OpenACC ディレクティブによるプログラミング
10-1章 Accelerator Compute 領域における Procedure call
- Routine ディレクティブ導入の背景
- 分割ファイル(separate compilation)のコンパイルオプション
- Routine ディレクティブのシンタックスと clauses(節)
- Routine ディレクティブの役目
- C における Routine ディレクティブ使用の単純な例
- Fortran における Routine ディレクティブ使用の単純な例
- Routineディレクティブ内の parallelism clauses
- vector 並列性を有する routine への適用例
- worker 並列性を有する routine への適用例
- gang 並列性を有する routine への適用例
- 3階層並列性の適用例(C)
- 3階層並列性の適用例(Fortran)
- Calling CUDA Device Routines from C
- Calling CUDA Device Routines from Fortran
Routine ディレクティブ導入の背景
PGI 14.1 から、OpenACC 2.0 仕様の routine ディレクティブがサポートされた(C++ コンパイラは、PGI 14.4 以降サポート)。以下の図でその概略を説明する。なお、PGI 13.10 以前は、この機能は使用出来ない。PGI 13.10 以前は、kernels 構文や Parallel 構文内の loop directive 領域(worksharing を行うループ)内に、Procedure の呼び出しあるいは、サブルーチン・コールが存在する場合、このループは OpenACC では並列化出来なかった。従って、アクセラレータ用の並列コードも生成出来なかった。このループを並列化するためには、当該 procedure をループ内にインライン展開する必要があった。しかし、手動、自動を問わずインライン展開出来ない場合もあるため、これは OpenACC ループの並列化における制約となっていた。特に、Procedure が別ファイルとしてモジュール化された現在のソース管理方法で使用する場合は大きな制約であった。
OpenACC 2.0 仕様において、こうした制約を取り除くために routine ディレクティブが追加された。routine ディレクティブの機能を実現するためには、分割したファイルをコンパイルしオブジェクトをリンクする技術(分割コンパイル技術)や複数のファイルのプログラム上で使用されるグローバル変数を扱う技術も共に提供する必要がある。前者の分割コンパイル技術に関しては、NVIDIA GPU 側のオブジェクトのリンカーが CUDA で提供されているため実現可能となった(AMD Radeon はまだこの機能を持っていない)。また、後者のグローバル変数を declare 構文で扱うことも PGI 14.7 から可能となったことで、プログラミングの自由度が広がった。
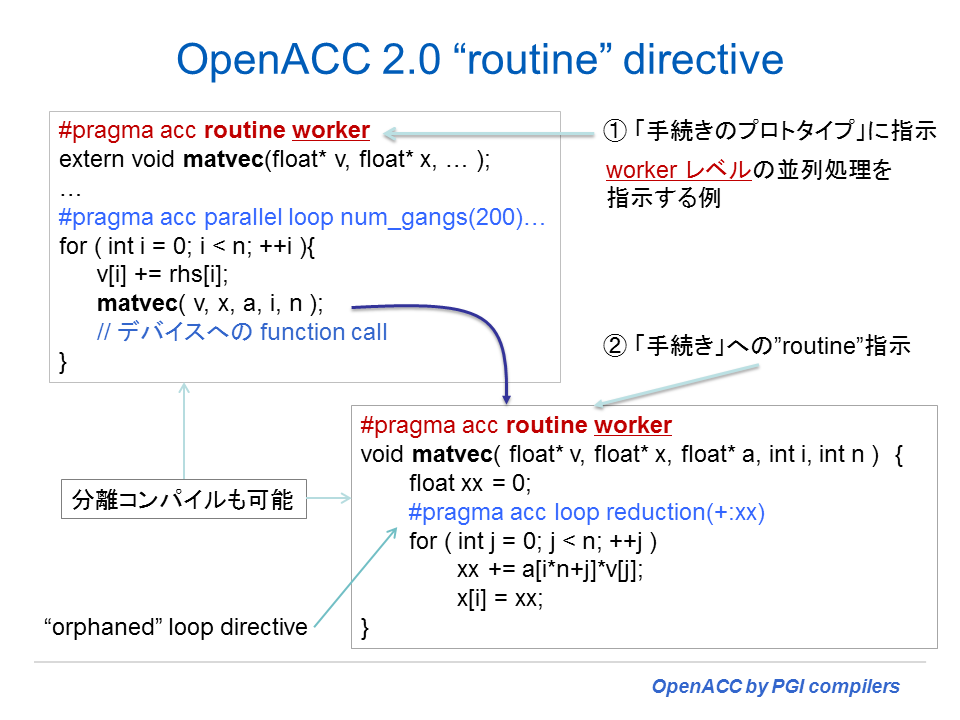
この章では、このディレクティブを使って Accelerator Compute 領域内の Procedure call の扱い方に関して解説する。以下の図は、Cプログラムにおける routine ディレクティブの使い方の概要を示したものである。


分割ファイル(separate compilation)のコンパイルオプション
複数のソースファイルに記述された OpenACC プログラムをデバイス用コードとしてリンクするには、ホスト用のリンカーだけでなく、デバイス用リンカーも使用する必要がある。特に、上述した acc routine ディレクティブを使用する場面では、異なるファイルに記述されたルーチンを call する場合も想定されるため、デバイス空間レベルにおいても各オブジェクトをリンケージできることが必要である。PGIコンパイラのドライバーは、まず、デバイス用のオブジェクトのリンクを行った後、ホスト用のオブジェクトとの連結を図る。全てのルーチンが一つのファイル内で完結している場合は、こうした分割コンパイルに伴うデバイス・オブジェクトのリンクの必要性はないが、一般には複数のソースファイルをコンパイルすることが多いため、PGIコンパイラは、分割コンパイルを想定したオプション -ta=tesla,rdc をデフォルトとしている。rdc とは relocatable device code の略である。このオプションは、必ず、デバイス用オブジェクトのリンケージをデバイス用リンカーを通して行うためのものである。
なお、-ta=tesla,nordc を明示的に指定すると、デバイス用のリンケージを行わないため、結果としてデバイスコードの undefined references のエラーが起こる。
-ta=tesla,rdc (デフォルト) -ta=tesla,nordc (デバイス用の分割コンパイル・リンケージを行わない)
Routine ディレクティブのシンタックスと clauses(節)
routine ディレクティブは、当該 procedure をホスト用だけでなくアクセラレータ用にコンパイルすることをコンパイラに指示するものである(デバイスコード内での function call を許すと言う意味を含む)。routine ディレクティブは、コンパイラに対してファイル内、もしくは procedure の call を行うルーチン内でアクセラレータ上でコールされる procedure の属性を伝える役割も担う。
【Syntax】 C and C++ の routine ディレクティブ #pragma acc routine clause-list new-line #pragma acc routine( name ) clause-list new-line Fortran の routine ディレクティブ !$acc routine clause-list !$acc routine( name ) clause-list Clause(節)は、次のものが指定できる gang worker vector seq bind( name ) bind( string ) device_type( device-type-list ) nohost
C, C++ では、引数の (name) を含まない routine ディレクティブは、function の定義の直前、あるいは、function プロトタイプの定義の直前に指定する。この場合、routine ディレクティブは、直後の function に対して適用される。一方、(name) を含む routine ディレクティブは、その function プロトタイプが許された場所であればどこでも指定でき、その name のスコープの範囲内でその function に適用される。但し、その function が定義、あるいは使用される前に指定しておく必要がある。
Fortran では、引数の (name) を含まない routine ディレクティブは、subroutine あるいは function 定義部分、あるいは、Intercace ブロック内の subroutine あるいは function に対する interface 実体内で指定する。この場合、routine ディレクティブは、当該 subroutine あるいは function に対して適用される。一方、(name) を含む routine ディレクティブは、 subroutine あるいは function あるいは module の定義部分に指定し、その名前のサブルーチン、関数に適用される。
routine ディレクティブを指定されたルーチン(accelerator routine)内に、さらにネストされたルーチンがある場合は、その各々のルーチン内に routine ディレクティブを指定する必要がある。
※なお、「accelerator routine」とは、アクセラレータ用に routine ディレクティブを指定した C or C++ 関数、Fortran サブプログラムのことを言う。
routine ディレクティブの制限事項
- device_typeの後に記述出来る節は、gang、worker、vector、seq、bind 節のみである。
- C, C++ では、routine ディレクティブを適用する関数において関数内の静的変数は使用出来ない。
- Fortran において save 属性を有する変数は、暗黙的、明示的に使用されるどちらの場合でも、routine ディレクティブを適用するサブプログラムにおいては使用出来ない。
PGI 16.9 現在における制限事項
