OpenACC ディレクティブによるプログラミング
10章 OpenACC 2.0/2.5/2.6 の新しい機能、ディレクティブ概要
PGI の OpenACC 2.0/2.5/2.6 機能の実装状況
PGI 14.1 が 2014年1月にリリースされて以降、OpenACC 2.0 の機能が順次追加され、PGI 15.1(2015年)にて包括的にサポートした。PGI 16.1(2016年) から OpenACC 2.5、PGI 18.1 (2018年) から OpenACC 2.6の実装の追加を行なった。(PGIのサブスクリプションが有効な場合は、最新のリビジョンを使う権利を有します。)以下に、追加された機能をコメントする。
PGI 19.9(2019年9月)変更事項
- ループがきちんと入れ子になっていない限り、worker loopを vector loop 内に、または gang loop を worker loop またはvector loop 内に配置するサポートを削除しました。 この変更は、OpenACC 仕様の制限と一致しています。
- PGI にバンドルされている CUDA 10.1バージョンは、10.1 Update 1 から 10.1 Update 2 にアップグレードされています。詳細については、CUDA 10.1 リリースノートを参照してください。
PGI 19.7(2019年7月)変更事項
- OpenACC の data 節を記述していない data, enter data, exit data 構文に対してエラーメッセージが表示されるするようになりました
- ポインタ参照を含むカーネルループを並列化できる条件が変更されました
- 最新の OpenACC 仕様に従うために、コンパイラがループ境界またはループの最後で使用される集約メンバをどのように扱うかを変更しました
- OpenACC の host_data use_device コンストラクトに対するサポートの改善
- OpenACC C++ コンパイラへの値による * this ポインタのキャプチャのサポートを追加しました
- バンドルCUDA を 10.1アップデート 1 にアップグレード
PGI 19.4(2019年4月)変更事項
- PCAST Enhancements - C++ のサポートを追加し、pgi_compareディレクティブ使用時の -acc コンパイル依存関係を削除し、いくつかの一般的なパフォーマンス最適化を追加しました。(ドキュメンテーション)
PGI 19.3(2019年3月)変更事項
- CUDA Toolkit version 10.1 をフルポートしました。CUDA 10.1 toolkit コンポーネントを統合してコンパイル、リンクを行うためには。-ta=tesla あるいは -Mcuda コンパイラオプションに cuda10.1 サブオプションを指定する必要があります。(CUDA toolkit version に関して)
PGI 19.1(2019年2月)変更事項
- C およびC++ コンパイラは、OpenACC 計算領域で printf() 文を使用してフォーマットされた出力をサポートするようになりました。 flag、width、precision、size、および type の最も一般的なフォーマット指定子がサポートされています。 OpenACC 領域で printf() を使用すると、マルチコア CPU と GPU の両方で OpenACCアプリケーションを開発およびチューニングする際の基本的なデバッグおよびプログラマによるトレースに役立ちます。
- Compute Capability 7.5 の Turing アーキテクチャーのサポートを追加しました。
- システムに GPU または CUDA ドライバが見つからない場合、CUDA 9.2 がデフォルトのターゲットバージョンになりました。
- -ta=tesla のサブオプション [no]llvm は、[no]nvvmに改名されました。
PGI 18.7(2018年8月)変更事項
- Fortran 割り当て可能変数への代入のデフォルトの動作は、ホストと GPU のデバイスコード生成の両方で Fortran 2003 のセマンティクスに一致するように変更されました。 この変更は、カーネルディレクティブ内で Fortran の割り当て可能な配列の割り当てが行われる場合に、パフォーマンスに影響する可能性があります。 詳細および推奨される回避策については、Fortran 2003 Allocatables のパフォーマンスへの影響を参照してください。この変更は、コンパイルごとに -Mallocatable=95 オプションを追加することによって 18.7 より前の Fortran 1995 のセマンティクスの動作に戻すことができます。なお、OpenACC の kernels ループでも、以前のバージョンで並列化できたものが、PGI 18.7 以降で並列化できない状態になる場合がありますので、この場合は、 -Mallocatable=95 オプションを指定して下さい。並列化しているかどうかは、-Minfo=accel オプションを指定してコンパイラのメッセージを確認してください。
- Fortran、C、および C++ での集約データ構造のためのOpenACC 3.0 真のディープ・コピー・ディレクティブのドラフトの実装を追加しました。真のディープ・コピー・ディレクティブを使用すると、プログラムの異なるポイントに異なるメンバー・セットをコピーできる名前付きポリシーのサポートを含め、集約データ宣言内でホストとデバイスのメモリー間を移動するメンバーのサブセットを指定できます。 詳細については、 ディープコピーの概要を参照してください。
- OpenACC 自動コンパイルを含む PGI Compiler Assisted Software Testing(PCAST)機能のサポートが追加されました。 新しい -ta=tesla:autocompare コンパイラオプションを使用すると、OpenACC の計算領域が CPU と GPU の両方で重複して実行され、GPU の結果が CPU で計算された結果と比較されます。 PCASTは新しいランタイム pgi_compare または acc_compare API 呼び出しの形式で使用することもできます。 どちらの場合でも、PCASTは計算結果と既知の正しい値を比較し、データがユーザー指定の許容範囲内で一致しない場合はエラーを報告します。 両方の形式は、ホスト CPU と GPU 間の計算上の相違点を特定するのに役立ちます。また、異なるプロセッサアーキテクチャで実行するためにコンパイルされたプログラムの数値的な違いを調べるために、API 呼び出しをより一般的に使用できます。 新しい PCAST機能の使用の詳細については、PCAST 概要を参照してください。
