 構文に対する情報も記されており、特に、配列の添字範囲等は常に確認するように心がけた方が良い。
$ pgcc -acc -Minfo=accel -O2 c3.c -o c3.exe
smooth:
18, Generating present(b[0:n][0:n]) (例) 18 行目のソース文に対するメッセージ
Generating present(a[1:n-2][0:m])
19, Generating present(a[1:n-2][0:m])
Generating present(b[0:n][0:n])
Generating NVIDIA code
Generating compute capability 1.0 binary
Generating compute capability 2.0 binary
Generating compute capability 3.0 binary
21, Loop carried dependence due to exposed use of 'b[0:n][0:m]' prevents parallelization
Parallelization would require privatization of array 'a[i2+1][1:i1+i2+m-2]'
Sequential loop scheduled on host
22, Loop is parallelizable
23, Loop is parallelizable
Accelerator kernel generated
22, #pragma acc loop gang, vector(4) /* blockIdx.y threadIdx.y */
23, #pragma acc loop gang, vector(64) /* blockIdx.x threadIdx.x */
29, Loop is parallelizable
30, Loop is parallelizable
Accelerator kernel generated
29, #pragma acc loop gang /* blockIdx.y */
30, #pragma acc loop gang, vector(128) /* blockIdx.x threadIdx.x */
main:
102, Generating copyout(aa[1:n-2][0:m])
Generating copy(bb[0:n][0:n])
実際に実行を行い、PGI 簡易プロファイリングを行う。その中のホスト~デバイス間のデータの移動に関しての情報を調べてみる。この中におもしろい事実が浮き上がる。「106: data copyout reached 99 times」というメッセージがある。これは、106行目のソースコード(acc data 領域の終点)で、デバイスからホストへ a 配列と b 配列の内容のコピーを行っている事象であるが、物理的に 99 回のデータ転送が行われていることを示している。論理的には、 a 配列、b 配列のそれぞれ 1 回のデータ転送のはずであるが、物理的な I/O が 99 回実施されていると言う事実である。この回数は性能面で、少ないに越したことはない。なぜ、99回も物理的な I/O が発生しているのか?実は、a 配列の転送が 98 回で、b 配列が 1 回の合計 99 回の転送が実施されているのである。a、b 配列ともにその総量バイト数はほぼ同じにもかかわらず、その転送を実現するために回数が異なると言うことである。この理由を説明しよう。その前に、プログラムソース 102 行目の copyin の動作は bb[0:n][0:n] の転送であるが、これは 1 回のみの物理 I/O となっていることを理解しておこう。
$ export PGI_ACC_TIME=1 (PGIプロファイリングを ON)
$ ./c3.exe
no errors found
Accelerator Kernel Timing data
smooth NVIDIA devicenum=0
time(us): 1,805
18: data region reached 1 time copy に関する情報が記されていないため、
19: compute region reached 1 time データのコピーは行われていない
23: kernel launched 99 times
grid: [2x25] block: [64x4]
device time(us): total=1,011 max=21 min=10 avg=10
elapsed time(us): total=1,961 max=31 min=19 avg=19
30: kernel launched 99 times
grid: [1x98] block: [128]
device time(us): total=794 max=10 min=8 avg=8
elapsed time(us): total=1,776 max=90 min=17 avg=17
main NVIDIA devicenum=0
time(us): 1,313
102: data region reached 1 time data領域でデータのコピーが行われている
31: kernel launched 2 times
grid: [1] block: [128]
device time(us): total=304 max=291 min=13 avg=152
elapsed time(us): total=384 max=358 min=26 avg=192
102: data copyin reached 1 time 1回のみのデータ転送が記録されている。
device time(us): total=13 max=13 min=13 avg=13
106: data copyout reached 99 times 99回のデータ転送が記録されている。
device time(us): total=996 max=31 min=8 avg=10
aa[1:n-2][0:m] 配列の転送が、「物理 I/O 98回」で行われている理由は、data clause における部分配列の設定に因るものではない。これは、[1:n-2][0:m]と言う OpenACC の notation で、確かに「連続並びで転送」できるように指定されていることからも分かる。この問題の本質は、そもそもの aa 配列の動的アロケーションの方法にある。Main プログラムにおいて、aa 配列はポインタの配列によって二次元の配列をエミュレートして割付を行っている。この割付方法によって、配列要素のアドレスが連続で並ぶかどうかが変化する。
Main ルーチンで使用している配列 aa(a)と bb(b)は、メモリ内のアドレスの連続性を説明するために、異なるアロケーションの方法をとっている。aa 配列、bb 配列共に 2 次元配列として利用するが、以下のプログラムに示したとおり、そのメモリへの割付方法が異なる。**MAT ポインタで定義される aa[row,col] の割付方法では、一つの「行」方向の要素のアドレスは連続するが、各々の行同士は連続しない(例えば、a[10,10] の行列とすると、Row-major な並びである aa[0,0], aa[0,1], aa[0,2], .., aa[0,9] は連続するが、行が変わる aa[0,9] と aa[1,0] の間は連続しない)。一方、*VEC ポインタで定義される bb の割付方法は、配列が Row-major の順番で連続して割り付けられるようにする方法を採用している。
(参考)多次元配列の要素のメモリ上の配置について(Column-major、Row-major)
typedef float *restrict *restrict MAT;
typedef float *restrict VEC;
MAT aa;
VEC bb[100];
// Array 'aa' allocation -- 要素のアドレスは連続しないアロケーション方法