- AMDの Radeon 上では、routine ディレクティブは使用出来ない。radeon 上では分割コンパイル機能がサポートされていないため、-ta=redeon を指定すると rdc サブオプションが抑止される。
- accelerator routine 内では外部変数(external variables)を使用してはならない。
- Fortran において、整数値あるいは浮動小数点値を返す「関数」のみが routine ディレクティブでサポートされる。
- C, C++ においては、int, float, double, あるいは void functions だけが accelerator routine としてサポートされている。
- accelerator routine の手続き内では、リダクション(総和等)の処理はサポートしていない。
- Fortran の形状引継ぎ配列の引数(assumed-shape arguments) は、まだサポートしていない。
PGI 16.1 以降における Open ACC 2.5 に準拠したことによる制限事項
- gang clause を有する Orphaned loop内のリダクション操作(reduction clauseの使用)は、OpenACC 2.5 から明確に禁止されましため、その実装となりました。なお、routine gang clause を有した形でコンパイルされた手続き内で gang 並列性を生成するような orphaned loop も同様です。
Routine ディレクティブの clauses(節)の説明
gang clause
gang clause は、procedure が gang clause を有するループを含む、あるいは含む可能性がある、あるいは、このような別の procedure を call すると言った場合に指定する。当該 procedure への call は、gang-redundant モードで実行されているコード内で行わなければならない。そして、全ての gang は、その call を実行しなければならない。例えば、routine gang ディレクティブを持つ procedure は、gang clause を有するループ内から呼ばれてはならない。なお、各 device type に対しては、gang、worker、vector、seq の中の一つだけが指定できる。
worker clause
worker clause は、procedure が worker clause を有するループを含む、あるいは含む可能性がある、あるいは、このような別の procedure を call すると言った場合に指定する。但し、当該 procedure は、gang clause を有するループを含んではならないし、あるいは、このような procedure への call を行うようなものであってはならない。auto clause を有する procedure 内のループは、worker モードあるいは vector モードのどちらかで実行されるかはコンパイラによって決定される。例え、当該 procedure が gang-redundant モードあるいは gang-partitioned モード内に置かれていたとしても、この procedure への call は、worker-singleモードで実行されるコード内に置かなければならない。例えば、routine worker ディクレティブを持つ procedure は、gang clause を持ったループ内から call されても良いが、worker clause を持つループ内から call されてはならない。なお、各 device type に対しては、gang、worker、vector、seq の中の一つだけが指定できる。
vector clause
vector clause は、procedure が vector clause を有するループを含む、あるいは含む可能性がある、あるいは、このような別の procedure を call すると言った場合に指定する。但し、当該 procedure は、gang あるいは worker clause を有するループを含んではならないし、あるいは、このような procedure への call を行うようなものであってはならない。auto clause を有する procedure 内のループは、vector モードで実行されるようにコンパイラによって決定される(決して worker モードではない)。当該 procedure が gang-redundant モードあるいは gang-partitioned モード、また、worker-single モード、あるいは worker-partitioned モード内に置かれていたとしても、この procedure への call は、vector-singleモードで実行されるコード内に置かなければならない。例えば、routine vector ディクレティブを持つ procedure は、gang clause あるいは worker caluse を持ったループ内から call されても良いが、vector clause を持つループ内から call されてはならない。なお、各 device type に対しては、gang、worker、vector、seq の中の一つだけが指定できる。
seq clause
seq clause は、procedure が gang、worker あるいは vector clause を有するループを含まない、あるいはこのような別の procedure を call しないような場合に指定することができる。auto clause を有する procedure 内のループは、seq モード(シーケンシャル実行)で実行される。この procedure への call は、任意なモードで実行されてよい。なお、各 device type に対しては、gang、worker、vector、seq の中の一つだけが指定できる。
bind clause
bind clause は、コンパイル時、あるいは、procedure を call する時に使用する名前を指定するためのものである。もし、その名前が識別子として指定されるならば、それはコンパイルされるか、あるいは、あたかもその名前が、コンパイルされている言語中で指定されていたものとして call される。
nohost clause
nohost clause は、コンパイラに対して、当該 procedure のhost 用のバージョンをコンパイルしないように指示するものである。この procedure に対する全ての call は、Accelerator Compute region 内に現れなければならない。もし、この procedure が他の procedure から call される場合、これら他の procedures は、nohost clause を有した routine ディレクティブでなければならない。
device_type clause
Routine ディレクティブの役目
acc routine ディレクティブには、以下の二つの役目がある。
- ディレクティブを指定したルーチン(accelerator routine)は、ホスト用のコードだけではなく、デバイス実行可能なコードとしてもコンパイルすると言うことをコンパイラに伝えること。C/C++ プログラムでは、このディレクティブを当該ルーチン、関数の直前に指定する。あるいは、ディレクティブの routine キーワードの後に括弧書きで当該ルーチン名を記述して任意な場所に指定する方法もある。また、Fortranでは、当該サブルーチン、あるいは関数内の宣言文領域に当ディレクティブを指定する。
- call されるルーチンが別ファイルに記述されおり、このルーチン(accelerator routine)はデバイスコードを作成する必要があると言うことをコンパイラに伝える役目もある。C/C++の場合、別ファイルに置かれているルーチン(accelerator routine)を外部関数としてプロトタイプ宣言している場合、当該プロトタイプにもディレクティブを指定する。
C における Routine ディレクティブ使用の単純な例
以下に示す単純な C プログラムを使って説明しよう。以下は、関数を含む一つのファイルからなるプログラムである。ファイル名は a1.c とする。以下の例は、PGI 15.10 バージョンを使用して実施した。
#include <math.h>
#pragma acc routine seq
float sqab(float a){
return sqrtf(fabsf(a));
}