- コンパイラは、コンパイルに使用するシステムにインストールされている CUDA ドライバと一致するように、デフォルトのCUDA バージョンを設定するようになりました。 CUDA 9.1 および CUDA 9.2 toolkit は、PGI 18.7 リリースにバンドルされています。 CUDA 8.0 や CUDA 9.0 を含む旧式の CUDA ツールチェーンは、サイズを最小限に抑えるために PGI インストールパッケージから削除されましたが、新しい共存機能を使用して引き続きサポートされています。 -ta=tesla に cudaX.Y サブオプションを指定しない場合の扱いは、使用するCUDA Toolkitのバージョン制御をご覧ください。
- デフォルトのNVIDIA GPU Compute Capability リストを変更しました。 コンパイラは現在、コンパイルするシステムにインストールされている GPU のものと一致するデフォルトの計算能力リストを作成します。 -ta=tesla または -Mcuda に Compute Capability のサブオプションを指定しない場合は、この変更が Compute Capability にどのように影響するかについてをご覧ください。
- PGI_ACC_POOL_ALLOC_MINSIZE のデフォルトサイズを 16B から 128B に変更しました。 この環境変数は、アクセラレータコンパイラの CUDA Unified Memory プールアロケータによって使用されます。 PGI_ACC_POOL_ALLOC_MINSIZE を 16B に設定すると、ユーザーは 18.7 より前の動作に戻ることができます。
- OpenACCエラー処理コールバックルーチンを使用して、GPU で実行中にトリガされたエラーをインターセプトする方法の例を追加しました。説明とコードサンプルについては、 OpenACCエラー処理を参照してください。
- すべてのプラットフォーム上のOpenACCアクセラレータ領域内でのアサーション関数呼び出しのサポートが追加されました
- PGI 18.7 以降、CC 2.0 用の executable は生成されません。CC3.0~7.0用のコードを生成できます。
PGI 18.5(2018年5月)変更事項
- CUDA 9.2をサポート。cuda9.2サブオプションを-ta= teslaまたは-Mcudaコンパイラオプションとともに使用して、統合されたCUDA 9.2ツールキットコンポーネントをコンパイルおよびリンクできます。
PGI 18.1(2018年2月)変更事項
- CUDA Toolkit 9.1の公式リリースの統合完全サポート。 コンパイラで使用されるデフォルトのCUDAツールキットを CUDA Toolkit 8.0に変更しました。コンパイラによって選択されたデフォルトの Compute Capability を cc35、cc50、cc60 に変更しました 。OpenACC 2.6 仕様をフルサポートしました。
PGI 17.10 (2017年11月)変更事項
- CUDA Toolkit 9.0の公式リリースの統合完全サポート。 CUDA 9.0 のワープシャッフル命令の変更を含む PGI 17.9 の制限を解決しました。CUDA 7.5 がデフォルト使用されます。 代わりに CUDA 8.0 または CUDA 9.0 を使用するには、-ta = tesla または -Mcuda のコンパイル時およびリンク時のオプションに cuda8.0 または cuda9.0 のサブオプションを追加します。
PGI 17.9 (2017年9月)変更事項
- CUDA Toolkit 9.0 RC をサポート。 但し、コンパイラによって使用されるデフォルトのバージョンは、CUDA 7.5 を使用します。 代わりに CUDA 8.0 または CUDA 9.0 を使用するには、-usta = tesla または -Mcuda のコンパイル時およびリンク時のオプションに cuda8.0 または cuda9.0 のサブオプションを追加します。
(注) CUDA 9.0インストールで PGI 17.9 コンパイラを使用すると、既知の問題があります。 特に、CUDA 9.0 では、新しい同期ワープシャッフル命令が導入されています。 この PGI リリースのコンパイラは、 acc routine vector を有するルーチンの中で、ワーピング中のスレッド間で値を共有し、ベクトルルーチン 0 からすべてのベクトルレーンへ値をコピーするために、より古い、今は信頼できないワープシャッフル命令を使用します。 この問題は、Kepler および Maxwell GPU でも発生する可能性があります。 この問題は、今後のPGIリリースで修正される予定です。
PGI 17.10 (2017年11月)変更事項
- PGI OpenACC と CUDA Fortran に Tesla V100 GPU のサポートが追加されました。 Tesla V100 は 、新しい NVIDIA Volta GV100 GPU に基づいて、より多くのメモリ帯域幅、より多くのストリーミングマルチプロセッサ、次世代 NVLink、新しいマイクロアーキテクチャの機能を提供し、パフォーマンスとプログラマビリティを向上させます。 OpenACC および CUDA Fortran プログラマ向けに、Tesla V100 は、x86-64 および OpenPOWER プロセッサベースのシステム上で CUDA Unified Memory 機能のハードウェアサポートとパフォーマンスを向上させます。 Tesla V100 GPU 用のコードを生成するには、オプション-ta=tesla あるいは -Mcuda のサブオプションとして cc70 を指定してコンパイルおよびリンクする必要があります。 Volta GPU をターゲットにする場合は、CUDA 9 toolkit を使用する必要があります。
- CUDA 9 toolkit の初期サポートが追加されました。 PGI 17.7 コンパイラとプロファイラで CUDA 9を使用するための要件:
