【アプリプロファイリングをしてみよう!】Nsight Computeの導入・使用方法
はじめに
プロメテックの南です。
今回は、NVIDIA社が提供するプロファイラツールであるNsight Computeを取り上げます。
本コラムは、Nsight Computeの、
- 導入・環境設定を知る(とっかかりを知る)
- 基本的な利用方法を知る(雰囲気を知る)
ことを目的とします。
読者は以下のような方を想定しています。
- プロファイラには慣れているが、Nsight Computeは利用したことがない
- 利用中のGPUアプリを分析したい/高速化したいが、どうすればよいか分からない
プロファイラ・Nsight Computeとは
プロファイラとは、開発ツールの一つです。アプリケーションを監視して性能問題を見つけることができます。
これはアプリの分析や高速化において非常に強力です。
Nsight Compute はNVIDIA社が提供するCUDAカーネルのプロファイラです。
対話的なプロファイリング機能を提供し、GPUアプリの効率的な性能最適化作業に役立ちます。
検証環境
今回は、Linux OSのGPU搭載ノード(以下、GPUノード)にWindows端末(以下、クライアント)から接続する形を想定します。
なお、紹介する導入・利用手順は、GPUノードとクライアントが一体となった場合(例えば、GPU搭載のWindows機)でも共通部分が多く、参考になると思います。
| ハードウェア | OS | Nsight Compute | |
| GPUノード | NVIDIA Quadro GV100 | Ubuntu 20.04 | 2023.1.1 |
| クライアント | 11th Gen Intel(R) Core(TM) i7 | Windows 11 Pro | 2023.1.1 |
Nsight Computeの導入
インストール
まず、インストールについて紹介します。
GPUノード