acc routine ディレクティブは、コンパイラに「次のルーチンはアクセラレータコードを生成せよ」と伝えるためのものである。seq clause は、そのルーチン内のコードとこのルーチン内にから call される他のルーチンは、一つのデバイス・スレッドの中ではシーケンシャルに動作すると言うことを伝えるものである。
ここで、-acc オプションを付けてコンパイルすると、以下のようなメッセージが表示される。seq モードで acc routine が生成されたと言うメッセージである。このメッセージは、当該ルーチン(accelerator routine)が GPU 用にコンパイルされたと言うことを確認するためのものでもある。なお、コンパイラのデフォルトでは GPU 用とホスト用のコードの両方がコンパイルされる形となる。これによって、ルーチン sqab は、ホストコードからも OpenACC アクセラレート領域からも call することが可能となる(ホストだけで動作するコードとアクセラレータを使用するコードの二つが一つの executable ファイルに生成される)。
$ pgcc -acc -Minfo=accel -c a1.c
sqab:
3, Generating acc routine seq
この関数を「別のファイル」内に記述されたルーチンから call することができる。以下のメインプログラムを見てみよう。このプログラムでは、関数 sqab を call するループが、OpenACC parallel ループとして指定されている。同じファイル内で、sqab 関数はプロトタイプ宣言され、そして、acc routine ディレクティブは、このプロトタイプ宣言の前に記述されていることが分かる。
#include <stdio.h>
#include <stdlib.h>
#define N 409600
#pragma acc routine seq
extern float sqab(float);
int main(){
int i;
float *x;
x = (float *)malloc(N*sizeof(float));
for( i=0; i<N; ++i ) x[i]= rand();
printf("%f\n", x[0]);
#pragma acc parallel loop pcopy(x[0:N])
for( int i=0; i<N; ++i )
x[i] = sqab(x[i]);
printf("%f\n", x[0]);
free(x);
return 0;
}
$ pgcc -acc -Minfo=accel -O2 a1.c main.c
a1.c:
sqab:
3, Generating acc routine seq
main.c:
main:
17, Generating copy(x[:409600])
Accelerator kernel generated
Generating Tesla code
18, #pragma acc loop gang, vector(128) /* blockIdx.x threadIdx.x */
acc routine ディレクティブは以下のような記述方法(括弧の中に手続き名を指定する)で、プロトタイプの後でも指定できる。この方法は、プロトタイプがヘッダーファイル内に記述されている時などは便利な方法である。
// プロトタイプ宣言の直前に指定(一般的な指定法)
#pragma acc routine seq
extern float sqab(float);
// あるいは、プロトタイプの後でも指定可能だが、ルーチンが call される前に指定する
// この場合は、括弧書きでルーチン名を記述する(sqab)
#pragma acc routine(sqab) seq
. . .
void test( float* x, int n ){
#pragma acc parallel loop pcopy(x[0:n])
for( int i = 0; i i< n; ++i ) x[i] = sqab( x[i] );
}
. . .
// 手続き関数自身にも acc routine ディレクティブの指定が必要
#pragma acc routine seq
float sqab( float a ){
return sqrtf( fabsf( a ) );
}
コマンドラインで、-Minfo オプションと付けて二つのファイルをコンパイルしリンク手続きをとると、以下のようなメッセージが現れる。リンクの段階では、当該プログラムはリンク処理を行うべきホスト用コードとデバイス用コードの二つを持つことになる。PGIコンパイラは、ホスト用リンカー実施の前にデバイス用リンカーを呼びデバイス用のオブジェクトを結合した上で、デバイス・バイナリをホスト・バイナリの中に組み込む処理を行う。このようにして生成され、executable が正常に実行できるようになる。
もし、main.c 内の関数のプロトタイプ宣言の前に#pragma acc routine seq の指定がなければ、以下のようなエラーメッセージを出力する。OpenACC parallel ループ内に sqab 手続きがあるにもかかわらず、当該手続きの acc routine ディレクティブ指定がなされていないと言うメッセージである。
$ pgcc -acc a1.o main.c -Minfo
main.c:
PGC-S-0155-Procedures called in a compute region must have acc routine information: sqab (main.c: 19)
PGC-S-0155-Accelerator region ignored; see -Minfo messages (main.c: 17)
main:
17, Accelerator region ignored
19, Accelerator restriction: call to 'sqab' with no acc routine information
Fortran における Routine ディレクティブ使用の単純な例
次に Fortran で同じプログラムを書いてみよう。Fortran において acc routine ディレクティブを使用する上で、大事な点を先に述べる。
OpenACC "routine" を Fortran において使用する際は、対象となるサブルーチン(accelerator routine)の明示的なインタフェース(F90 interface) を記述しなければならない。この「明示的なインタフェース(F90 interface)」とは、あまり馴染みのない言葉かもしれないが、interface 文を使ってサブルーチンや関数の引数仕様を定義することである。実はこれによって、仮引数と実引数の整合性がコンパイル時にチェックされるのであるが、こうした情報が OpenACC コンパイル時に必ず必要となる。もし、interface が構築されていなければコンパイルの段階でエラーとなるが、MODULE を使わない、あるいはインターフェースを構築しなくとも可能な例外的な方法が一つある。これについては後述する。
一般に F90 スタイルで interface 文を使う場は MODULE 内 か、あるいは、MODULE を使わずとも caller 側の親ルーチンの宣言領域で当該 call するルーチン(accelerator routine)の interface を定義することもできる(なお、MODULE内に副プログラムの定義があると、明示的にインタフェースを定義しなくとも自動的にインタフェースが生成される)。ただ、前者の MODULE 内で定義しておけば、これを使用するプログラムの始めに USE 文で指定することで、明示的なインタフェースが伝播され簡単である。以下のプログラム例は、すでに sqab(a) 関数プログラムが存在するとして、それに対するインタフェース記述を MODULE 内に行ったものである。
上記の C プログラムと同じ sqab() 関数を指定しているファイルが以下の例である。acc routine ディレクティブを指定する場所は、対象となるサブルーチンあるいは関数(accelerator routine)の記述の直下(implicit文がある場合はその下)に置く。ここは一般的に宣言文を記述する部分である。以下の例では、MODULE内で sqab() の interface 定義の部分と実際の sqab() 関数定義の部分に !$acc routine ディレクティブの指定が必要である。
module mod_func !(新しくMODULEを定義する)
interface !インターフェース・ブロックで sqab を定義
function sqab(a)
!$acc routine seq !ここにも必要
real, intent(in) :: a
real :: sqab
end function sqab