- CUDA 9 toolkit のリリース候補(RC)またはアーリーアクセス(EA)版をインストールします。
- 環境変数 CUDAROOT を使用してCUDA 9 toolkit の場所を指定します。 たとえば、CUDA 9が /opt/local/cuda-9.0 にインストールされている場合は、プロファイラのコンパイル、リンク、または呼び出し時に環境変数 CUDAROOT=/opt/local/cuda-9.0を指定します 。
(一例) pgcc -fast -Minfo -acc -ta=tesla,cc70,cuda9.0 CUDAROOT=/opt/local/cuda-9.0 openacc_test.c
- サブオプション cuda9.0 は、-ta=tesla または -Mcuda のコンパイル時およびリンク時のオプションとともに使用します。
- CUDA Unified Memory のサポートが追加されました。 PGI 17.7 コンパイラは、Pascal および Volta GPU ハードウェア機能、NVLink、CUDA Unified Memoryを 活用して、GPUアクセラレーションされた x86-64 および OpenPOWER プロセッサベースのサーバで OpenACC および CUDA Fortran プログラミングを簡素化します。 CUDA Fortran または OpenACCの 割り当て可能なデータが CUDA Unified Memory に配置されている場合、明示的なデータ移動またはデータ指示は必要ありません。 これにより、割り当て可能なデータを大量に使用するアプリケーションの GPUアクセラレーションが簡素化され、アルゴリズムの並列化とスケーラビリティに集中できます。 この機能を有効にするには、 -ta=tesla:managed コンパイラオプションを使用します。 以前の PGI リリースでは、オプションでインストールされた評価機能としての用途で、CUDA Unified Memory のコンパイラサポートが提供されていました。
- CUDA Unified Memory のサポートのために cudaMallocManaged() への呼び出し回数を最小限に抑えるプールアロケータを追加しました。 プールアロケータは、 -ta=tesla:managed または -ta=tesla:pinned が使用されている場合、デフォルトで有効になります。
- Fortran の派生型の自動ディープコピー(deep copy)のベータサポートを追加しました。 この機能を使用すると、OpenACC を使用して最新のネストされたデータ構造を持つアプリケーションを Tesla GPU に移植することができます。 PGI 17.7 コンパイラでは、OpenACC のcopy、copyin、copyout、update ディレクティブに集約された Fortran データオブジェクトをリストして、集約データオブジェクト内のポインタベースのオブジェクトのトラバーサルと管理を含め、ホストとデバイスのメモリ間で移動させることができます。 フルディープコピー(full deep copy) を有効にすると、派生型の Fortran 変数をホストからデバイスまたはデバイスに移動するときに、ポインタと割り当て可能な配列を含むデータ構造全体が、ホストとデバイス間、またはデバイスとホスト、メモリ間でコピーされます。 ディープコピーを有効にするには、オプション -ta=tesla に deepcopy サブオプション(-ta=tesla,deepcopy) を指定します。 注意すべき2つの点として、多型データ型はサポートされておらず、重複するポインタが存在すると実行時エラーが発生する可能性があります。
- cuSOLVER ライブラリは cuBLAS および cuSPARSE ライブラリをベースにしており、高密度行列、スパース最小二乗ソルバおよび固有値ソルバの行列分解および三角解法ルーチンをサポートし、共分散行列を持つ行列のシーケンスを解くのに役立つリファクタリングライブラリを提供します。 PGI が提供するインターフェイスモジュールと、PGI 17.7 以降にバンドルされている cuSOLVER ライブラリの PGI コンパイル済みバージョンを使用して、CUDA Fortran およびOpenACC Fortran から最適化された cuSolverDN ルーチンを呼び出すことができるようになりました。 この同じ cuSolver ライブラリは、PGI OpenACC C/C++ から呼び出すこともできます。これは PGI コンパイラを使用して構築されているため、PGI OpenMP ランタイムと互換性があり、使用できます。
PGI 17.1 (2017年2月)変更事項
- if_present clause を update directive に追加しました。これは、データが存在していないとき、ランタイムエラーから no operation に挙動を変えるためのものです。
- 新しいオプショナルな finalize clause を exit data directive に追加しました。これは、動的な参照カウントをゼロにセットするために使用します。
- exit data directive の振る舞い方を、動的に参照カウントを減らすような挙動に変更しました。
- 新しい init, shutdown, set directives を追加しました。
- デフォルトの async queue 値を得る、あるいはセットするための新しい API routines を追加しました。
- 新しい定義による routine bind clause をサポートしました。
- _OPENACC の値を 201510に変更しました。
- OpenACC cache directive 内のデータ管理方法を強化し性能向上を行いました。
- CUDA 8.0 をサポートし、CUDA 7.5 がデフォルトとなりました。
- NVIDIA Compute capability 2.0 (Fermi) デバイス用の executable はデフォルトで生成されません。明示的に -ta=tesla,cc20 で生成する必要があります。今後のリリースで、cc20サブオプションは廃止される予定です。
PGI 16.10 (2016年11月)変更事項
- CUDA 8.0のプロダクション・リリースのサポート。
- NOpenACC cache directive の向上。
