プログラムのプロファイルを取得する
時間の掛かる部分を特定する
PGIコンパイラによる GPU Computing シリーズ (3)

プログラムをチューニングしようとするときに、プログラムのどこの部分が時間が掛かっているかを知りたいはずです。我々が「チューニング」や「プログラム最適化」と称していることは、ずばりプログラムを高速化すると言うことと同じことなのですが、高速化はまず一番時間の掛かっている部分(「ホットスポット」と言う。)から攻めようと言う話になります。また、そのホットスポット部分が、並列化が可能であるかどうかと言ったことも判断してゆくことになります。プログラムの各部分の消費時間を分析することを「プロファイリング」と言います。ここでは、PGIコンパイラのツールを利用して消費時間に関するプロファイリングの方法を説明します。これにより、プログラムのホットスポットを把握し、最初にGPU並列を行う部分を絞り込みます。このページでは、この他に、Compute-Intensity(計算密度)指標の意味、プロファイル・フィードバックによる最適化、プロシジャー間最適化等についても触れます。
2010年3月12日 Copyright © 株式会社ソフテック 加藤
PGIの性能プロファイリング・ツール
我々がプロファイリングを行う目的は、単に、プログラムの時間の掛かっている部分を特定し、ルーチン単位あるいはソース行単位の消費時間分布を調べることだけで十分であると考えた方が良いでしょう。性能チューニングを業務としている人以外のユーザで、プロファイリング用のツールにこれ以上の機能を期待するのは、あまり意味のないことです。最近の「販売を目的とした」のプログラム分析ツールは、ほとんどの一般ユーザが使い切れないほどの多機能を有するものもありますが、一般のユーザがこうした専門性の高いツールを一体どのように使うのだろうかと思ったりもします。「ツール」さえあれば、何でも分かってしまうと言う錯覚を起こすのはやめましょう。筆者は、スーパーコンピュータやHPCの世界で、数多くのプログラム性能最適化の経験を有しますが、こうした経験から言わせてもらえば、一般のユーザにとっての「プログラム最適化」のためのプロファイリングは「プログラムの消費時間とその場所」の把握さえできれば十分であると断言できます。仮に、分析ツールでプロセッサの挙動まで含めた詳細な性能分析ができたとしても、その診断結果を見て、性能を大胆に改善しうる具体的なプログラムの改変・変更を行うことができるか?と言うことになります。さらに、今のプロセッサ技術は、キャッシュを介在させたメモリ階層構造のため、これを見据えた最適化となると、プログラムの構造自体を変える必要もあります。こうしたことを行うのは、一般のユーザにとってかなり至難の業となります。
特に、シミュレーション用のプログラムを利用する立場の一般の研究者やユーザの方にとってのプログラム性能最適化の最初のステップは、単純にプロファイルを取得し、これを見て、どの部分がホットスポットであるかを認識し、性能最適化を行う価値がある部分か、あるいは、並列化の対象となり得るか等の見解を持つことです。PGIのプロファイリングのツールには、pgprof と言う GUI ベースの分析ツールがあります。「プロファイリングのデータ」自体は、様々な方法でその性能データを取得できます。以下は、PGIのプロファイリングの方法を纏めたものです。いくつかの方法があるのですが、このページでは、簡単にプログラムのプロファイリングデータを取得できる pgcollect ツールを利用してデータを取得し、pgprof ツールでその情報を見ると言う方法を説明します。なお、以下の各方法については、PGI Tools Guide に説明してます。また、PGI のコラム A New Direction for PGI Performance Profiling にても説明しています。

これからPGIアクセラレータ並列の説明で使用するプログラム
これからの連載での説明に用いる OpenMP プログラムは、OpenMP.org で提供している Fortran サンプル・プログラムを使用します。これは、以前のコラム「マルチコアCPU上の並列化手法、その並列性能と問題点」上で紹介しました。ソースプログラムは、そのページをご参照下さい。このプログラムは、ヘルムホルツ式を差分で離散化したものをヤコビ反復法で解くものです。これから連載では、現時点のGPUハードウェア仕様が、単精度が勝っているため、単精度版のソースプログラム(single-jacobi.f)を使用して説明していきます。
プロファイルデータを取得する