end interface
end module mod_func
real function sqab(a) !実際の関数記述(既に存在していたルーチン)
!$acc routine seq !ここにも必要
real :: a
sqab = sqrt(abs(a))
end function
acc routine ディレクティブの対象となるルーチンの全てについて interface 文を使用した定義が必要というのも少々煩わしい。もう一つの簡便な方法がある。以下の MODULE を見て欲しい。実は、MODULE で定義されたルーチンは、明示的に interface 文で定義しなくとも、コンパイラが引数等のチェックを行うためのテーブルを作成(module data) し、結果として implicit な「インタフェース」を構築してくれる。従って、上述の module mod_func の記述は、以下のような形で MODULE の中に当該ルーチンを包括(contains) するだけでもよい。この場合でも、対象となるサブルーチンあるいは関数の記述の直下に acc routine ディレクティブを置くことが必要である。ここで、以下のファイルを a1.f90 とする。
module mod_func
contains
real function sqab(a)
!$acc routine seq
real :: a
sqab = sqrt(abs(a))
end function
end module
sqab() 関数を呼ぶメインプログラム(main.f90)を以下に示す。サブルーチン test 内の acc parallel ループ内で sqab() 関数(accelerator routine)が call されている。コンパイルコマンドも示した。
program main
integer, parameter :: N=409600
real, dimension(N) :: x
call random_number(x)
call test (x, n)
print *, "x(1)=", x(1)
end program
subroutine test(x, n)
use mod_func
real, dimension(*) :: x
integer :: n
integer :: i
!$acc parallel loop pcopy(x(1:n))
do i = 1, n
x(i) = sqab(x(i))
enddo
end subroutine
$ pgfortran -acc -Minfo=accel -O2 a1.f90 main.f90
a1.f90:
sqab:
3, Generating acc routine seq
main.f90:
test:
15, Generating copy(x(:n))
Accelerator kernel generated
Generating Tesla code
16, !$acc loop gang, vector(128) ! blockidx%x threadidx%x
acc routine ディレクティブの対象となる関数、サブルーチン(accelerator routine)は明示的なインタフェースを定義する必要があると前述したが、これを行わなくても良い方法が一つあるようだ。以下に示すプログラムで説明する。以下のファイルを main_c1.f90 とする。サブルーチン test の中に sqab() 関数を call するループを acc parallel としているが、この caller 側のサブルーチン test の宣言部で sqab() の external 宣言を行う。そして、その直下に !$acc routine(sqab) seq ディレクティブを指定する。ここで注意することは、routine(sqab) と言う風に括弧の中に当該手続き名 sqab を記述することである。
program main
integer, parameter :: N=409600
real, dimension(N) :: x
call random_number(x)
call test (x, n)
print *, "x(1)=", x(1)
end program
subroutine test(x, n)
real, dimension(*) :: x
integer :: n
integer :: i
real, external :: sqab !externalで外部関数であることを宣言
!$acc routine(sqab) seq !routine_name(sqab)を明示的に指定する
!$acc parallel loop pcopy(x(1:n))
do i = 1, n
x(i) = sqab(x(i))
enddo
end subroutine
一方、accelerator routine である sqab() 関数を含むファイル(c1.f90) の内容は以下の通りです。sqab() 関数の宣言部に必ず、!$acc routine ディレクティブを指定することが必要である。
real function sqab(a)
!$acc routine seq
real :: a
sqab = sqrt(abs(a))
end function
Routineディレクティブ内の parallelism clauses
acc routine ディレクティブは、そのルーチンで使用される並列性の種別を指定する必要がある。すなわち、gang, worker, vector あるいは、seq のどれか一つを指定することが必要である。
acc routine gang ディレクティブは、コンパイラに対して当該ルーチンが gang 並列性を有したループを含む、あるいは、gang 並列ループを有する別のルーチンを call すると言うことを伝えるものである。このようなルーチンはそれ自身が、上位の gang parallel ループ内から call されることがあってはならない。これは、gang 並列ループは、「ネスト」してはいけないという理由からである。
acc routine worker ディレクティブは、コンパイラに対して当該ルーチンが worker 並列性を有するルーチンであることを伝えるものであるが、gang 並列性が指定されていてはならない。このルーチンは、gang 並列ループ内から call され、worker あるいは vector 並列ループからは call されない。同様に、acc routine vector ディレクティブは、コンパイラに対して当該ルーチンが vector 並列性を有するルーチンであることを伝えるものであるが、gang あるいは worker 並列性が指定されていてはならない。これは、gang あるいは worker 並列ループ内から call されてもよいが、vector 並列ループからは call されない。
最後に、acc routine seq ディレクティブは、このルーチンは並列性を持たないことをコンパイラに伝えるものである。ルーチンを call した gang の 一つの worker の中の vector lane 上でシーケンシャルに実行する。
"seq" を使用した場合の並列ループ形態
subroutine foo()
!$acc routine seq
end subroutine
...
!$acc parallel loop gang
do I=1,N
!$acc loop worker
do j=1,M
!$acc loop vector
do k=1,P
call foo()
"vector" を使用した場合の並列ループ形態
subroutine foo()
!$acc routine vector
!$acc loop vector
do K=1,P
....
end subroutine
...
!$acc parallel loop gang
do I=1,N
!$acc loop worker
do j=1,M
call foo()
"worker" を使用した場合の並列ループ形態
subroutine foo()
!$acc routine worker
!$acc loop worker
do j=1,M
!$acc loop vector
do K=1,P
....
end subroutine
...
!$acc parallel loop gang
do I=1,N
call foo()
"gang" を使用した場合の並列ループ形態
subroutine foo()
!$acc routine gang
!$acc loop gang
do I=1,N
!$acc loop worker
do j=1,M
!$acc loop vector
do K=1,P
....
end subroutine
...