- アクセラレータ領域内の structs, unions, derived types サポートの強化
- atomic operations により拡張型のサポート
PGI 16.9 (2016年9月)変更事項
- NVIDIA Pascal GPUs 用の -ta=tesla:managed コンパイラ・オプションが有効となりました。このオプションは、cc60 サブオプションと共に使用することにより有効となります。
- NVIDIA Pascal GPUs (compute capability 6.0)用のネイティブな atomic 命令のサポートを追加しました。
PGI 16.7 (2016年7月)変更事項
- CUDA Toolkit 8 RC をベータ・サポートしました。現時点で正式な CUDA toolkit 8.0のプロダクション・バージョンがリリースされていないため、PGI 16.7 においては、ベータ機能としてのサポートの位置づけとなります。PGI 16.7 では、デフォルで CUDA 7.0 toolkit が使用されます。CUDA 7.5 あるいは 8.0 toolkit は、-ta=tesla あるいは、-Mcuda のサブオプションに cuda7.5 or cuda8.0 をコンパイル&リンク時に付加することで、これらの toolkit が使用されます。
- NVIDIA Pascal GPUs (compute capability 6.0)のサポートを追加しました。Pascal GPUをターゲットとする場合は、必ず NVIDIA cuda 8.0 RC を実装し、使用しなければなりません。また、Pascal上で実行するためには、コンパイル時に -ta=tesla あるいは、-Mcuda のサブオプションとして、cuda8.0 あるいは、cc60 を指定してコンパイル&リンクを行う必要があります。なお、-ta=tesla:managed オプションは、現在のところ Pascal GPU 上ではサポートしていません。このオプションは cc60サブオプションを指定すると抑止されます。Compute capability 6.0 は cc60 サブオプションを明示的に指定するとセットされます。あるいは、cuda8.0 サブオプションを使用することによって、暗黙に Compute capability 6.0 はデフォルトの compute capability に追加されます。
- PGI OpenACC C, C++ and Fortran compilers は、OpenACC 2.5 の機能である kernels 構文上の num_gangs、num_workers、vector_length clauses をサポートしました。この clause は、kernels 領域の起動や任意のサブルーチンコールが行われる際に、 gangs、workers あるいは vector lanes の数を決定するために使用されます。
- 自動変数(automatic variables) と acc routine directive 内部の private loop clause 内に含まれる配列の挙動が、OpenACC 仕様に準拠するように変更されました。このリリース前においては、自動変数や private 配列は、GPU スレッド当たり一つのみアロケートされていました。OpenACC の仕様では、acc routine gang あるいは acc routine worker内の自動変数、あるいは loop gang 上の private 配列は、gang に対して一度アロケートすることとしています。そして、gang 内の全ての workers と vector lanes間で共用されるものとしています。 acc routine vector あるいは a private array on a loop worker 内の自動配列は、各 worker に対して一度アロケートし、そして、全ての worker の vector lanes 間で共有されることとなります。 A private array on a loop vector は、各 vactor lane に対して一度アロケートされることとなります。16.7 リリースでは、自動配列とloop vector 上の固定サイズの private 配列に対してこの挙動をサポートします。以前のリリースでエラーとなるような挙動を示したプログラムは動作しない場合がありますのでご注意下さい。
PGI 16.5 (2016年5月)変更事項
- shared memory 内にサイズが変化する配列を置くために cache directive を使用することができます。ただし、これは -ta=tesla のサブオプション safecache が指定された時のみ、許されます。この変更は、コンパイラのデフォルトの挙動に影響を及ぼし、性能に密接に係わります。safecache サブオプションは、、ユーザが shared memory 内に置かれたデータ量が有効サイズを超えないと言う確信を持つ時だけ使用するべきです。ランタイム時に、shared memory のサイズを超えた場合、kernel launch failure が生じます。
PGI 16.3 (2016年3月)変更事項
- 'routine gang' 、あるいは 'worker'、あるいは 'vector' として宣言されたプロシジャー(手続き)へのコールを含む OpenACC parallel 構文をコンパイルする際、あるいは、このプロシジャー(手続き)自身をコンパイルする際、コンパイラは、vector_length を一つの CUDA warp のサイズである 32 に制限するように変更しました。また、こうしたプロシジャー(手続き)へのコールを含む OpenACC kernels 構文をコンパイルする際も同様に、コンパイラは vector clause の長さを 32 に制限します。この変更は、'loop vector' の後のベクトルレーンの同期を行う際のパフォーマンスの問題を解決するための措置です。
PGI 16.1 (2016年1月)変更事項
- 次の OpenACC 2.5 機能をサポートしました。
- OpenACC 2.5 で定義された profile/trace tools インタフェースが以前サポートしてきたインタフェースと置き換えられました。
- default(present) clause が C, C++, Fortran の Compute 構文でサポートされました。