Nsight Computeは、CUDA Toolkitに同梱されます。
既にGPUを利用している場合は、インストールされていると思いますので、割愛いたします。
クライアント
こちらを参照ください。
以下のGIFアニメのようにしてインストーラをダウンロードできます。

ダウンロードが終了したら起動してインストールしてください。ガイドに従えば問題ないかと思います。
設定
接続設定・プログラムの設定
まず、クライアントからGPUノード上のプログラムを実行する方法について説明します。
以下のGIFアニメのようにして、以下の設定を行ってください。該当の公式マニュアルページはこちらです。
- GPUノードの接続設定
- 実行するプログラムの指定

レジスタへのアクセス許可
次に、一般ユーザでもプログラムのパフォーマンスを測定できるようにするため、レジスタへのアクセス許可を与えます。
該当の公式マニュアルページはこちらです。
今回はGPUノードのすべてのユーザでアクセスを許可します。
$ sudo echo "options nvidia \"NVreg_RestrictProfilingToAdminUsers=0\"" > /etc/modprobe.d/nsight_user.conf
ファイルを作成後、GPUノードを再起動してください。
Nsight Computeの実行
今回は例としてナイーブな行列積を取り上げます。コードはここにアップロードしています。まずはmm.cを動作させてみます。
プロファイラの取得
まず、GPUカーネルのプロファイラを取得してみましょう。
以下のような手順で行います。流れは下記のGIFアニメをご覧ください。
- Runを押下 → cuinitで止まることを確認
- Next GPU Kernelを押下 → matmal_GPUで止まることを確認
- Profile を押下 → カーネルのプロファイル結果が表示されることを確認
プロファイリング内容の設定
