CUDA Streamを用いた並行処理
はじめに
以前弊グループが主催したGPUプログラミング勉強会にて、OpenACC asyncを用いた並行処理についての質問をいくつかいただいていたとのことで、今回はacc asyncを書いた先、実装に使われるCUDA Streamの動きについて調べます。
OpenACCは通常OpenMPと同様、directiveの末尾で暗黙の同期が発生し、計算やメモリコピー等の処理が完了するまでacc directiveから抜けません。
しかしプログラムによっては単純ループの並列化以外に、例えばメモリコピーと計算をオーバーラップしたい、依存関係がない複数の処理を同時に実行させたい、のような複数の処理を非同期的に実行したいというケースがあり、OpenACC asyncはそのような処理を実現するための機能です。
asyncはCUDA GPU上ではCUDA Stream機能を単純化したもので、つまり実際に非同期処理されるかはその仕様に強く依存しています。
ここでは1台のGPU上で、CUDA Streamは実際に並行処理をしてくれるのかを調査し、CUDA StreamとOpenACC asyncはどういう用途で利用できるかを考えます。
CUDA Streamについて
CUDA Streamは、簡単にいうとFIFOのタスクキューと考えればわかりやすいかと思います。
デフォルトではキューが1つ(default streamと呼ぶことがあります)で、通常はdefault streamにCUDAカーネルを登録しGPUが順次実行しますが、CUDA Streamを別途作成しdefault streamと同時並行的に処理させることが可能です。
この機能を単純な整数値で管理できるようにしたのがOpenACCのasyncです。
streamは以下のように、CUDAカーネルの実行パラメータとして渡したり、cuBLASなどのライブラリではhandle objectに対し設定して使用します。
cudaStream_t stream;
cudaStreamCreate(&stream);
// primitive CUDA kernel
cuda_kernel<<<x, y, smem, stream>>>(...);
// cuBLAS
cublasSetStream(cublas_handle, stream);
cudaStreamDestroy(stream);
複数のstreamが実行されている場合、GPUの計算リソースが余っている状況であればGPUのスケジューラが自動判断し同時実行を行います。
計算リソースは、CUDAスレッドあたりに消費される32 bit registerの数や、Shared memoryの使用量、grid/block/threadの総数(つまりCUDA Coreをどれだけ使うか)、などが挙げられます。
(注意)一般的に並列処理や並行処理についての仕様は「可能であれば」や「することがある」という文言がつくため、動作確認や性能比較が必要です。
cuBLAS + stream
実装詳細は省きますが、まずcuBLASの行列積を4つのstreamに対し1つずつ、合計4カーネルを同時に投入したときの動作を検証します。
計算リソースが余っていればということなので、今回は1024×1024の比較的小さいサイズの行列積を実行してみます。
メモリが衝突する/そのようにスケジューラが誤認するのを回避するため、各stream用に別々にデバイスメモリを確保しています。
各stream単位で見ればメモリは完全に独立しているとみなされるはずで、あとはCUDAコア等の空き状況に応じて同時実行されると期待できます。