!$acc parallel
call foo()
!$acc end parallel
vector 並列性を有する routine への適用例
以下のプログラムは、acccelerator routine(ここでは、saxpy ルーチン)を vector 並列としてコード生成するように指示する場合の例である。このプログラムの特徴としては、ルーチン saxpy の中のループは、orphaned acc loop となっていることである。orphaned loop とは、一般にプログラム上、対象とするループが「並列領域(OpenACC では acc parallel や acc kernels のこと、OpenMP では omp parallel のこと)」の指定なしに、workshare を指示する構文(OpenACC では、acc loop 構文、OpenMPでは、omp do 構文)のみを指定したループのことを指す。この例では、Accelerator Compute 領域を構築している場所は、その上位の test ルーチン内のループへの parallel 構文適用であり、このループ内から saxpy が呼ばれている。そして saxpy ルーチン内では単に、acc loop 構文でループを指定しているだけなので、これが orphaned としての位置づけとなっている。acc routine ディレクティブを使用する際は、一般にこうした使い方となる。
acc parallel 構文で並列領域を指定した場合、その中で使用する acc loop構文ではベクトル長の指定ができない。一方、acc kernels 構文内の acc loop 構文では可能である。 acc parallel 構文でのデフォルトのベクトル長は 32 であるため、そのパフォーマンスに影響がある場合、これを大きくしたい場合がある。この場合は、acc parallel 構文内の vector_length clause を使ってベクトル長を変更する。この例では vector_length(64) を指定している。
module mod2
contains
subroutine saxpy(n,a,x,y)
!$acc routine vector ! vector並列性でコード生成を指示
integer,value :: n
real :: a, x(*),y(*)
integer :: i
!$acc loop ! このループは、Orphaned loopとなっている。
do i = 1, n
y(i) = a*x(i) + y(i)
enddo
end subroutine
subroutine test( x, y, a, n )
real :: x(n,n), y(n,n), a(n)
integer, value :: n
integer :: i
!$acc parallel pcopy(y) pcopyin(a,x) vector_length(64) ! acc parallel 領域の設定
!$acc loop ! このループは、デフォルトgang並列にて、並列化
do i = 1, n
call saxpy( n, a(i), x(1,i), y(1,i) )
enddo
!$acc end parallel
end subroutine
end module
program main
use mod2
integer, parameter :: n = 1000
real(4), dimension(n,n) :: x, y
real(4), dimension(n) :: a
integer :: i, j
y = 0.0
do i = 1, n
do j = 1, n
x(j,i) = real(j*j)
end do
a(i) = real(i*3)
end do
call test( x, y, a, n )
print *,"y=", (y(1,i),i=1,100)
end
$ pgfortran -O3 -Minfo=accel vec.f90 -acc
saxpy:
3, Generating acc routine vector
Generating Tesla code
10, !$acc loop vector ! threadidx%x
Loop is parallelizable
test:
20, Generating copy(y(:,:))
Generating copyin(a(:),x(:,:))
Accelerator kernel generated
Generating Tesla code
22, !$acc loop gang ! blockidx%x
$ PGI_ACC_TIME=1 ./a.out
y= 3.000000 6.000000 9.000000 12.00000
15.00000 18.00000 21.00000 24.00000
(snip)
Accelerator Kernel Timing data
vec.f90
test NVIDIA devicenum=0
time(us): 1,933
20: compute region reached 1 time
20: kernel launched 1 time
grid: [1000] block: [64] 64 vectorブロックで実行
device time(us): total=98 max=98 min=98 avg=98
elapsed time(us): total=308 max=308 min=308 avg=308
20: data region reached 1 time
20: data copyin transfers: 6
device time(us): total=1,231 max=600 min=4 avg=205
25: data region reached 1 time
25: data copyout transfers: 1
device time(us): total=604 max=604 min=604 avg=604
worker並列性を有する routine への適用例
以下の例は、上記の vector 並列性を有する routine への適用プログラムと同じものを使用しているが、一点だけディレクティブの指定方法が異なる。それは、subroutine saxpy への acc routine ディレクティブの指定が vector から worker に変更した部分である。 saxpy ルーチンに worker 並列性を指示すると、ルーチン内の acc loop に対して worker with vector の並列性でコードが生成される。ループの長さが大きな場合は、より性能の良いコードとなる。
module mod2
contains
subroutine saxpy(n,a,x,y)
!$acc routine worker ! worker並列性でコード生成を指示
integer,value :: n
real :: a, x(*),y(*)
integer :: i
!$acc loop ! このループは、Orphaned loopとなっている。
do i = 1, n
y(i) = a*x(i) + y(i)
enddo
end subroutine
subroutine test( x, y, a, n )
real :: x(n,n), y(n,n), a(n)
integer, value :: n
integer :: i
!$acc parallel pcopy(y) pcopyin(a,x) vector_length(64) ! acc parallel 領域の設定
!$acc loop ! このループは、デフォルトgang並列にて、並列化
do i = 1, n
call saxpy( n, a(i), x(1,i), y(1,i) )
enddo
!$acc end parallel
end subroutine
end module
program main
use mod2
integer, parameter :: n = 1000
real(4), dimension(n,n) :: x, y
real(4), dimension(n) :: a
integer :: i, j
y = 0.0
do i = 1, n
do j = 1, n
x(j,i) = real(j*j)
end do
a(i) = real(i*3)
end do
call test( x, y, a, n )
print *,"y=", (y(1,i),i=1,100)
end
$ pgf90 -acc -Minfo=accel -O3 worker.f90
saxpy:
3, Generating acc routine worker
Generating Tesla code worker + vector の並列構成で実行する
10, !$acc loop vector, worker ! threadidx%x threadidx%y
Loop is parallelizable
test:
20, Generating copy(y(:,:))
Generating copyin(a(:),x(:,:))
Accelerator kernel generated
Generating Tesla code
22, !$acc loop gang ! blockidx%x
$ PGI_ACC_TIME=1 ./a.out
y= 3.000000 6.000000 9.000000 12.00000
15.00000 18.00000 21.00000 24.00000
(snip)
Accelerator Kernel Timing data
worker.f90
test NVIDIA devicenum=0
time(us): 1,915
20: compute region reached 1 time
20: kernel launched 1 time
grid: [1000] block: [64x8] 8 workers with 64 vector
device time(us): total=67 max=67 min=67 avg=67
elapsed time(us): total=311 max=311 min=311 avg=311
20: data region reached 1 time
20: data copyin transfers: 6
device time(us): total=1,244 max=612 min=4 avg=207
25: data region reached 1 time
25: data copyout transfers: 1
device time(us): total=604 max=604 min=604 avg=604
gang 並列性を有する routine への適用例
以下の例は、subroutine test が gang 並列性を有する accelerator routine、そして subroutine saxpy が vector 並列性を有する accelerator routine として構成されているものである。このいずれのルーチンの acc loop も orphaned loop として位置づけられている。このような多段で accelerator routine を構成することもできる。