aa = (float**) malloc( sizeof(float*) * n );
for( i = 0; i < n; ++i ){
aa[i] = (float*)malloc(sizeof(float) * m );
}
// Array 'bb' allocation -- 要素のアドレスは連続するアロケーション方法
bb[0] = (float*)malloc(sizeof(float) * m * 100);
for( i = 1; i < 100; ++i ){
bb[i] = bb[i-1] + m;
}
そもそもホスト・メモリ上に割り付けられた aa 配列は「連続の並び」ではなく、各々の行同士が連続しないアドレス・マッピングとなっているため、ホストとデバイス間でデータの交換を行う時は、今回の場合、必ず、配列の「行方向の本数分」の物理 I/O が発生する。こうしたホストとデバイス間のデータコピーのオーバーヘッドは、それが重なるような状況になると大きな時間となる。従って、C 言語プログラムにおける「多次元配列に対する動的メモリアロケーション」は、出来る限り、連続並びで割り付けるようにした方が良い。
Fortran プログラムの例
前項で説明した C プログラムの内容を Fortran で記述し、プログラムをコンパイルして実行してみる。Fortran 言語の場合、多次元配列の動的なアロケーションで、前項の C プログラムの場合のような「配列要素の並びが不連続になる」ことはない。また、以下のような data clause の場合、例えば aa 配列のコピーすべき配列添字の長さ(各次元の要素数)の指定方法は、Fortran 標準の配列添字の書式(notation)に準ずる。aa(1:n,2:m-1) は、Fortran 文法における部分配列の表現であるが、これは OpenACC の仕様(制限事項) の「メモリ上の連続したブロックとして指定しなければならない」という約束事に沿って当該添字の範囲の指定を行っている。すなわち、配列の最後の次元を除き他の全ての次元では、その要素範囲を「フルの長さ」で指定しなければならないことから、一次元目は 1:n と言う全範囲を指定している。これは、Fortran 配列のメモリ上の並びが Colomn-major であるため、このような形態となる( C 言語の場合とは逆の並び方である)。なお、このプログラム例では、copyout(aa(1:n,2:m-1)) と言う指定を行っているが、必要となる部分配列の転送指定ではなく、aa 配列の全要素をコピーする(copyout(aa(:,:)) あるいは、copyout(a) と指定した場合でも、プログラムはもちろん正常に動作する。
ソースプログラム: f3.f90
!$acc data copyout(aa(1:n,2:m-1)), copy(bb)
アクセラレータに関するコンパイル情報は以下の通りである。
$ pgf90 -acc -Minfo=accel -O2 f3.f90 -o f3.exe
smooth:
9, Generating present(b(:,:))
Generating present(a(:,2:n-1))
Generating NVIDIA code
Generating compute capability 1.0 binary
Generating compute capability 2.0 binary
Generating compute capability 3.0 binary
10, Loop carried dependence due to exposed use of 'b(:n,:m)' prevents parallelization
Parallelization would require privatization of array 'a(i2+2,2:m-1)'
Sequential loop scheduled on host
11, Loop is parallelizable
12, Loop is parallelizable
Accelerator kernel generated
11, !$acc loop gang, vector(128) ! blockidx%x threadidx%x
12, !$acc loop gang ! blockidx%y
18, Loop is parallelizable
19, Loop is parallelizable
Accelerator kernel generated
18, !$acc loop gang, vector(128) ! blockidx%x threadidx%x
19, !$acc loop gang ! blockidx%y
main:
78, Generating copy(bb(:,:))
Generating copyout(aa(1:n,2:m-1))
実行した際のプロファイリング情報を以下に示す。ホスト~デバイス間のデータコピーの物理的な I/O の回数は、配列一つの指定で1回で済んでいる(前項 C プログラムの場合で述べた物理 I/O の回数の増える問題はない)。すなわち、配列の連続した要素を一つのブロックで転送処理を行っていることが分かる。
$ export PGI_ACC_TIME=1(プロファイリング ON)
$ ./f3.exe
0 errors found
Accelerator Kernel Timing data
/home/kato/GPGPU/PGItest/ACC/Lecture/f3.f90
smooth NVIDIA devicenum=0
time(us): 360
9: compute region reached 1 time
12: kernel launched 5 times
grid: [1x98] block: [128]
device time(us): total=317 max=274 min=9 avg=63
elapsed time(us): total=364 max=284 min=18 avg=72
19: kernel launched 5 times
grid: [1x98] block: [128]
device time(us): total=43 max=11 min=8 avg=8
elapsed time(us): total=91 max=21 min=17 avg=18
/home/kato/GPGPU/PGItest/ACC/Lecture/f3.f90
main NVIDIA devicenum=0
time(us): 51
78: data region reached 1 time
78: data copyin reached 1 time bb 配列のコピー(1回の物理 I/O)
device time(us): total=13 max=13 min=13 avg=13
80: data copyout reached 2 times aa、bb 配列のコピー(2回の物理 I/O)
device time(us): total=38 max=21 min=17 avg=19
Fortran の場合は、言語自体の特性によりコンパイラが厳密な配列の管理を行っているため、data clause の指定においては、配列添字の指定を行わなくても、単に copy( a ) とか copyin( b ) と言った配列名だけの指定ですむ場合が多い。ポーティング作業の初期においては、簡単に配列名の指定だけで data clause を記述してみることから始めれば良い。
[Reference]
- Michael Wolfe,The Portland Group, Inc., OpenACC Features in the PGI Accelerator C Compiler—Part 1
- Michael Wolfe,The Portland Group, Inc., The PGI Accelerator Compilers with OpenACC