#include <thrust/host_vector.h>
#include <thrust/device_vector.h>
#include <cublas_v2.h>
#include <cuda_runtime_api.h>
using namespace thrust;
void dgemm_async(cublasHandle_t handle, int n, device_vector<double> & A, device_vector<double> & B, device_vector<double> & C) {
double alpha = 1.0;
double beta = 0.0;
cublasDgemm(
handle,
CUBLAS_OP_N,
CUBLAS_OP_N,
n, n, n,
&alpha,
raw_pointer_cast(A.data()), n,
raw_pointer_cast(B.data()), n,
&beta,
raw_pointer_cast(C.data()), n
);
}
int main() {
constexpr int n = 1024;
constexpr int n_handles = 4;
cudaStream_t stream[n_handles];
cublasHandle_t handle[n_handles];
for (int i = 0 ; i < n_handles ; ++i) {
cudaStreamCreate(&stream[i]);
cublasCreate(&handle[i]);
cublasSetStream(handle[i], stream[i]);
}
host_vector<double> hA(n * n), hB(n * n), hC(n * n);
for (int i = 0 ; i < n; ++i)
for (int j = 0 ; j < n ; ++j) {
hA[i * n + j] = double(i * n + j + 1) / n;
hB[i * n + j] = hA[i * n + j] * -1;
}
device_vector<double> A[n_handles], B[n_handles], C[n_handles];
for (int i = 0 ; i < n_handles ; ++i) {
A[i] = hA;
B[i] = hB;
C[i] = hC;
}
for (int t = 0 ; t < 10 ; ++t)
for (int i = 0 ; i < n_handles ; ++i)
dgemm_async(handle[i], n, A[i], B[i], C[i]);
for (int i = 0 ; i < n_handles ; ++i)
cudaStreamSynchronize(stream[i]);
if (n <= 8) {
hC = C[n_handles - 1];
for (int i = 0 ; i < n; ++i) {
for (int j = 0 ; j < n ; ++j)
std::cout << hC[i * n + j] << " ";
std::cout << std::endl;
}
}
for (int i = 0 ; i < n_handles ; ++i) {
cublasDestroy(handle[i]);
cudaStreamDestroy(stream[i]);
}
}
Nsight Systemsでカーネルの動作を確認