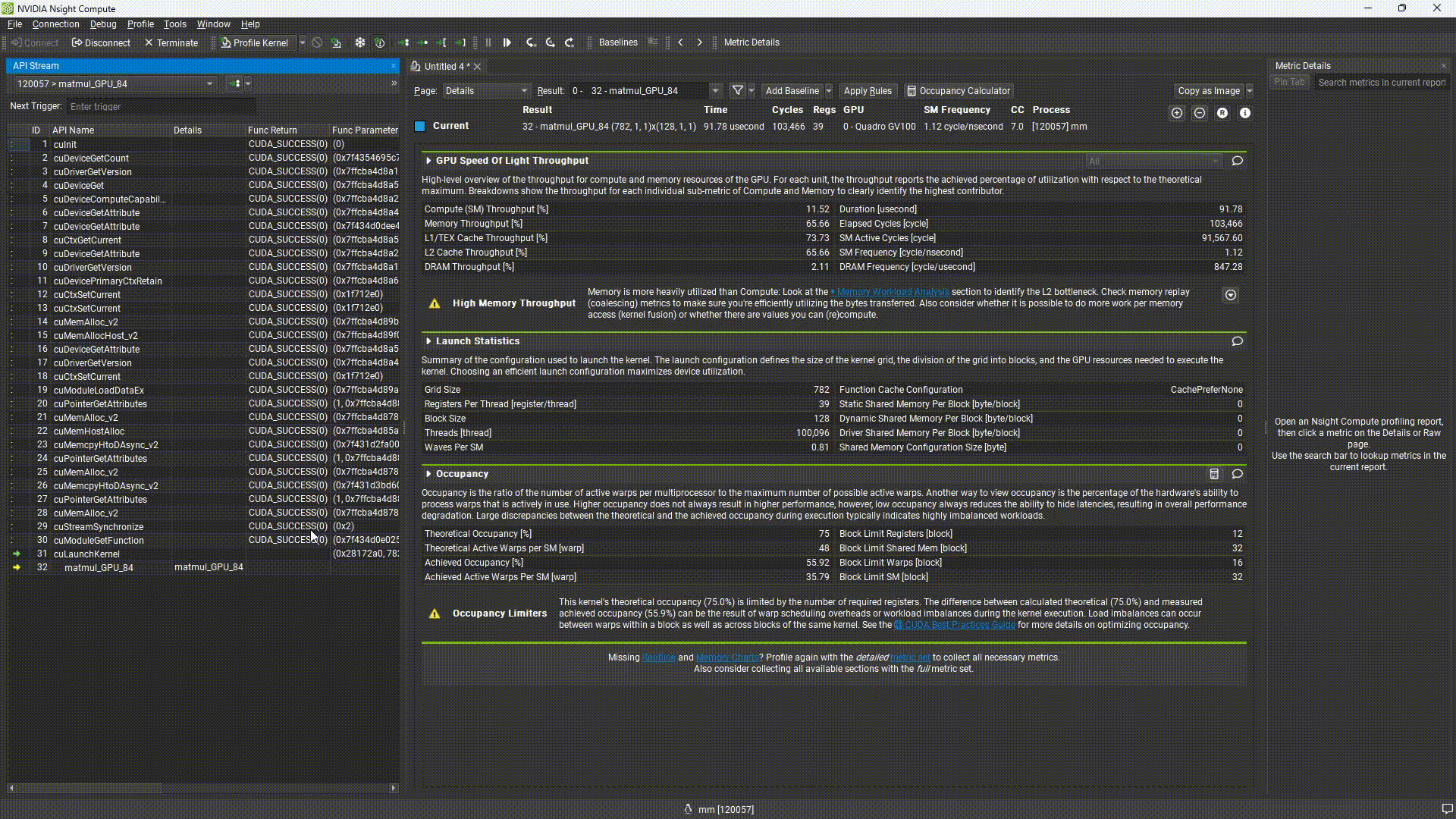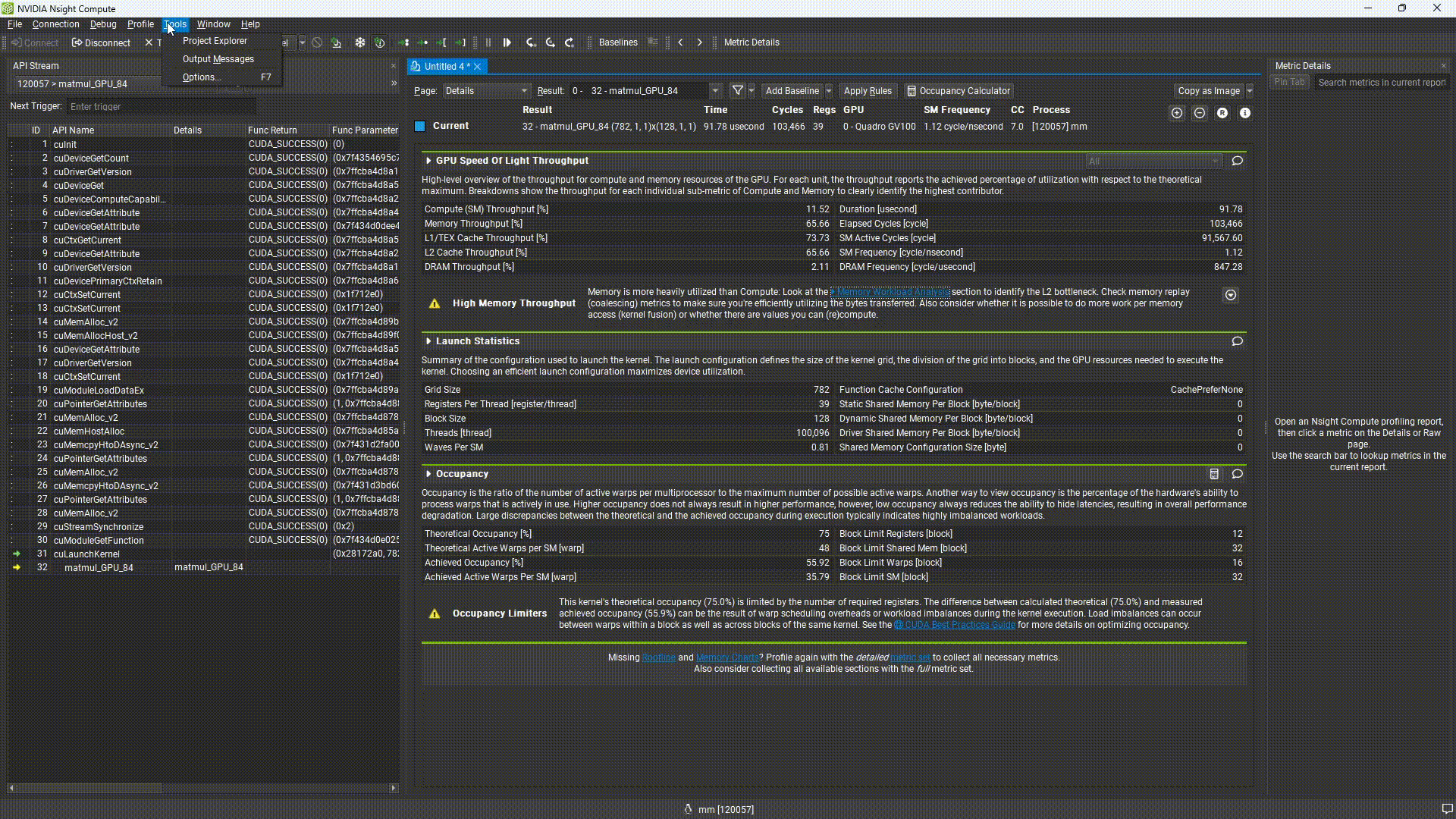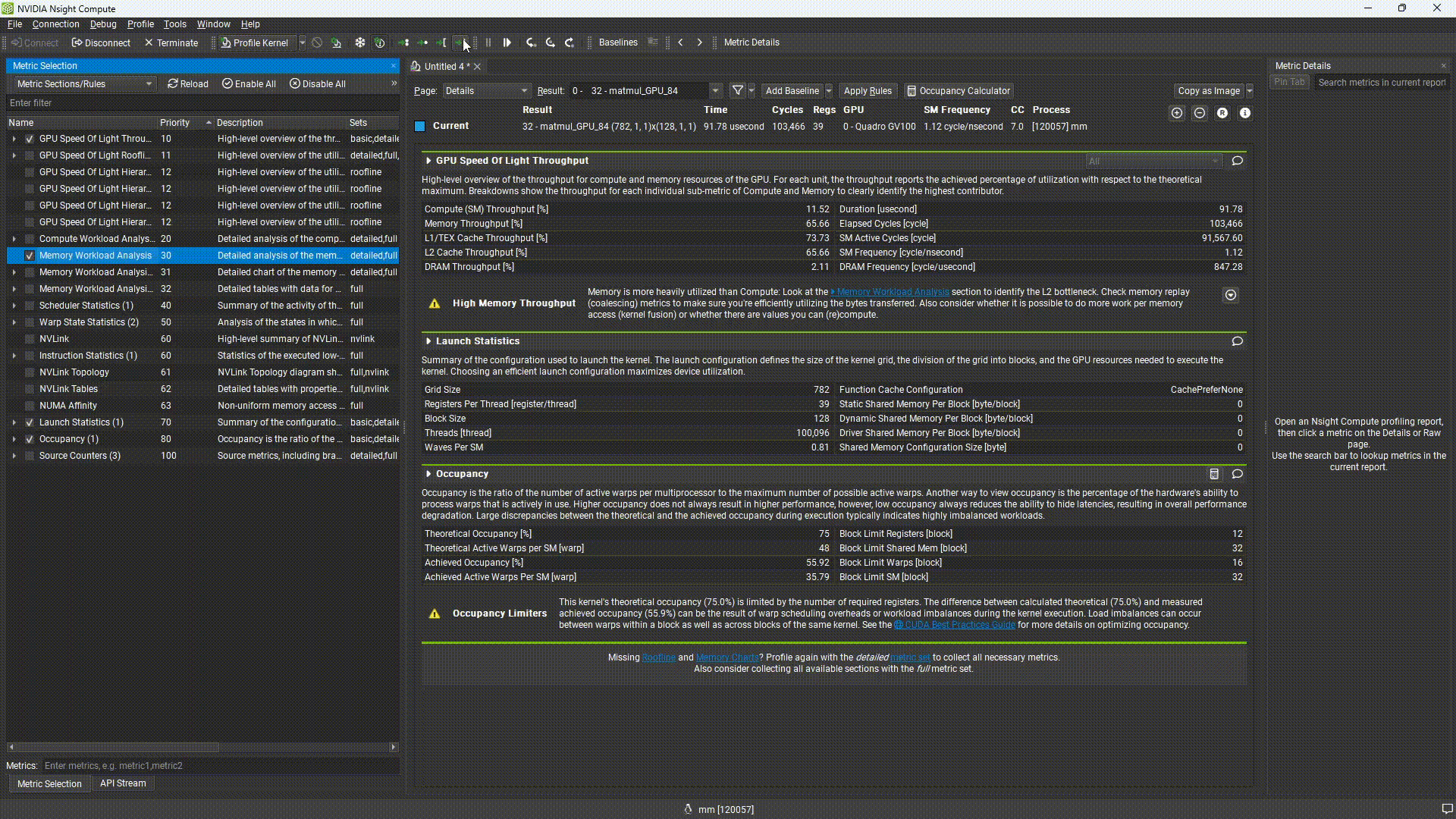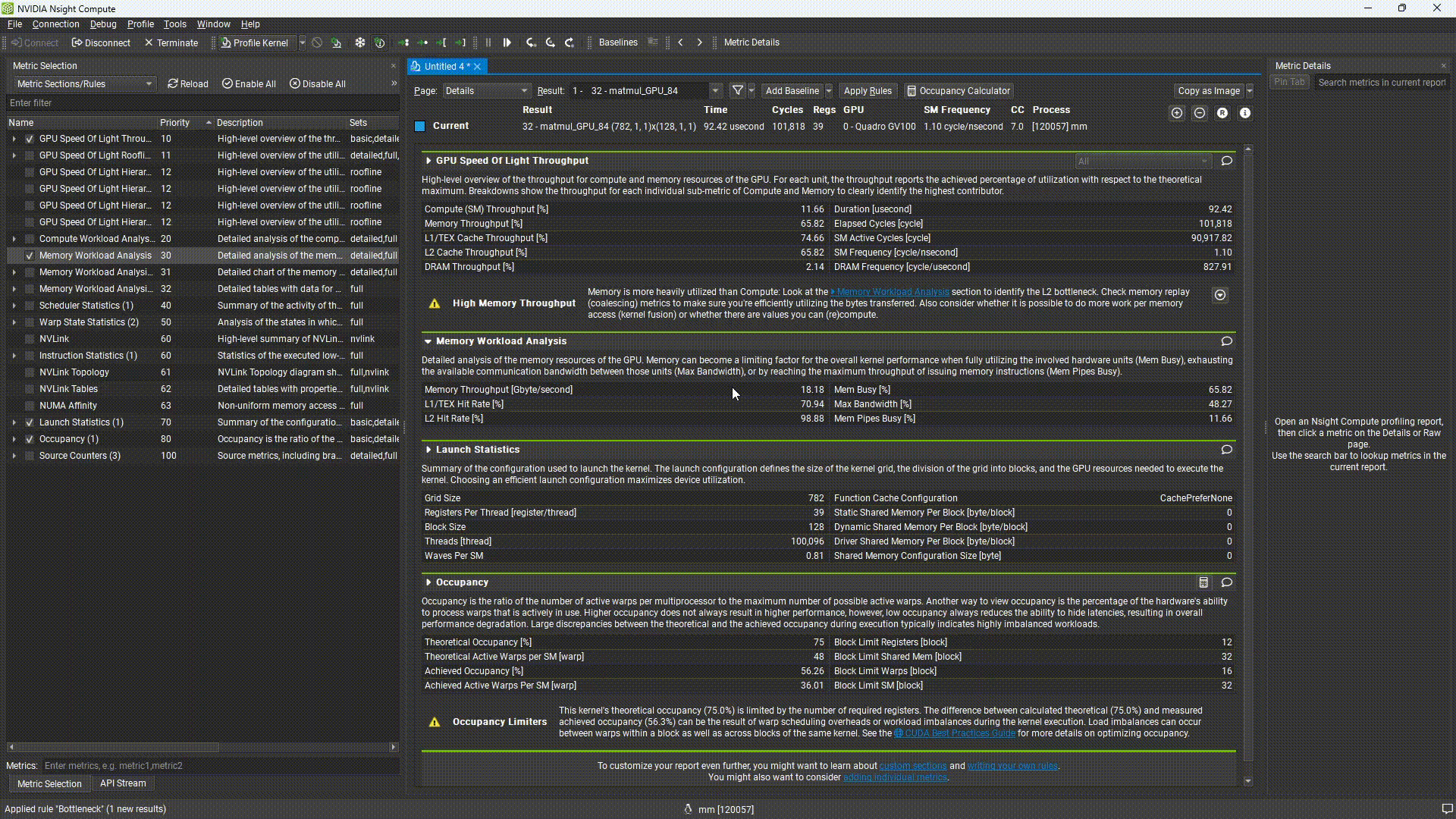
結果のサマリ部分を確認すると、”Look at the Memory Workload Analysis”とあります。しかし、これをクリックしても、情報が見つかりません。なぜかというと、取得する設定にしていなかったためです。
Nsight Computeでは一般に、取得したい情報を事前に設定する必要があります。この情報の単位をSectionと呼びます。
測定するSectionの設定は以下のような手順で行います。流れは下記のGIF画像をご覧ください。
- Profile → Metcric Selectionを選択