module mod1
contains
subroutine saxpy(n,a,x,y)
!$acc routine vector ! vector並列性でコード生成を指示
integer,value :: n
real :: a, x(*),y(*)
integer :: i
!$acc loop ! Orphaned loop
do i = 1, n
y(i) = a*x(i) + y(i)
enddo
end subroutine
subroutine test( x, y, a, n )
!$acc routine gang ! gang並列性でコード生成を指示
real :: x(n,n), y(n,n), a(n)
integer, value :: n
integer :: i
!$acc loop ! Orphaned loop
do i = 1, n
call saxpy( n, a(i), x(1,i), y(1,i) )
enddo
end subroutine
end module
program main
use mod1
integer, parameter :: n = 1000
real(4), dimension(n,n) :: x, y
real(4), dimension(n) :: a
integer :: i, j
y = 0.0
do i = 1, n
do j = 1, n
x(j,i) = real(j*j)
end do
a(i) = real(i*3)
end do
! acc parallel 領域の設定
!$acc parallel pcopy(y) pcopyin(a,x) num_gangs(n) vector_length(64)
call test( x, y, a, n )
!$acc end parallel
print *,"y=", (y(1,i),i=1,100)
end
$ pgf90 -O3 -Minfo=accel gang.f90 -acc
saxpy:
3, Generating acc routine vector
Generating Tesla code
10, !$acc loop vector ! threadidx%x
Loop is parallelizable
test:
15, Generating acc routine gang
Generating Tesla code
22, !$acc loop gang ! blockidx%x
Loop is parallelizable
main:
43, Generating copy(y(:,:))
Generating copyin(a(:),x(:,:))
Accelerator kernel generated
Generating Tesla code
$ PGI_ACC_TIME=1 ./a.out
y= 3.000000 6.000000 9.000000 12.00000
15.00000 18.00000 21.00000 24.00000
(snip)
Accelerator Kernel Timing data
gang.f90
main NVIDIA devicenum=0
time(us): 1,918
43: compute region reached 1 time
43: kernel launched 1 time
grid: [1000] block: [64]
device time(us): total=91 max=91 min=91 avg=91
elapsed time(us): total=309 max=309 min=309 avg=309
43: data region reached 1 time
43: data copyin transfers: 3
device time(us): total=1,216 max=612 min=6 avg=405
45: data region reached 1 time
45: data copyout transfers: 1
device time(us): total=611 max=611 min=611 avg=611
3階層並列性の適用例(C)
以下の例は、gang、worker、vector の parallelism clauses を理解するために、多段で accelerator routine を構成した例である。また、この例は、Cにおける連続域を確保する 3 次元配列のアロケーション例も示した。
#include <stdio.h>
#include <stdlib.h>
/* 1.0 を加算する関数 */
#pragma acc routine seq
float seq_r(float x) {
return x + 1.0f;
}
#pragma acc routine vector
void vect_r(int NZ, float *x) {
#pragma acc loop vector
for (int i = 0 ; i < NZ ; i++) {
x[i] = seq_r(x[i]);
}
}
#pragma acc routine worker
void worker_r(int NY, int NZ, float **x) {
#pragma acc loop worker
for (int i = 0 ; i < NY ; i++)
vect_r(NZ, x[i]);
}
#pragma acc routine gang
void gang_r(int NX, int NY, int NZ, float ***x) {
#pragma acc loop gang
for (int i = 0 ; i < NX ; i++)
worker_r(NY, NZ, x[i]);
}
/* NX*NY*NZの三次元配列. */
int main()
{
float ***x;
float val = 0.0f;
int i, j, k;
const int NX = 4;
const int NY = 8;
const int NZ = 5;
/* 連続域 三次元配列の作成 */
x = (float***) malloc(NX * sizeof(float**));
x[0] = (float**) malloc(NX * NY * sizeof(float*));
x[0][0] = (float*) malloc(NX * NY * NZ * sizeof(float));
printf("x[0][0] = %d %p %d\n", x[0][0], x[0][0], &x[0][0]);
/* ポインタの場所(rowとcolomn配列を特定配置*/
for (i = 0; i < NX; i++) {
x[i] = x[0] + i * NY;
for (j = 0; j < NY; j++)
x[i][j] = x[0][0] + i * NY * NZ + j * NZ;
}
/* 配列[] notationを使用する */
for (i = 0; i < NX; i++) {
for (j = 0; j < NY; j++) {
for (k = 0; k < NZ; k++) {
val = val + 1.0f;
x[i][j][k] = val;
}
}
}
#pragma acc parallel copy(x[0:NX][0:NY][0:NZ])
{
gang_r(NX, NY, NZ, x);
}
/* 配列を表示 */
for (i = 0; i < NX; i++) {
for (j = 0; j < NY; j++) {
for (k = 0; k < NZ; k++) {
printf("x[%d][%d][%d] = %f %d\n", i, j, k, x[i][j][k], &x[i][j][k]);
printf("(**x)[%d*NY*NZ+%d*NZ+%d] = %f %d\n", i, j, k, (**x)[i*NY*NZ+j*NZ+k], &(**x)[i*NY*NZ+j*NZ+k]);
}
}
}
free(x[0][0]);
free(x[0]);
free(x);
return 0;
} $ pgcc -acc -Minfo c_cont.c
seq_r:
6, Generating acc routine seq
vect_r:
11, Generating acc routine vector
Generating Tesla code
13, #pragma acc loop vector /* threadIdx.x */
13, Loop is parallelizable
worker_r:
19, Generating acc routine worker
Generating Tesla code
21, #pragma acc loop worker /* threadIdx.y */
21, Loop is parallelizable
gang_r:
26, Generating acc routine gang
Generating Tesla code
28, #pragma acc loop gang /* blockIdx.x */
main:
54, Generated 1 prefetches in scalar loop
71, Generating copy(x[:NX][:NY][:NZ])
Accelerator kernel generated
Generating Tesla code
$ a.out
sizeof(int**))= 8
x[0][0] = 17896080 0x1111290 17895808
x[0][0][0] = 2.000000 17896080
(**x)[0*NY*NZ+0*NZ+0] = 2.000000 17896080
x[0][0][1] = 3.000000 17896084
(**x)[0*NY*NZ+0*NZ+1] = 3.000000 17896084
x[0][0][2] = 4.000000 17896088
(**x)[0*NY*NZ+0*NZ+2] = 4.000000 17896088 (snip)
3階層並列性の適用例(Fortran)
以下の Fortran 例は、gang、worker、vector の parallelism clauses を理解するために、多段で accelerator routine を構成した例である。
module mod1
contains
subroutine gang(x, n)
!$acc routine gang
integer,value :: n
real :: x(n,n,n)
integer :: i
!$acc loop gang
do i = 1, n
call worker(x(:,:,i), n)
enddo
end subroutine
subroutine worker(x, n)
!$acc routine worker
integer,value :: n
real :: x(n,n)
integer :: i
!$acc loop worker
do i = 1, n
call vector(x(:,i), n)
enddo