さてstreamが本当に同時実行されるのかを検証するには、ですがNsight Systemsによるプロファイルが最も簡単かつわかりやすいでしょう。
Nsight SystemsはNVIDIAが提供しているプログラムのプロファイルツール兼可視化ソフトウェアで、可視化はLinux Desktop distributions, Windows, MacOSのどれでも利用可能です。
Nsight SystemsのCLIコマンドを使ってまず実行結果をプロファイルし、その後に手元のPCで結果を可視化する、のような使い方が一般的だと思われます。
同種ツールにNsight Computeがありますが、Nsight Computeは各カーネルの詳細な性能プロファイリングを、Nsight SystemsはCUDA以外も含めたプログラム全体でプロセスやスレッド、GPUがどのように動いたかをプロファイルするのに使います。
まず、CUDA向けにコンパイルしたプログラムをNsight Systemsを挟んでプロファイリングします。
NVIDIA HPC SDKやCUDA SDKに標準で同梱されていますので、nvccやnvc++などが実行できる状態ならnsysおよび可視化用のnsys-uiのどちらも見えているかと思います。
$ nvc++ -cuda -cudalib=cublas cublas_dgemm.cc
$ nsys profile -o report ./a.out
上記を実行するとreport.nsys-repというプロファイリング結果が入ったファイルが出力されるので、Nsight Systemsの可視化ソフト(Linuxではnsys-ui)に渡してプロファイル結果を可視化します。
以下は今回のプログラムのプロファイル結果から、行列積部分のタイムラインにフォーカスしたものです。
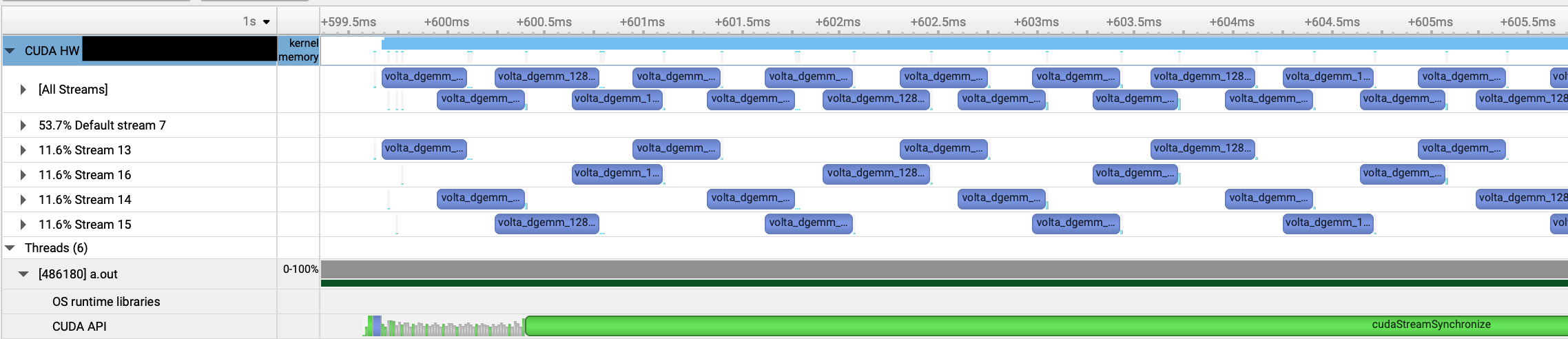
stream 13-16がcudaStreamCreateで作成したstreamで、7がdefault stream、[All Streams]となっているのがこれらのタイムラインを重ねたものです。
少なくとも2 kernelは同時実行されているようですが、よくみると完全に重なっているわけではなく、カーネルの始まりと終わりの部分だけ同時実行しているように見えます。
おそらく前に実行されているカーネルが少しずつ処理が完了してCUDA Core等が待機状態になるので、その余った計算リソースが順次、次のカーネルの実行に割り当てられる、ような動きではないでしょうか。
しかし行列サイズを小さくしても、2個までしか同時実行されませんでした。
計算とメモリコピーをオーバーラップする場合
先程のプログラムを修正し、デバイスからホストメモリへのコピーをstreamに登録し、計算とメモリコピーのオーバーラップが可能か確認してみます。
stream Aの計算とstream Bのメモリコピーは完全にオーバーラップできるはずで、ここでは2 streamとしました。
for (int t = 0 ; t < 10 ; ++t)
for (int i = 0 ; i < n_handles ; ++i) {
dgemm_async(handle[i], n, A[i], B[i], C[i]);
cudaMemcpyAsync(hC[i], raw_pointer_cast(C[i].data()), sizeof(double) * n * n, cudaMemcpyDefault, stream[i]);
}
for (int i = 0 ; i < n_handles ; ++i)
cudaStreamSynchronize(stream[i]);