プロファイルデータを取得する方法を説明します。以下の例のように、任意のコンパイル・オプションを付けてコンパイルし、実行モジュールを作成します。pgcollect ツールを使用する場合は、特段、-Mprof=*** のプロファイル用オプションを付ける必要はありません。ただし、オプションの中に、-Minfo=ccff を付加すると、"Compiler Feedback"情報(CCFFと言う)が保持され、後の pgprof 分析ツール上で、コンパイル時に得たソースプログラムに関する各種情報が保持されますので、これは付加して下さい。-Minfo=ccff は、「プログラムが最適化できたか、あるいは、できない理由」、「どの程度、データがアクセスされるかを示す Compute intensity 情報」、「手続き間の関係」等の諸々の情報を保持するように指示するオプションです。さらに、pgprof 分析ツールを使うことで、それらの情報に関係するソース行に関連させて表示できるようになります。CCFFに関する詳細は、PGI の記事をご覧下さい。
コンパイル&リンク
$ pgfortran -fast -Minfo=ccff -o jacobi single-jacobi.f
pgcollect ツール下で実行、実行後、性能収集ファイル pgprof.out が生成される
$ pgcollect -time jacobi
Input n,m - grid real*4 in x,y direction N= 5120 M= 10000 Input alpha - Helmholts constant Input relax - Successive over-relaxation parameter Input tol - error tolerance for iterative solver Input mits - Maximum iterations for solver Time measurement accuracy : .10000E-05 Total Number of Iterations 101 Residual 1.1052383E-11 Solution Error : 7.1508897E-05 Elpased Time (Initialize + Jacobi solver + Check) : 11.804 FORTRAN STOP
PGPROFツールの使用 (GUIが起動)
$ pgprof -exe jacobi
pgprof ツールを起動する
pgprof コマンドを起動すると以下のような画面が現れます。
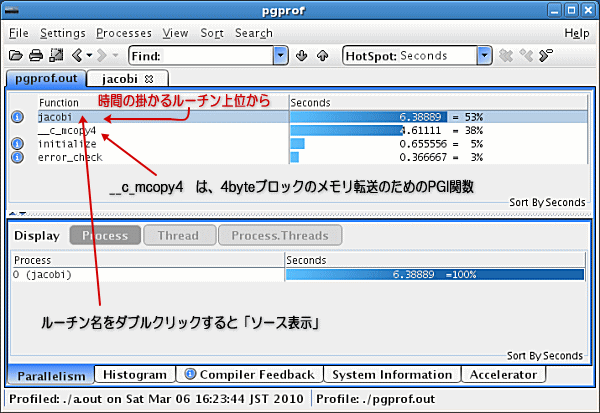
上記の画面では、「jacobi」と言うルーチンの消費時間が全体の53%を占めていることが分かります。また、2番目の__c_mcopy4 は、ユーザプログラムの「ルーチン名」ではなく、PGIのシステム関数名です。pgcollect のプロファイリング手法は、時間ベースのサンプリング方法を使用しており、ユーザルーチン、PGIシステム関数・ルーチンを問わず、性能データをサンプリングするため、ユーザルーチン以外のシステムルーチン・関数も出力されます。例えば、__c_mcopy4 と言うのは、メモリロードしストアする(データコピー)を行うためのPGIシステム関数です。これに関しては、それなりのCPU時間(38%)を占めているためメモリ・アクセスの比重が大きいのだろうと言う予想がつきます。こうしたメモリアクセス用に最適化されたルーチンは、独立にプロファイリングされていますが、実際は、各ユーザルーチンの中のメモリロード・ストアの中で使用されています。ルーチンのソース表示内で、さらにアセンブリ表示して、「__c_mcopy4 」という文字列で検索すると、どの部分でこの関数が使用されているか分かります。このプログラムでは、その時間の全てが jacobi ルーチン207行目のループ内メモリロード・ストアで消費されています。いずれにしても、まず、このプログラムでは、jacobi と言うサブルーチンを最初に何らかの形で最適化する必要があると言う方針が立ちます。その後は、initializeルーチン、error_check ルーチンと続きます。
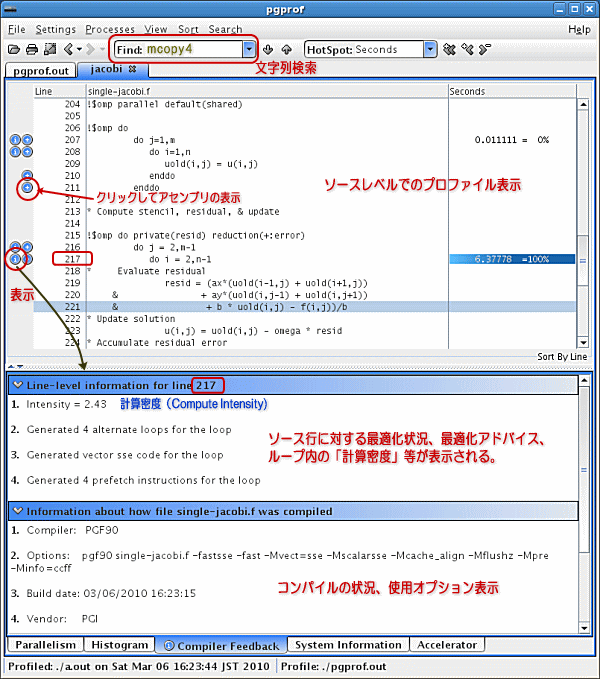
上記の画面の左袖に、"i" マークと"+"マークがあります。"i" マークが付いた行は、この行に関して Compiler Feedback 情報(CCFF)があると言う意味となります。ここをクリックすると、下部の行レベル情報のウインドウにそれらの情報が表示されます。また、"+"マークをクリックすると、アセンブリのリストが表示されます。CCFF に関して若干説明すると、コンパイラがコンパイル時に得た情報をフィードバックしたものと考えて下さい。どんな情報かと言うと、次のようなものです。