- Reference Counting がデバイスデータのやり取りやライフタイムの管理に使用されます。
- copy, copyin, copyout and create data clauses は、present_or_copy の振る舞い方に変更(OpenACC 2.5 での変更)となります。
- cc_copyin, acc_create, acc_copyout and acc_delete API routines は、cc_present_or_copyin等 のような振る舞い方に変更(OpenACC 2.5 での変更)となります。
- Fortran allocatable 属性に対する declare create directive は、新しい振る舞い方に変更(OpenACC 2.5 での変更)となります。
- APIルーチン acc_memcpy_device を追加しました。Data APIルーチンの非同期バージョンを追加しました。
- gang clause を有する Orphaned loop内のリダクション操作(reduction clauseの使用)は、OpenACC 2.5 から明確に禁止されましため、その実装となりました。なお、routine gang clause を有した形でコンパイルされた手続き内で gang 並列性を生成するような orphaned loop も同様です。
- 配列、構造体メンバ、C++クラスメンバに関するリダクションは明確に禁止されました。
- gang/worker/vector/seq なしの acc routine の使用は、コンパイル・エラーとなります。
- -ta=maulticore における最内側ループのベクトル化を強化しました。
- OpenACC kernels 領域内の F90 ポインタの使用をサポートしました。
- コンパイラオプションである -ta=tesla:pin を -ta=tesla:pinned に置き代えました。pin サブオプションは、GPUへのデータ移動において、ユーザデータを使用する前に、動的にユーザデータを "pinned"します。新しい pinned サブオプションは、代わりにプログラムのアロケート時に pinned メモリを割り付けるように変更しました。OpenACCランタイムは、まず、データメモリが pinned されているかをテストします。もうし、そうであれば、pinned 空間から直接、転送するようにします。pinned サブオプションは、従来の pin サブオプションの時よりもより安定して機能します。
- -ta=tesla:managed を使用した時の全てのカーネルは、デフォルトで同期モードにて動作します。すなわち、 PGI_ACC_SYNCHRONOUS=1 がデフォルトとしてセットされます。この挙動は安全であるものの性能に影響を及ぼすかもしれません。カーネルを明示的に非同期に動作させるには、PGI_ACC_SYNCHRONOUS=0 をセットしてください。
- ACC_BIND 環境変数は、-ta=multicore の際、デフォルトでセットされます。ACC_BINDは、OpenMP における MP_BIND と同じようなものです。
PGI 15.10 (2015年10月)変更事項
- マルチコア x86 CPUをターゲットとした OpenACC プログラミングモデルをサポートする機能を正式に追加した。これは、OpenACC プログラムをマルチコアCPU上で並列実行動作させる機能。従来の GPU 上で OpenACC parallel Loop をオフロード実行させるためのオプションである -ta=tesla、-ta=radeon に加え、CPUのマルチコア上で同様な機能を提供する -ta=multicore オプションを追加することで、同じ OpenACC ソースコードを使用してシームレスかつ、スケーラブルなプログラミング環境を享受できる。
- OpenACCプログラムをマルチコア CPU あるいは マルチソケット CPU サーバの全てのコアを利用した並列実行ができるようにコンパイルが可能。
- PGIコンパイラの最適化・並列化のフィードバックを参考にしながら、OpenACC KERNELs ディレクティブを使ってマルチコ アCPUs と GPU 用にアプリケーションの並列化を徐々に行うことが可能。 Fortran, C, C++プログラムにおいて、GPUとCPUを含めた均一の並列プログラミング・モデルを使用することが可能。
PGI 15.9 変更事項
- CUDA 7.5に対応した。
- OpenACC Compute regions 内のスカラ、ならびに配列変数の自動プライベート化機能を追加した。
- OpenACC regions 内での Fortran computed goto 構文を使用できるようになった。
PGI 15.7 変更事項
- Titan X を含む Maxwell GPUs (CC 5.x)をサポートした。但し、Maxwell は浮動小数点演算器が極端に少ないためHPC用途では不向き。
PGI 15.5 変更事項
- OpenACC Fortran for NVIDIA GPUs and CUDA Fortran は、デバイス・カーネル内のデフォルト出力ユニット(PRINT * or WRITE(*,*))へのリスト指示 I/O をサポートしました。CUDA Fortran Programming Guide and Referenceマニュアルの 3.6.7 項に現在サポートしているデータ型等を説明しています。
PGI 15.4 変更事項
- CUDA 7.0に対応し。た
- PGI パッケージに新しいOpenACC SDK examples追加。
PGI 15.1(2015年)変更事項
- OpenACC directives/clauses の追加等
- OpenACC 2.0 を包括的にサポートした。(追加事項)
- Cache directive
- Auto loop clause
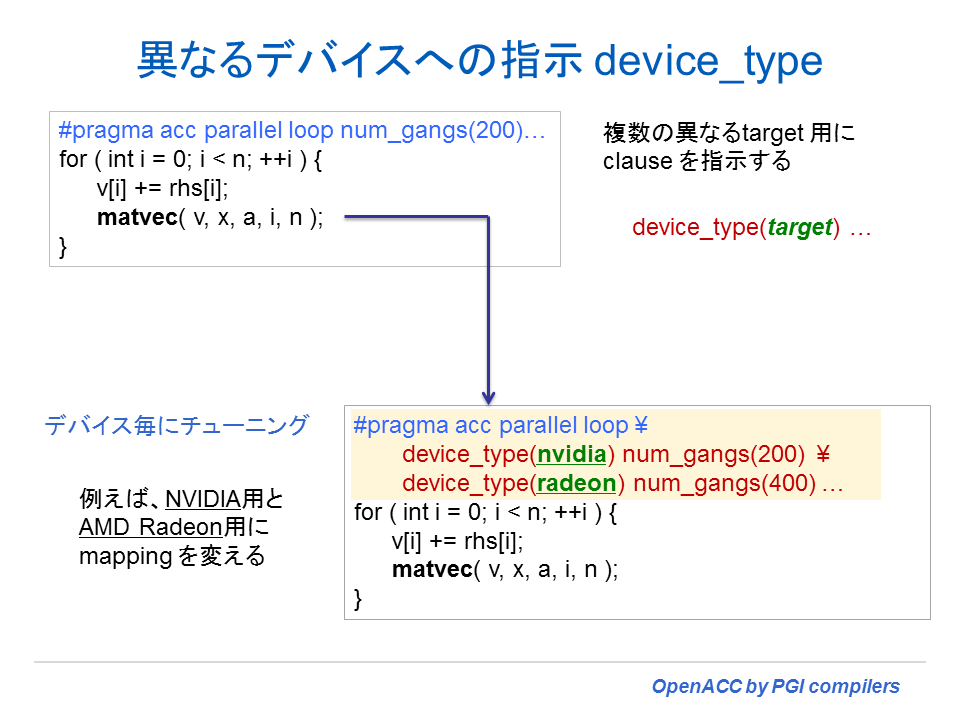
- Device_type clause
- Collapse clause
- Firstprivate clause
- Gang(num:) and gang(static:) loop subclauses
- Reduction in routine clause