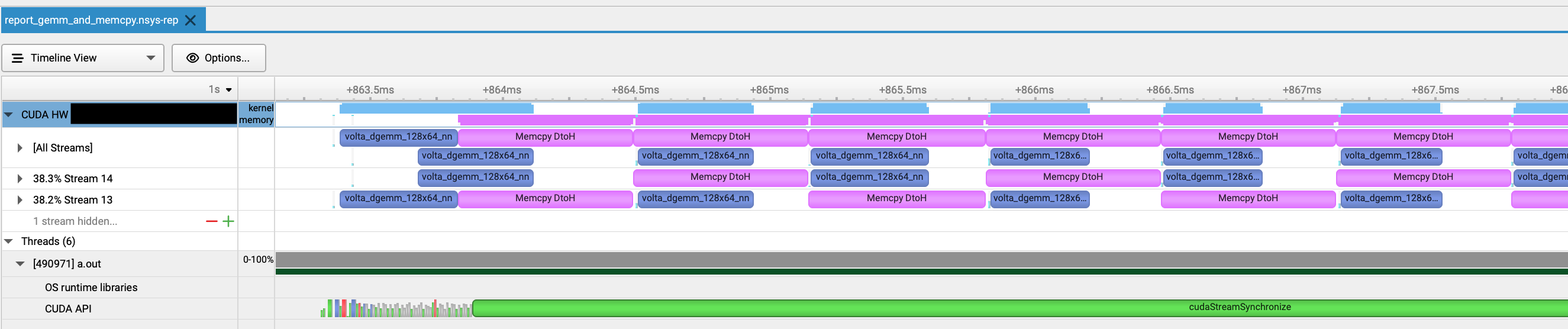
メモリコピーの時間が行列積の計算よりかかっていますが、期待通りstream 13および14の計算とメモリコピーがオーバーラップできています。
より小さな計算の場合
行列積の場合はスレッドあたりの計算リソースの消費が大きいため、リソース最小のカーネルにすれば3以上のstreamを同時実行できるのではないでしょうか。
今回は何もせずclock関数を使ってN cycleただ待機するだけのカーネルを実行し、同時実行可能か調べました。実行したコードは以下です。
#include <cuda_runtime_api.h>
__global__
void nop_kernel(int stop_cycles) {
clock_t start = clock();
while (1) {
clock_t now = clock();
clock_t cycles = now - start;
if (cycles >= stop_cycles)
break;
}
}
int main() {
constexpr int n_handles = 4;
cudaStream_t stream[n_handles];
for (int i = 0 ; i < n_handles ; ++i)
cudaStreamCreate(&stream[i]);
for (int t = 0 ; t < 10 ; ++t)
for (int i = 0 ; i < n_handles ; ++i) {
nop_kernel<<<128, 64, 0, stream[i]>>>(10000000);
}
for (int i = 0 ; i < n_handles ; ++i)
cudaStreamSynchronize(stream[i]);
for (int i = 0 ; i < n_handles ; ++i)
cudaStreamDestroy(stream[i]);
}
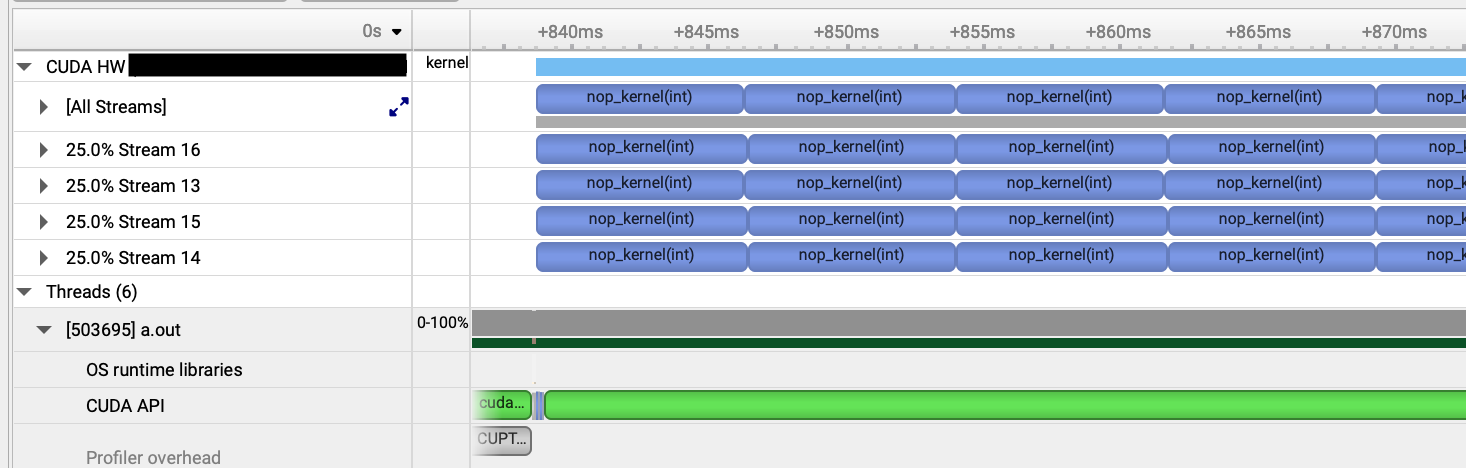
推測通り、計算リソースが少ない場合に4 streamが同時に実行されることが確認できました。
支配的となるような計算リソースの消費が大きいと推測されるカーネルが動いているタイミングでは、他のカーネルを同時並行的に動かすことは難しそうです。
まとめ
ここまでの結果を踏まえると、以下のことが言えそうです。
- CUDA Streamを使うことで計算リソースが少ないカーネルを同時並行的に実行できる(可能性がある)
- 計算とメモリコピーのオーバーラップは、それぞれが要求するリソースが異なるため比較的実現しやすいものと考えられる
- 行列積や格子計算といったプログラムの核となるような計算カーネルの場合、他カーネルの同時並行処理は期待できないが、メモリコピーとのオーバーラップは容易と期待される
- 同時並行処理されているかはNsight Systemsなどのプロファイラにより検証することが非常に重要
最初に戻ってOpenACC asyncですが、おそらく大多数のユーザーが期待している「複数カーネルの同時並行処理」は難しく、バックエンドであるCUDAの知識がかなり要求されそうです。
マージが難しいがホストへのメモリコピーコストを考えるとGPUで実行したほうが速い小さなカーネル群を大量に投入したり、メモリコピーを裏で回すという用途が中心ではないでしょうか。
一方で、1つのプロセスから複数のGPUを同時に利用する場合はasyncを活用できそうです。また次回、その結果を報告できればと思います。