コンパイラ・フィードバック(CCFF)の情報
- ループの実行回数やルーチンの呼び出し回数(プロファイル・フィードバックによる最適化オプション(-Mpfi/-Mpfo)による実行が必要)を表示します。
- ループの Compute-Intensity(計算密度)の計測値の表示。計算密度とは、ループ内処理における「浮動小数点演算数」と「メモリロード・ストアの回数」の比率であり、これが高い値であれば、演算量と比較して相対的にメモリアクセスの負荷が小さいと言うことになります。この指標は、「並列化の指針」において非常に重要な指標で、特に GPU 並列コードにする際のループ特性を評価する際に重要です。計算密度が高いほど、相対的にメモリ負荷が小さいと言うことになりますので、並列性能効果が出やすいと言うことになります。上記の画面の場合、217のループの Compute-Intensity(計算密度)は、2.43 であり、指標のバランス的には良い部類に入るでしょう。この「計算密度」指標については、後で、もう少し説明します。
- 並列化に関する情報。例えば、ループを並列化するためのヒントや並列化できない理由等を出力します。
- プロシジャー間最適化オプションである -Mipa=*** のオプションを付加してコンパイルした場合は、コンパイラの手続き間分析の結果として、例えば、参照される定数値の情報等も出力します。
- コンパイラが最適化した部分の情報メッセージを行単位で表示する。
- 使用したオプションの詳細情報。
プロファイリングの目的は、ホットスポットを探し出し、こうした情報をもとにプログラムの計算特性を「マクロ的」に押さえることです。この程度で、プロファイリングの作業は留めておいて良いでしょう。一般のユーザが、これよりもさらに詳細な情報を得たとしても、実は、その後の最適化作業において手の打ちようがありません。
OpenMP 並列、自動並列等のマルチスレッド実行の場合のプロファイリング
上記、single-jacobi.f は、OpenMP 用のディレクティブが実装されたプログラムです。これをマルチスレッド並列用にコンパイルするには、-mp オプションを指定します。同じように pgprof で分析します。
$ pgf90 -fast -mp -Minfo=ccff -o jacobi single-jacobi.f $ pgcollect jacobi $ pgprof -exe jacobi
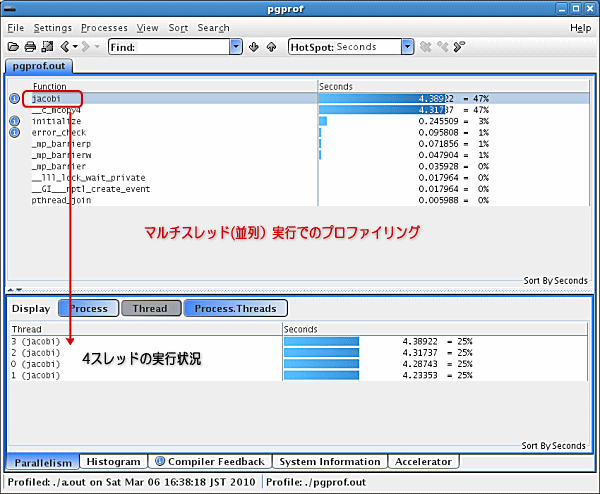
上記のとおり、4 スレッドによるマルチスレッド実行のプロファイルの状況、消費時間の配分等を見ることができます。また、「ルーチン名」をダブルクリックすると、そのルーチンのソースが現れて、ソース行レベルでのプロファイル情報を見ることができます。
プロファイル・フィードバックによる最適化オプション(-Mpfi/-Mpfo)
一般に、プロファイル・フィードバックによる最適化手法とは、1回目に -Mpfi オプションを付けて実行モジュールを作成し、一度実行します。その過程で、プロファイル情報ファイルが生成され、その後、この情報をもとに2回目のコンパイル(-Mpfoオプションを付ける)を行って、プロファイルに基づく最適化が施された実行モジュールを作成することを言います。ここでは、その最適化結果の性能に関しては触れませんが、こうしたことを行うと、CCFFのコンパイラ・フィードバック情報の中に、より詳しいヒントや計算特性情報を取り込めます。以下のリストの中の -Mipa=fast は、プロシジャー間最適化を行うオプションです。
1回目のコンパイル with -Mpfi $ pgf90 -fast -Minfo=ccff -o jacobi single-jacobi.f -Mipa=fast -Mpfi 性能取得のための実行 $ jacobi Input n,m - grid real*4 in x,y direction N= 5120 M= 10000 Input alpha - Helmholts constant Input relax - Successive over-relaxation parameter Input tol - error tolerance for iterative solver Input mits - Maximum iterations for solver Time measurement accuracy : .10000E-05 