- Use of complex data types in reduction clause
- CCUDA 6.0/6.5 and NVIDIA Kepler K40/K80 GPUs
- PGI パッケージに新しいOpenACC SDK examples追加
- OpenACC 2.0 を包括的にサポートした。(追加事項)
-
Present_or_
PGI 2015 では、copy, copyin, copyout and create clauses の挙動に関して、present_or_copy、present_or_copyin、present_or_copyout、present_or_create と同じように振る舞うように変更されました。この変更は、すでに存在する正しく動作するOpenACCプログラムの動作を変更するものではありません。たとえば、以前、「data clause内のデータがデバイス上にすでに存在する」といったランタイムのエラーメッセージで終了したプログラムは、そのまま停止せずに続行します。この挙動は、OpenACC仕様に取り込まれる予定の機能です。 -
Shortloop Clause
PGIコンパイラは、新しいloop clauseとして、shortloopを追加します。shortloop clause が vector clauseを有する loop directive の中で指定された場合、これは、コンパイラにループのトリップ・カウントが当該ループのために生成されるベクトル・レーンの数以下であることを知らせるものです。これは、kernel 領域内の loop directive 上の vector() clauseの値、あるいは、parallel 領域内の parallel directive 上の vector_length() の値が、ループのトリップ・カウント数よりも大きいということを意味します。この情報をコンパイラに伝えることで、ループに対してより効果的なコードを生成させることができます。 -
Expressions for Vector Length
以前のバージョンでは、parallel directive の vector_length clause 内の表現式や kernel region 内のloop directive の vector clause 内の表現式は、コンパイル時に分かるように定数を使った表現式であることの制約がありました。今回、PGIコンパイラは、この clause 内のランタイム表現式を使えるように変更しました。もし、その値がテーゲットとなるデバイスの上限を超えた場合、プログラムはランタイムでエラーとなります。現在のNVIDIA CUDAデバイスの上限値は、vector lengthとworkers の数の積として 1024 が上限となります。AMD Radeon デバイスの上限値は、vector length と workers の数の積として256が上限となります。
PGI 14.9 変更事項
- OpenACC 動作に関する変更
- CUDA 6.5 に対応した。
- CUDA 6.5 toolkit をバンドル。これに伴い、コンパイラのデフォルト toolkit は、以前のリビジョンのデフォルト CUDA 5.5 から CUDA 6.0 に変更された。少なくともシステムには CUDA 6.0 以上のドライバーの実装が必要。コンパイル・リンク時、CUDA 6.5 toolkit のソフトウェアを使用したい場合は、-tesla=cuda6.5 オプションを明示的に指定する必要がある。また、NVIDIA CUDA 6.5 のドライバーのインストールも必要となる。
- 並列性を定義する Cluases(gang,worker,vector)を指定していない acc routine ディレクティブは、seq clause が指定されているものとして扱う。
- CUDA Fortran 用の -Mcuda オプションを指定して、かつ、OpenACC オプション(-ta=tesla あるいは-taフラグを指定しない -accオプション)を指定してNVIDIA tesla 用のターゲットとしてコンパイル・リンクした場合、プログラムの OpenACC 部のデータ転送とカーネルのロウンチを同期させるための挙動は、STREAMゼロ(id=0) の挙動をデフォルトとする。これによって、OpenACC のデータ転送とカーネル起動は、他のCUDA同期処理と適切に進行できる。-Mcuda オプションを指定しないコンパイルを行う場合、CUDA STREAMゼロに関連したシリアル処理化を避けるため、プログラムの同期処理としては STREAM even が生成される。
PGI 14.7 追加機能
- OpenACC 2.0 機能の追加
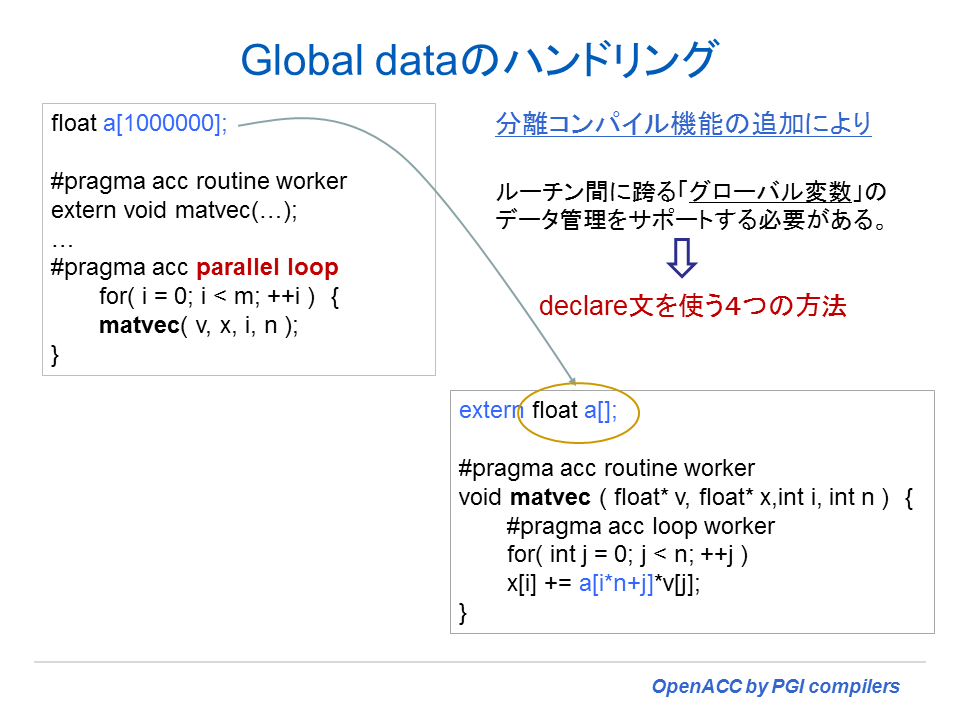
- OpenACC declare directives 上の C global (extern) 変数をサポート(10-2章 declare data ディレクティブによるハンドリング参照)
- OpenACC declare directives 上の Fortran module variables のサポート(10-2章 declare data ディレクティブによるハンドリング参照)
- Fortran,C/C++ の atomic ディレクティブのフル・サポート
- OpenACC directivesの wait clause のサポート
- wait directive の async clause のサポート
PGI 14.4 追加機能
- CUDA 6.0 をサポート
- OpenACC C++ サポートの拡張
- C++ thisポインタサポート
- C++ member functions
- C++ 上での routine ディレクティブのサポート
- data clause 内での C++ クラスメンバー配列のサポート(英文 PGI Release 2014 Notes 2.6.4 項参照)
- 新しい OpenACC 2.0 の機能等の追加
- 深いネストループ上での collapse ループディレクティブのサポート
- Parallel ディレクティブ内の firstprivate clause のサポート
- data clause 内での C structs と Fortran 派生データ型のメンバー配列をサポート(英文 PGI Release 2014 Notes 2.6.3, 2.6.5 項参照)