end subroutine
subroutine vector(x, n)
!$acc routine vector
integer,value :: n
real :: x(n)
integer :: i
!$acc loop vector
do i = 1, n
call sequent(x(i))
enddo
end subroutine
subroutine sequent(y)
!$acc routine seq
real :: y
y = y + 1.0
end subroutine
end module
program main
use mod1
integer, parameter :: n = 4
real(4), allocatable, dimension(:,:,:) :: x
real(4) :: val
integer :: i, j, k
allocate(x(n,n,n))
val = 0.0
do k = 1, n
do j = 1, n
do i = 1, n
x(i,j,k) = val
val = val + 1.0
end do
end do
end do
!$acc parallel copy(x)
call gang( x, n )
!$acc end parallel
print *,"x=", x
end
$ pgf90 -acc -Minfo=accel 3para.f90 -O2
gang:
3, Generating acc routine gang
Generating Tesla code
10, !$acc loop gang ! blockidx%x
worker:
15, Generating acc routine worker
Generating Tesla code
22, !$acc loop worker ! threadidx%y
22, Loop is parallelizable
vector:
27, Generating acc routine vector
Generating Tesla code
34, !$acc loop vector ! threadidx%x
34, Loop is parallelizable
sequent:
39, Generating acc routine seq
main:
64, Generating copy(x(:,:,:))
Accelerator kernel generated
Generating Tesla code
$ a.out
x= 1.000000 2.000000 3.000000 4.000000
5.000000 6.000000 7.000000 8.000000
9.000000 10.00000 11.00000 12.00000
13.00000 14.00000 15.00000 16.00000
17.00000 18.00000 19.00000 20.00000
21.00000 22.00000 23.00000 24.00000
25.00000 26.00000 27.00000 28.00000
29.00000 30.00000 31.00000 32.00000
33.00000 34.00000 35.00000 36.00000
37.00000 38.00000 39.00000 40.00000
41.00000 42.00000 43.00000 44.00000
45.00000 46.00000 47.00000 48.00000
49.00000 50.00000 51.00000 52.00000
53.00000 54.00000 55.00000 56.00000
57.00000 58.00000 59.00000 60.00000
61.00000 62.00000 63.00000 64.00000
Calling CUDA Device Routines from C
OpenACC compute 領域から call される CUDA デバイスルーチンを使いたい場合とか、あるいは、acc routine ディレクティブで定義される手続き内からこのようなデバイスルーチンを使用したい場合を考える。PGI OpenACC コンパイラは、CUDA bolckIdx と threadIdx のインデックス体系上で並列ループのイテレーションのマッピングを行う。以下の単純なスカラ CUDA デバイスルーチンを見てみよう。これは、スカラ処理記述のため、bolckIdx と threadIdx を参照しない処理であるが、NVIDIA nvccコンパイラで、そのオブジェクトを作成する。なお、__device__ ならびに __host__ 属性を指定して、デバイスとホストの両方で使用可能なオブジェクトを作成する。以下のファイルを radians.cu とする。
extern "C" __device__ __host__ float radians( float f ){
return f*3.14159265;
}
今回は、nvcc バージョン 7.5 コンパイラを使用している。cuda toolkit 7.5 体系のオブジェクトが作成される。ここで大事なオプションは、-rdc=true である。relocatable code を作成することを意味し、最終のリンク時にデバイス用のリンカーを通す必要があるため、このオプションは必須である。その他に、arch=compute_35,code=sm_35 のオプションを指定して、cc35 のアーキテクチャ用のデバイスコードを作成する。
$ nvcc --version nvcc: NVIDIA (R) Cuda compiler driver Cuda compilation tools, release 7.5, V7.5.17 $ nvcc -c -rdc=true -gencode arch=compute_35,code=sm_35 radians.cu
OpenACC のメインプログラムは、acc parallel 領域内で radians と言う手続きを call するものである。外部関数 radians のプロトタイプの後に、acc routine(radians) seq ディレクティブを指定している。seq clause は、各デバイス・スレッドはこのルーチンを他のスレッドとは独立に call すると言うことをコンパイラに伝える意味を持つ。もし、CUDA デバイスルーチンが全てのデバイス・スレッドから call されることを想定した場合、特に、CUDA デバイスルーチンが __syncthreads のコールを含むような場合、プロトタイプへの acc rouitne ディレクティブには seq clause の代わりに、worker clause を使うべきであろう(そうしたループ特性を有するものが前提であるが)。こうしたルーチンは、並列実行のインデックスの決定のために blockIdx と threadIdx を使用する。worker clause は、対応するスレッドブロック内の全てのスレッドが同時に当該手続きを call することをコンパイラに直接指示するものである。PGI OpenACC コンパイラは、vector ループインデックスを計算するために、threadIdx.x を使用し、worker ループインデックスを計算するために、threadIdx.y を使用する。従って、CUDA デバイスルーチンは、これと同じように使用することが必要である。
以下のプログラムを使って radians.o をリンクしてみる。ファイル名を main.c とする。
#include <stdio.h>
#include <stdlib.h>
#define N 409600
extern float radians (float);
#pragma acc routine(radians) seq
int main(){
int i;
float *x;
x = (float *)malloc(N*sizeof(float));
for( i=0; i<N; ++i ) x[i]= rand();
printf("%f\n", x[0]);
#pragma acc parallel loop pcopy(x[0:N])
for( int i=0; i<N; ++i )
x[i] = radians(x[i]);
printf("%f\n", x[0]);
free(x);
return 0;
}
CUDA デバイスオブジェクトと PGI OpenACC オブジェクトをリンクする際には、以下のようなコマンドオプションが必要である。-acc は、OpenACC 用にコンパイル・リンクするためのオプション、-Mcuda は、PGI オブジェクトの CUDA 用のライブラリをリンクすることを指示するためのもの、そして、-ta=tesla,cc35,cuda7.5 にて、cc35 用のオブジェクトかつ、cuda7.5 の toolkit を使用してリンクルすることを指示している。cc35 用のオブジェクトの指示は、 nvcc コンパイラで生成したものが cc35 のものを作成したからである。このオプションにて、executable が生成される。
$ pgcc -V (コンパイラのバージョン)
pgcc 15.10-0 64-bit target on x86-64 Linux -tp sandybridge
$ pgcc -acc -O2 -Minfo radians.o main.c -ta=tesla,cc35,cuda7.5 -Mcuda
main.c:
main:
14, Loop not vectorized/parallelized: contains call
17, Generating copy(x[:409600])
Accelerator kernel generated
Generating Tesla code
18, #pragma acc loop gang, vector(128) /* blockIdx.x threadIdx.x */
$ a.out
1804289408.000000
5668342272.000000
Calling CUDA Device Routines from Fortran
Fortran ではデバイスルーチンは、subroutine あるいは function 文に attributes(device) を付けることにより記述される。以下の例のように、スカラの「デバイスルーチン」が MODULE 内で定義されている場合、OpenACC プログラムはその MODULE を使用し、OpenACC compute 領域から直接、そのデバイスルーチンを call することができる。以下に示す MODULE mod_func 内の関数は、CUDA Fortran による簡単なデバイス関数である。これを OpenACC parallel 領域から call する。なお、以下の a1.f90 ファイル内の real, value :: a と言う宣言文は F2003 仕様の宣言書式であるが、引数のアドレス参照の引用ではなく、値渡しの引数として受け取ることを意味する。今回のような単純な引数受け渡しの場合は、値渡しの方が速い場合が多い。
module mod_func ! a1.f90 ファイル
contains !