Total Number of Iterations 101 Residual 6.7434955E-12 Solution Error : 7.1508897E-05 Elpased Time (Initialize + Jacobi solver + Check) : 41.345 2回目のコンパイル with -Mpfo $ pgf90 -fast -Minfo=ccff -o jacobi single-jacobi.f -Mipa=fast -Mpfo IPA: Recompiling single-jacobi.o: stale object file pgcollect で正式な性能情報取得 $ pgcollect jacobi Input n,m - grid real*4 in x,y direction N= 5120 M= 10000 Input alpha - Helmholts constant Input relax - Successive over-relaxation parameter Input tol - error tolerance for iterative solver Input mits - Maximum iterations for solver Time measurement accuracy : .10000E-05 Total Number of Iterations 101 Residual 1.1052383E-11 Solution Error : 7.1508897E-05 Elpased Time (Initialize + Jacobi solver + Check) : 12.226 FORTRAN STOP target process has terminated, writing profile data pgprof で性能を分析 [kato@photon29 ORG]$ pgprof -exe jacobi
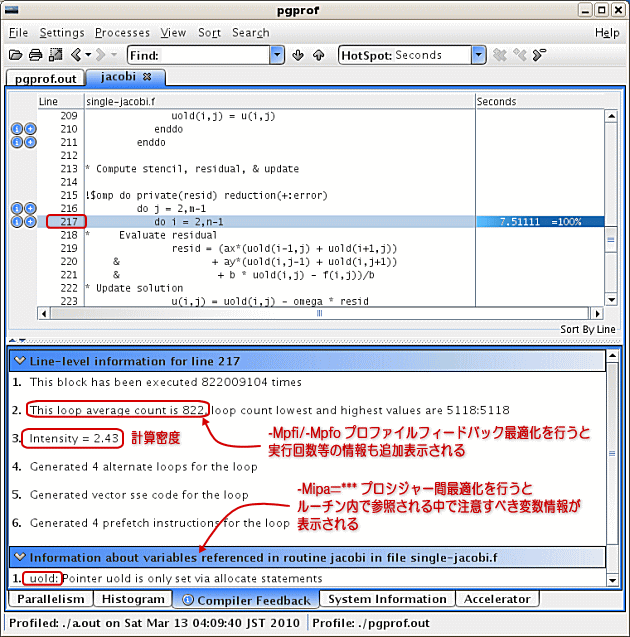
ループの Compute-Intensity(計算密度)
ループ内の演算の Compute-Intensity(計算密度)は、上述のとおり、プログラム(ループ)性能が「メモリ帯域」で律速となる特性を有するのかどうかを決める要素となります。PGIコンパイラは、コンパイル時にこの指標を計算し、最適化の情報として使っています。特に、GPUへ演算部分をオフロードする「PGIアクセラレータ機能」では、GPUデバイス・メモリアクセスの最適化を行うことが重要ですので、こうした指標が活かされています。ユーザもこの情報を明示的に取得することができます。その方法は、以下の二つの方法があります。
- -Minfo=ccff オプションで、コンパイラ・フィードバック情報として、pgprof ツールで出力させる。(上述した pgprof の画面で見えるような形)
- -Minfo=intensity オプションを付けて、コンパイル時のメッセージとして出力させる。
ここでは、2. の方法を説明します。コンパイル時に指標値を決めることができるもに関しては、以下のような -Minfo=intensity でコンパイルするとコンパイル・メッセージの中で表示されます。
$ pgf90 -fast -Minfo=intensity -o jacobi single-jacobi.f
initialize:
138, Intensity = (m*((n*14)+3))/((n*m)+(n*m))
139, Intensity = 7.00
jacobi:
199, Intensity = (maxit*(((m-2)*((n-2)*17))+11))/((((m-2)*(n-2))+(((m-2)*(n-2))+
(((m-2)*(n-2))+(((m-2)*(n-2))+(((m-2)*(n-2))+(((m-2)*(n-2))+((m-2)*(n-2))))))))+
((n*m)+(n*m)))
207, Intensity = 0.0
208, Intensity = 0.0
216, Intensity = ((m-2)*((n-2)*17))/(((m-2)*(n-2))+(((m-2)*(n-2))+(((m-2)*(n-2))+
(((m-2)*(n-2))+(((m-2)*(n-2))+(((m-2)*(n-2))+((m-2)*(n-2))))))))
217, Intensity = 2.43
error_check:
264, Intensity = (m*((n*11)+3))/(n*m)