- Fortran,C/C++ の atomic ディレクティブの部分的なサポート(英文 PGI Release 2014 Notes 2.6.6 項参照)
- OpenACC から C/C++ CUDA-style atomics の呼び出しをサポート
- OpenACC data clause 内で Fortran common blocks名を使用できるようにした
PGI 14.1 追加機能
- CUDA 5.5 ならびに NVIDIA Kepler K40 GPUs をサポート
- AMD Radeon GPUs と APUs をサポート
- 新しい OpenACC 2.0 の機能等の追加
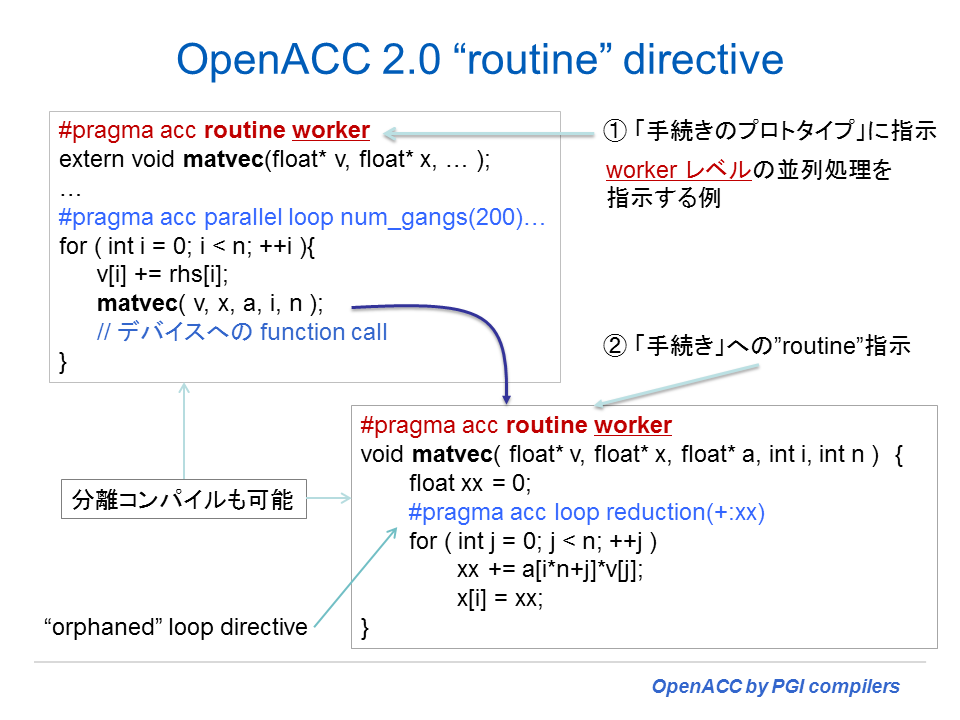
- Procedure call(Routineディレクティブ)機能追加、但し、C++コンパイラにはまだ未実装。AMD Radeon に対しては、AMD が OpenCL 2.0 をサポートするまで未実装。
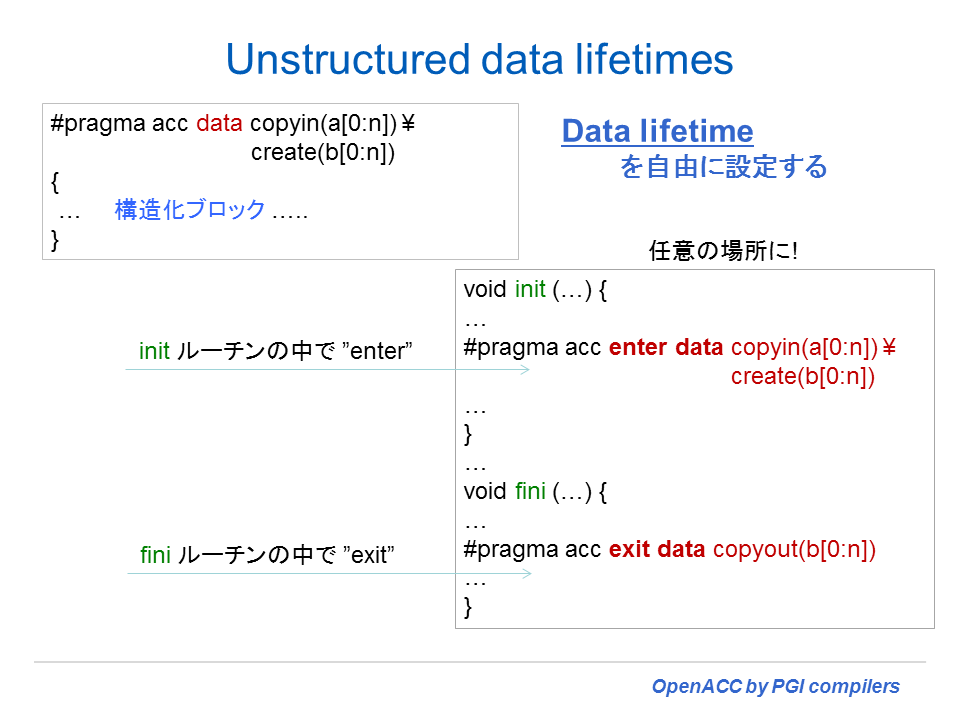
- Unstructured data lifetimes (Enter_data, Exit_data directives) 機能追加
- Host_data directive をサポート
- Declare ディレクティブにおける create と device_resident 節のサポート
- 多次元の動的な割付 C/C++ 配列のサポート
- OpenACC 2.0 API のサポート
制約事項 -- PGI 19.9 (2019年10月)現在
以下は、 現在のACC routine ディレクティブの制約事項である。
- 外部変数(external variables)は、acc routine ルーチン内では使用出来ない
-
Fortran において、整数値あるいは浮動小数点値を返す「関数」のみが routine ディレクティブでサポートされる。(PGI 17.1以降) -
C/C++ において、int、float、doubleあるいはvoid functioのみが routine ディレクティブでサポートされる。(PGI 17.1以降) - acc routine プロシジャー内のリダクションは、サポートしない(PGI16.10まで)。PGI 17.1 以降、NVIDIA GPU CC3.0 以降の GPU にのみ当該リダクションがサポートされた。
- Fortran 形状引継ぎ引数(配列の寸法を渡さない形態のもの)は、まだ、サポートされていない。
-
routine ディレクティブ上の bind clause はサポートしていません。(PGI 17.1以降)
以下は、既知の制約事項です。
- acc_shutdown が呼ばれた後に、別種のアクセラレータをターゲットとすることはできない。
OpenACC ディレクティブ上の wait clause はサポートされていない。wait ディレクティブ上の async clause はサポートされていない。- device_type clause の後には、任意の clauses は指定できない。
-
OpenMP parallel region 内にGPU アクセラレータ用の OpenACC を使用した時に問題が起きる。これに関しては将来、解決されるでしょう。(PGI 17.1以降)
以下は、既知のC++プログラム上の制約事項です。
- Variable-length array(VLA:可変長配列)は、OpenACC データ節内ではサポートしません。VLAは、C++ Standard ではありません。
- コンストラクタ、デストラクタを必要するクラス型の変数がdata clause内に現れた場合、適切に動作しません。
- 計算リージョン内では、「例外」は処理しません。
- メンバー変数は、host_dataコンストラクトのuse_device句では完全にサポートされていません。 これにより、実行時にエラーが発生する場合があります。
計算リージョン内の任意の関数コールはインライン展開しておかなければなりません。この中には、I/O処理や、クラス型の処理、ユーザ定義の処理、STL 関数、lambda 処理などの暗黙的に行われるインライン処理も含みます。
C++ 言語機能サポートを有効にするために必要な GCC のバージョン(C++14のGCC 5以降、C++17の GCC 7以降)と-ta=teslaへのオプションである nonvvm サブオプションの使用との間に競合が発生する場合があります 。nonvvm サブオプションは、システムにインストールされている GCC のバージョンとの互換性をチェックする CUDA Toolkit のコンポーネントを使用し、指定された最大バージョンより新しいバージョンでは動作しません。
GCC Version Compatibility with -ta=tesla:nonvvm、各ツールキットに対するサポートするGCCの最大バージョン
- CUDA 9.2 GCC 7.x まで
- CUDA 10.0 GCC 7.x まで
- CUDA 10.1 GCC 8.x まで
以下は、OpenACC 2.0/2.5 の将来的なサポート機能です。OpenACC 仕様的には 2.0 のDeclare link機能とNested parallelism機能を除外して、OpenACC 2.5 機能を提供しております。(PGI 17.10現在)
- Declare link (2.0)
- Nested parallelism (2.0)
- (Restricting cache clause variable refs to variables within cached region)
OpenACC 2.6 の機能実装状況表
| 機能 | Revision |
|---|---|
| serial and serial loop constructs | 18.1 |
| Fortran optional arguments support in data clauses | 18.1 |
| attach/detach clauses | 18.1 |
| implicit attach/detach behavior for other data clauses | 18.1 |
| no_create clause in compute and data constructs | 18.1 |