- Memory Workload Analysisにチェック
- Profile を押下 → プロファイル結果にMemory Workload Analysisが追加されることを確認
ソースコードの変更とプロファイラの確認
先ほどの結果を見ると、メモリアクセスが大きいとありました。そこで、性能改善のため、メモリアクセスパターンの改善を試みるアプローチが良さそうです。
今回は、行列積の高速化で広く知られるループ交換というメモリアクセス改善のテクニックを適用してみます。変更後のソースコードはbitbucketのmm_mod.cです。ここでは、変更したソースコードの解説は割愛いたします。
Nsight Compute上で再実行し、変更後のプロファイル結果を確認してみましょう。多くのパラメータが改善されていることが確認できるでしょう。
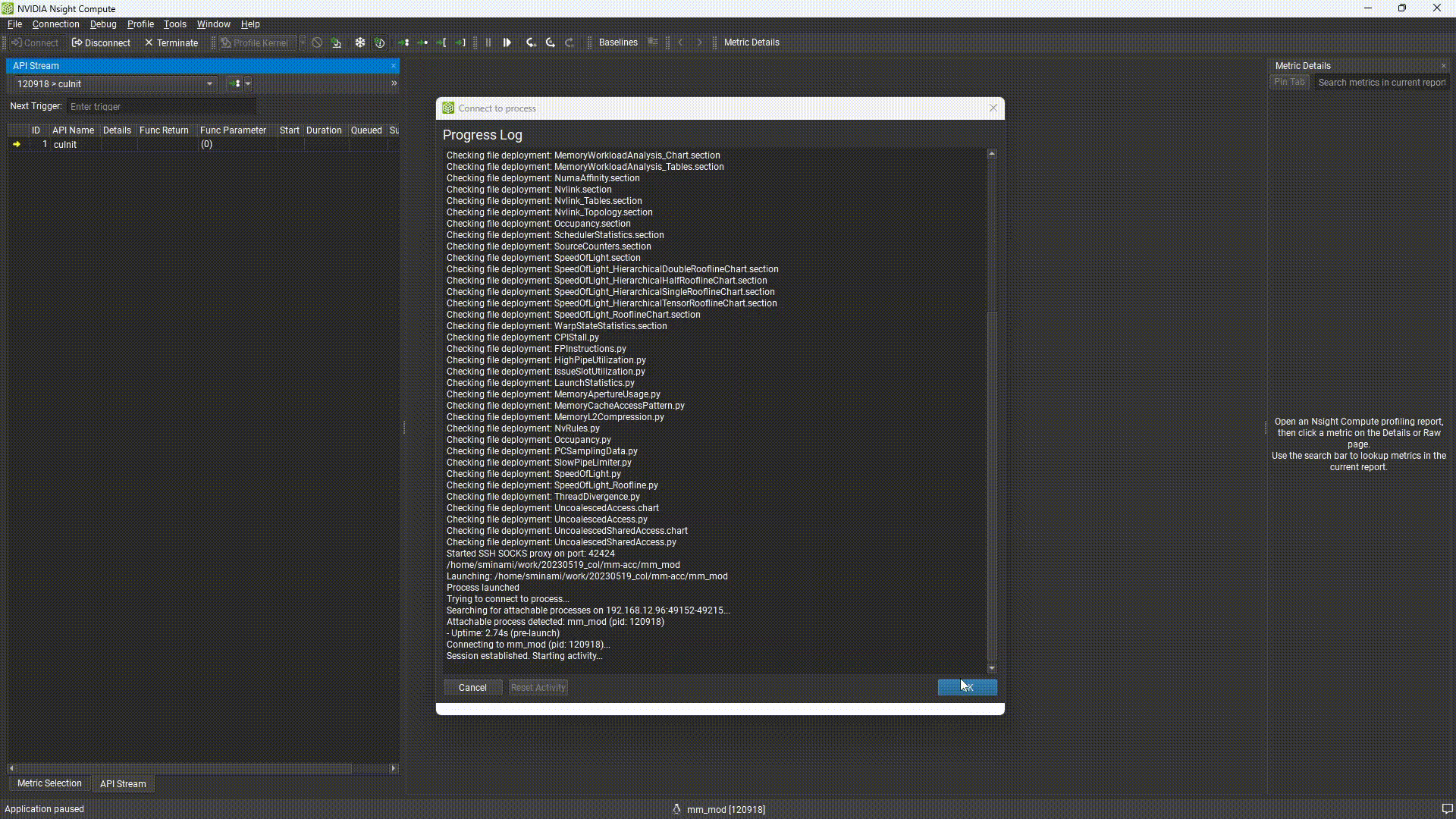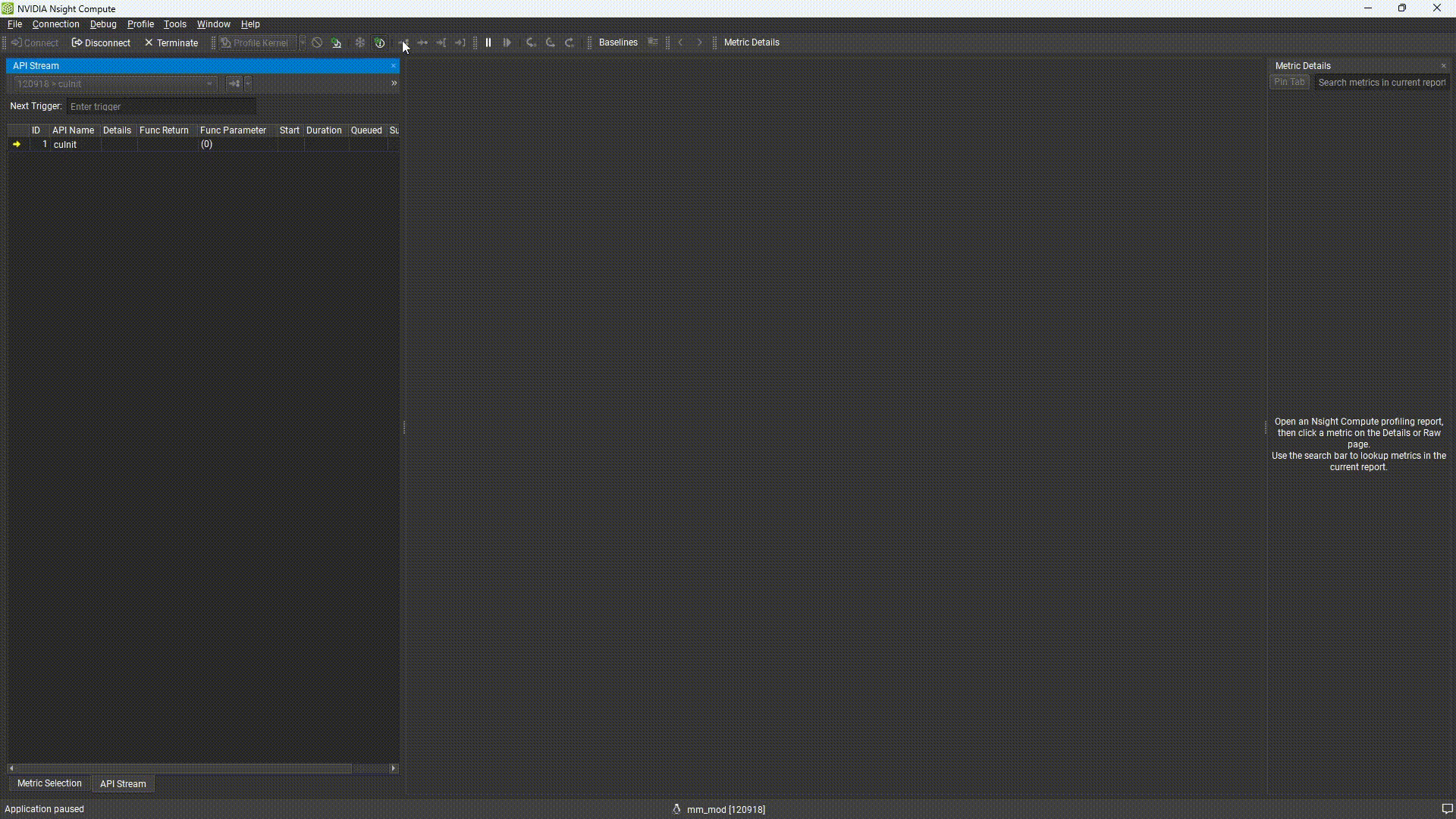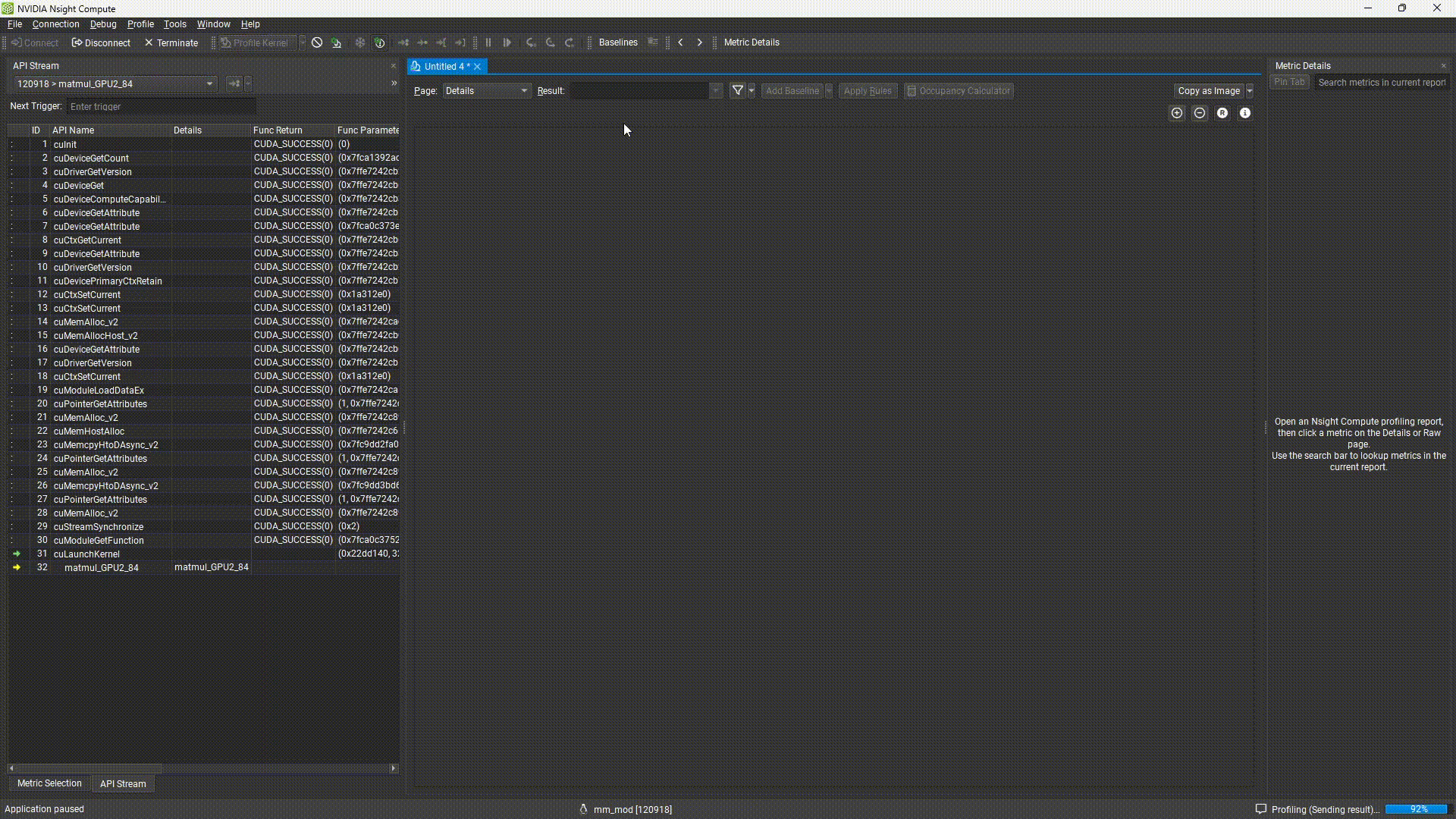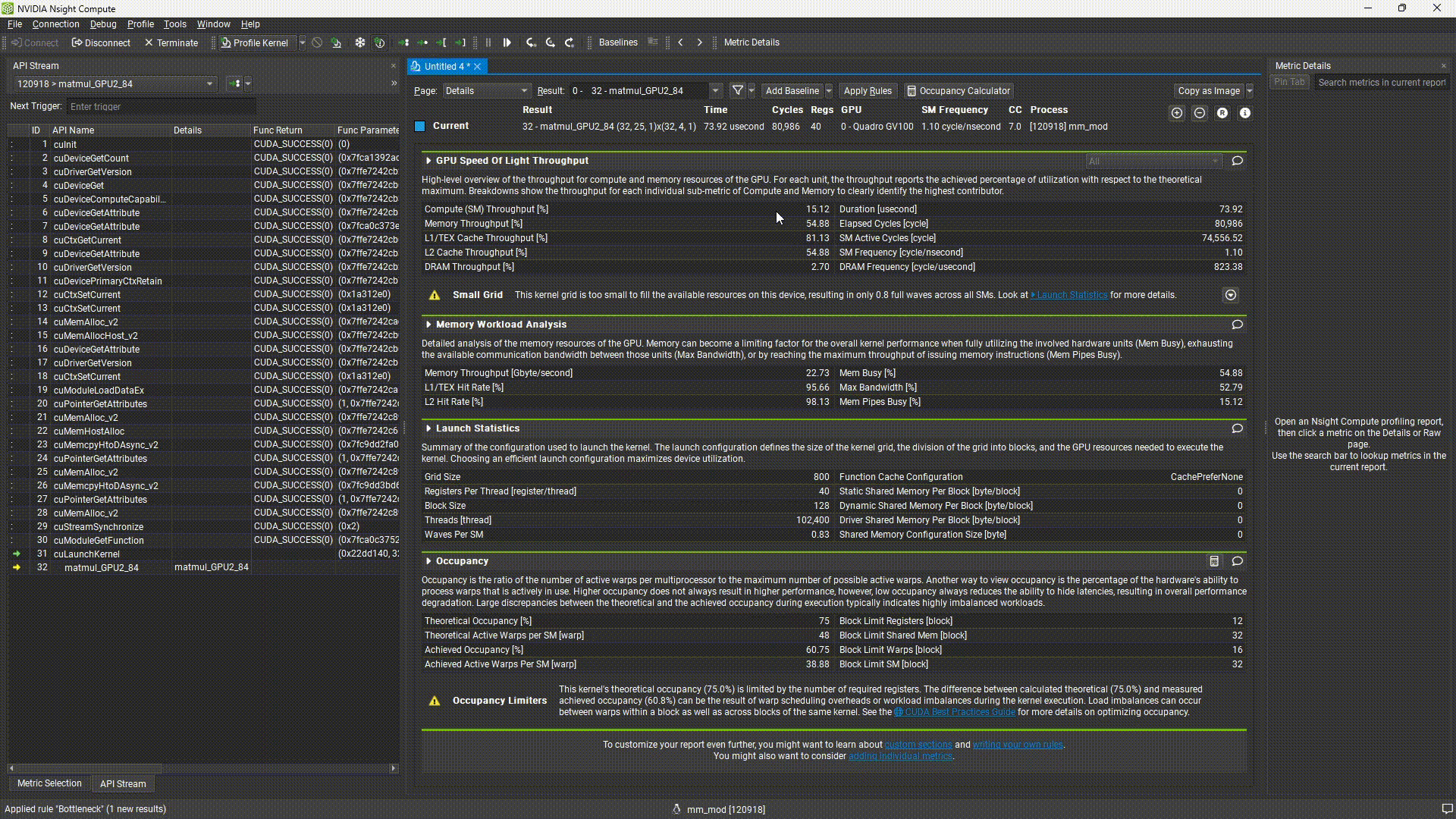
参考までに、検証環境での値の変化を載せます。下線で強調した、L1 cacheの有効利用が性能に寄与したようです。
| Duration [usecond] | Memory Throughput [Gbyte/second] | L1/TEX Hit Rate [%] | L2 Hit Rate [%] | |
| mm (修正前) | 93.31 | 18.01 | 71.08 | 98.66 |
| mm_mod (修正後) | 73.92 | 22.73 | 95.66 | 98.13 |
またGIFアニメの最後を確認すると、サマリにある性能拘束要因が”Small Grid”に変わっています。
一つの変更を加えて性能が改善しても、また別の性能拘束要因が見えてくることはよくあることです。このようにしてインクリメンタルな性能改善を行っていきます。
今回は行列積という既に数多くの高速化手法があるアプリでしたが、一般のアプリの場合、プロファイラ結果・メッセージからどのような変更を加えるべきかはすぐには分かりません。そのような場合でも上記のような手順で、「あたりをつけてソースコードを変更しプロファイル結果で効果を確認する」という試行錯誤を繰り返して高速化を行うことをお勧めします。
参考
基本的な使用法が理解出来たら、あとは公式マニュアルを参照して、用途に合った機能を探してみましょう。
また、本記事の執筆では公式マニュアル中の特に以下を参考にしました。
まとめ
今回は、NVIDIA社が提供するプロファイラツールであるNsight Computeの導入・基本的な利用手順を紹介いたしました。非常に使いやすいツールですので、お手元のGPUアプリの性能にお困りの際は一度使ってみてはどうでしょうか。