265, Intensity = 11.00
コンパイル・メッセージには、プログラムソースの行番号が表示されます。コンパイル時のソースコードのリスティング・ファイルを必要な場合は、-Mlist オプションを付加すると ****.lst と言うファイル名で生成されます。リストは以下のような形式です。
( 206) !$omp do ( 207) do j=1,m ( 208) do i=1,n ( 209) uold(i,j) = u(i,j) ( 210) enddo ( 211) enddo ( 212) ( 213) * Compute stencil, residual, & update ( 214) ( 215) !$omp do private(resid) reduction(+:error) ( 216) do j = 2,m-1 ( 217) do i = 2,n-1 ( 218) * Evaluate residual ( 219) resid = (ax*(uold(i-1,j) + uold(i+1,j)) ( 220) & + ay*(uold(i,j-1) + uold(i,j+1)) ( 221) & + b * uold(i,j) - f(i,j))/b ( 222) * Update solution ( 223) u(i,j) = uold(i,j) - omega * resid ( 224) * Accumulate residual error ( 225) error = error + resid*resid ( 226) end do ( 227) enddo
上の例のように、実行時に、計算を行う「系の大きさ」が決まるようなプログラムは、コンパイル時に計算サイズが不定のため以下のような変数式で示されます。実際のこの値を見るためには、一度、計算した結果を反映させる必要があります。このために、上述した「プロファイル・フィードバックによる最適化」オプションを指定して、一度、実行したプロファイル結果を利用します。以下のような形で行います。2回目のコンパイル・メッセージの中に、対象となる全ての指標値が表示されます。
1回目のコンパイル with -Mpfi $ pgf90 -fast -Minfo=intensity -o jacobi single-jacobi.f -Mpfi initialize: 139, Intensity = 7.00 jacobi: 208, Intensity = 0.0 217, Intensity = 2.43 error_check: 265, Intensity = 11.00 実行 [kato@photon29 ORG]$ jacobi Input n,m - grid real*4 in x,y direction N= 5120 M= 10000 Input alpha - Helmholts constant Input relax - Successive over-relaxation parameter Input tol - error tolerance for iterative solver Input mits - Maximum iterations for solver Time measurement accuracy : .10000E-05 Total Number of Iterations 101 Residual 6.7434955E-12 Solution Error : 7.1508897E-05 Elpased Time (Initialize + Jacobi solver + Check) : 41.335 2回目のコンパイル with -Mpfo [kato@photon29 ORG]$ pgf90 -fast -Minfo=intensity -o jacobi single-jacobi.f -Mpfo initialize: 138, Intensity = 7.00 139, Intensity = 7.00 jacobi: 199, Intensity = 16.56 207, Intensity = 0.0 208, Intensity = 0.0 216, Intensity = 2.43 217, Intensity = 2.43 error_check: 264, Intensity = 11.00 265, Intensity = 11.00
さて、次回は、「PGIの自動並列化」の性能について説明し、次々回以降は、PGIアクセラレータのチュートリアル(NVIDIA GPU の構造と CUDA スレッディングモデル)に入っていきます。