| if_present clause in host_data construct | 18.1 |
| if clause in host_data construct | 18.3 |
| New Device API Runtime Routines acc_get_property, acc_attach[_async], acc_detach[_finalize][_async] | 18.1 |
OpenACC 2.5 の機能実装状況表
| 機能 | Revision |
|---|---|
| Change in the behavior of the copy, copyin, copyout and create data clauses. | 15.1 |
| Change in the behavior of the acc_copyin, acc_create, acc_copyout and acc_delete API routines. | 15.1 |
| New default(present) clause for compute constructs. | 15.7 |
| Asynchronous versions of the data API routines. | 15.9 |
| New acc_memcpy_device API routine. | 15.7 |
| New OpenACC interface for profile and trace tools. | 16.1 |
| Change in the behavior of the declare create directive with a Fortran allocatable. | 15.1 |
| Reference counting added to device data. | 16.1 |
| Change in exit data directive behavior. New optional finalize clause. | 16.7 |
| New update directive clause, if_present. | 17.1 |
| New init, shutdown, set directives. | 17.1 |
| Change in the routine bind clause definition. | 17.1 |
| New API routines to get and set the default async queue value. | 17.1 |
| Num_gangs, num_workers and vector_length clauses allowed on the kernels construct. | 16.7 |
OpenACC 2.0 の機能実装状況表
| 機能 | Revision | 機能 | Revision |
|---|---|---|---|
| Kernels clauses | !$acc routine | 14.1 | |
| wait() | 14.7 | gang | 14.1 |
| default() | 15.1 | worker | 14.1 |
| device_type() | 15.1 | vector | 14.1 |
| seq | 14.1 | ||
| Parallel clauses | bind name() | 14.7 | |
| wait() | 14.7 | bind string() | 14.7 |
| default() | 15.1 | device_type() | 15.1 |
| device_type() | 15.1 | nohost | 14.7 |
| Loops clauses | #pragma atomic | 14.4 | |
| tile() | 15.1 | !$acc atomic | 14.4 |
| auto() | 15.1 | ||
| device_type() | 15.1 | Runtime routines | |
| acc_wait() | 14.1 | ||
| Update clauses | acc_wait_all() | 14.1 | |
| wait() | 14.7 | acc_async_wait_all | 14.1 |
| async() | 14.7 | acc_wait_async() | 14.4 |
| acc_copyin() | 14.1 | ||
| Declare clauses | acc_present_or_copyin() | 14.1 | |
| link() | -- | acc_create() | 14.1 |
| acc_present_or _create() | 14.1 | ||
| !$acc enter_data | 14.1 | acc_copyout() | 14.1 |
| if() | 14.1 | acc_delete() | 14.1 |
| async() | 14.7 | acc_map_data() | 14.1 |
| wait() | 14.7 | acc_unmap_data() | 14.1 |
| copyin() | 14.1 | acc_deviceptr() | 14.1 |
| create() | 14.1 | acc_hostptr() | 14.1 |
| pcopy() | 14.1 | acc_is_present() | 14.1 |
| pcreate() | 14.1 | acc_memcpy_to_device() | 14.1 |
| acc_memcpy_from_device() | 14.1 | ||
| !$acc exit_data | 14.1 | acc_update_device() | 14.1 |
| if() | 14.1 | acc_update_self() | 14.1 |
| async() | 14.7 | ||
| wait() | 14.7 | ||
| copyout() | 14.1 | ||
| delete() | 14.1 |
OpenACC 2.0 の新機能
以下は、2.0 の新機能をサマリー的に纏めたものである。
ROUTINEディレクティブに関しての説明が、以下の URL にアップされました。Using the OpenACC Routine Directive by Michael Wolfe, August 2014