attributes(device) real function radians( a ) ! CUDA Fortran device routine
!$acc routine seq ! CUDA FortranプログラムにOpenACC directiveを入れ
real, value :: a ! moduleのinterface構成をコンパイラに作成させる
radians = a*3.1415926
end function
end module
subroutine test(x, n) ! a1_sub.f90 ファイル OpenACC program
use mod_func
real, dimension(*) :: x
integer :: n
integer :: i
!$acc parallel loop present(x)
do i = 1, n
x(i) = radians(x(i)) ! function call: radians のリンクする必要あり
enddo
end subroutine
program main ! main.f90 ファイル OpenACC program
integer, parameter :: N=409600
real, dimension(N) :: x
call random_number(x)
print *, "x(1)=", x(1)
!$acc data pcopy(x)
call test (x, n)
!$acc end data
print *, "x(1)=", x(1)
end program
a1.f90 ファイルは、CUDA Fortran 記述であるため、-Mcuda オプションが必ず必要である。さらに、当該 MODULE によって、function radians の implicit な interface を構築できるため、この中に acc routine ディレクティブを指定して、OpenACC compute 領域から procedure call 可能なルーチンであることをコンパイラに知らせる。従って、コンパイルオプションには -acc も指定する。その後のオブジェクトのリンクステージにおいても、この両者のオプションの指定は必要になる。
$ pgf90 -O2 -Minfo=accel -c a1.f90 -acc -Mcuda (OpenACCとCUDA Fortran 二つのオプションが必要)
radians:
3, Generating acc routine seq
$ pgf90 -Minfo=accel -O2 a1.o a1_sub.f90 main.f90 -acc -Mcuda
a1_sub.f90: (コンパイル用に-accオプションが必要
test: リンク時には-accと-Mcudaオプション必要)
7, Generating present(x(:))
Accelerator kernel generated
Generating Tesla code
8, !$acc loop gang, vector(128) ! blockidx%x threadidx%x
main.f90:
main:
7, Generating copy(x(:))
$ PGI_ACC_TIME=1 a.out
x(1)= 0.9079230
x(1)= 2.852324
Accelerator Kernel Timing data
main.f90
main NVIDIA devicenum=0
time(us): 743
7: data region reached 1 time
7: data copyin transfers: 2
device time(us): total=270 max=251 min=19 avg=135
9: data region reached 1 time
9: data copyout transfers: 1
device time(us): total=473 max=473 min=473 avg=473
a1.f90
test NVIDIA devicenum=0
time(us): 20
15: compute region reached 1 time
15: kernel launched 1 time
grid: [3200] block: [128]
device time(us): total=20 max=20 min=20 avg=20
elapsed time(us): total=334 max=334 min=334 avg=334
15: data region reached 1 time
19: data region reached 1 time
プログラムのもう一つの書き方
上記のプログラムの書き方ともう少し、アレンジしてみる。純粋な CUDA Fortran デバイス関数が a1.f90 ファイルに記述されている。
attributes(device) real function radians ( a ) ! a1.f90ファイル (CUDA Fortran)
real, value :: a
radians = a*3.14159265
end function
このルーチン用の interface 記述を以下の a1_mod.f90 ファイルに定義する。これは、OpenACC プログラム間で acc routine ディレクティブの関数であることを知らせるための interface である。以下のインタフェースにおいては、関数名に attributes(device) 属性は付けない(付けても良いが)。
module mod_func ! a1_mod.f90ファイル
interface ! attributes(device) を指定しない function 宣言を行う
function radians ( a )
!$acc routine seq
real, value :: a
real :: radians
end function
end interface
end module
program main ! main.f90ファイル
integer, parameter :: N=409600
real, dimension(N) :: x
call random_number(x)
print *, "x(1)=", x(1)
!$acc data pcopy(x)
call test (x, n)
!$acc end data
print *, "x(1)=", x(1)
end program
subroutine test(x, n)
use mod_func
real, dimension(*) :: x
integer :: n
integer :: i
!$acc parallel loop present(x)
do i = 1, n
x(i) = radians(x(i))
enddo
end subroutine
$ pgf90 -Minfo a1_mod.f90 a1.f90 main.f90 -acc -Mcuda -O2
a1_mod.f90:
a1.f90:
main.f90:
main:
7, Generating copy(x(:))
test:
19, Generating present(x(:))
Accelerator kernel generated
Generating Tesla code
20, !$acc loop gang, vector(128) ! blockidx%x threadidx%x
Fortran から CUDA C のデバイス関数をバインドする
さて、もう一つの例を示そう。以下の例は、CUDA C で記述された「デバイスルーチン(関数)」を Fortran から procedure call するものである。
extern "C" __device__ __host__ float radians( float f ){
return f*3.14159265; // radians.cu ファイル
}
CUDA C で記述された radians 関数の明示的な Interface を構築するために以下のプログラムを作成する。この interface は、MODULE内ではなく、radians 関数を使用するサブルーチン内で定義されている。以下の interface の定義の中で、bind(c) は、Cバインディングを使用して Fortran コード生成を行えるようにするものである。すなわち、Fortran の関数名として使うことを前提に、C の生成コードの中のルーチン名を修飾しないようにする。C言語オブジェクトのシンボル名規則と呼び出し規則を前提に Fortran プログラムとのバインディングを行う。C プログラムとのオブジェクト連結においては、この機能は必須となる。
subroutine test(x, n) ! b1.f90 ファイル
real, dimension(*) :: x
interface
real function radians( a ) bind(c)
!$acc routine seq
real, value :: a
end function
end interface
integer :: n
integer :: i
!$acc parallel loop present(x)
do i = 1, n
x(i) = radians(x(i))
enddo
end subroutine
program main ! main.f90 ファイル
integer, parameter :: N=409600
real, dimension(N) :: x
call random_number(x)
print *, "x(1)=", x(1)
!$acc data pcopy(x)
call test (x, n)
!$acc end data
print *, "x(1)=", x(1)
end progra
まず、CUDA C のデバイスルーチンをコンパイルしてオブジェクトを作成する。以下の nvcc は 7.5 バージョンを使用しているため、CUDA 7.5 toolkit を前提としたオブジェクトである。このオブジェクトを pgfortran コンパイラを使って他の Fortran プログラムとリンクする必要がある。オプションとして、-ta=tesla,cuda7.5 を指定して CUDA toolkit のバージョンを合わせることが必要である。
$ nvcc -c -rdc=true -gencode arch=compute_35,code=sm_35 radians.cu
$ pgf90 main.f90 b1.f90 radians.o -O2 -Minfo=accel -ta=tesla,cc35,cuda7.5 -acc -Mcuda
main.f90:
main:
7, Generating copy(x(:))
b1.f90:
test:
13, Generating present(x(:))
Accelerator kernel generated
Generating Tesla code
14, !$acc loop gang, vector(128) ! blockidx%x threadidx%x
$ a.out
x(1)= 0.9079230
x(1)= 2.852324
Accelerator Kernel Timing data
main.f90
main NVIDIA devicenum=0
time(us): 794
7: data region reached 1 time
7: data copyin transfers: 2
device time(us): total=269 max=250 min=19 avg=134
9: data region reached 1 time
9: data copyout transfers: 1
device time(us): total=525 max=525 min=525 avg=525
b1.f90
test NVIDIA devicenum=0
time(us): 30
13: compute region reached 1 time
13: kernel launched 1 time
grid: [3200] block: [128]
device time(us): total=30 max=30 min=30 avg=30
elapsed time(us): total=334 max=334 min=334 avg=334
13: data region reached 1 time
17: data region reached 1 time
[Reference]
- Michael Wolfe, Using the OpenACC Routine Directive
- Michael Wolfe, OpenACC Routine Directive Part 2