GPU対応 PGI アクセラレータ™ コンパイラ
高性能コンピューティング(HPC)分野では、汎用アクセラレータとしてグラフィックス・プロセッシング・ユニット(GPGPU)を使用する傾向が高まっています。これまで、Fortranアプリケーションからの GPU の使用は極めて限定的でした。GPUアクセラレータを対象とする開発者は、x86-64 ホストと GPU 間のデータ移動を管理し、ホストから GPU に演算処理をオフロードするため一連の関数呼び出しを行い、詳細なレベルでの C プログラミングが必要でした。一方、PGI Accelerator™ Fortran および C、C++ コンパイラは、全体的なプログラム構造とデータを自動的に分析し、アプリケーションの中で GPU へオフロードしたいループ領域へのユーザの指示(OpenACC ディレクティブ、プラグマ)に基づいて、マルチコア CPU と GPU のコード部分に分割します。さらに、最新 GPU の並列コア、ハードウェア・スレッディング機能、および SIMD ベクトル機能を自動的に使用し、当該ループ処理のマッピングの定義および生成を行い、ホスト側と GPU 側の実行形式モジュールを一つの PGI Unified Binary™ 形式で生成します。 PGIアクセラレータ™ コンパイラは、Linux / Windows / MacOS X のほとんどのプラットフォーム上で使用することができます。もちろん、このコンパイラには従来のインテルCPU、AMD CPU用のコンパイル機能も含んでおります。
PGIアクセラレータ™ コンパイラ製品とは
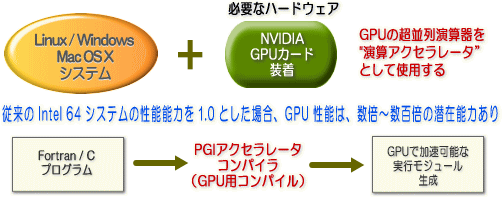
PGIアクセラレータ™ コンパイラは、NVIDIA社の GPU / GPGPU とそのCUDA開発環境を実装したシステム上で、GPU を活用するためのコンパイラを含めたプログラム開発環境を提供します。この PGIアクセラレータ™ コンパイラは、NVIDIA 社の GPU を備えた全てのインテル(R)プロセッサ並びに AMD のプロセッサベースのシステム上で動作し Linux(64bit)、Apple OS X(64bit)、Windows(64bit) の各プラットフォームに対応しております。
PGIアクセラレータ™ コンパイラ製品は、インテル(R)プロセッサ並びに AMD のプロセッサマルチコアに対応した、従来のコンパイラ製品の上位の製品系列に位置づけられ、いわゆる従来のホスト側の Fortran/C/C++ コンパイラ環境がベースとなります。PGIアクセラレータ™ コンパイラ製品は、従来のマルチコア用の並列化コンパイラ機能を含みますので、GPUアクセラレータ処理を行わない環境では、従来通りの x86プロセッサ用のコンパイラとしてお使いいただけます。
PGIアクセラレータ™ コンパイラ製品に含まれる主な機能は、以下の通りです。
- インテル® 並びに AMD のマルチコア・プロセッサ(x86、x64)用の並列・最適化コンパイラ機能
- OpenACC ディレクティブ挿入による x64+GPU 用実行バイナリの自動生成機能(Fortran、C11、C++ )、PGI CUDA Fortran 機能
- CUDA C/C++ プログラムを GPU を有しないマルチコア x64 プロセッサ上で動作させる機能
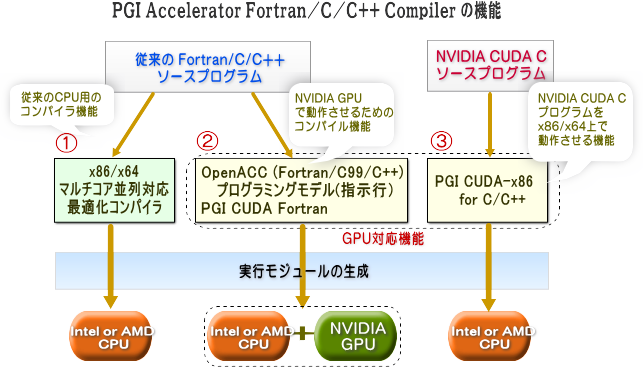
GPU 用の実行バイナリを生成するための二つのプログラミングモデル
PGIアクセラレータ™ コンパイラを使用して、GPU / GPGPU 対応の並列プログラミングを行う方法は、上述したように「二つの方法」が用意されております。具体的なコードを示し、簡単に概略を説明します。
(1) OpenACC ディレクティブを利用する方法
一つは、スレッド並列用の標準規約 OpenMP のようなコンパイラ指示行により、その並列領域を指定してコンパイラに並列コードを生成させる方法です。これは、PGI 社が提唱、公開した規約である「PGI Fortran & C Accelerator Programming Model」によるコンパイラの指示行をプログラムに挿入するだけで、ユーザは高級言語レベルで host + accelerator 用のコードを作成できます。
![]()
2011年11月に、PGI は、NVIDIA社、Cray社、CAPS社と共に、OpenACC API 仕様書を定義し公開しました。OpenACC 標準規格は、最新のオープンな並列プログラミング規格として科学技術系の多数のプログラマを対象とした新しい規格です。これは、OpenMP のようなディレクティブ・ベース(ソース上に指示行を挿入する形態)のプログラミング手法を採用しております。OpenACC 仕様のほとんどは、既に、実装レベルで実績のある PGI の PGI Accelerator programming Model がベースとなっております。OpenACC に準拠したコンパイラのは、PGI 12.6 にて初期リリースを行いました。実装機能のロードマップは、こちらをご覧下さい。
OpenACC プログラミングガイド(日本語)
(ニュース・トピックス)
- (2015/10/29) Performance Portability from GPUs to CPUs with OpenACC
- (2012/12/25) 新しいNVIDIA Tesla K20シリーズのGPUアクセラレータに対応する PGI Acceleratorコンパイラを発表
- (2012/12/25) Intel社のXeon Phiに対応するOpenACCを提供
- (2012/12/06) AMD社とAPU用コンパイラで連携供
(弊社加藤による OpenACC ディレクティブに関する講演資料)
2012年5月
- なぜ、ディレクティブベースのプログラミングが有望なのか? ~ GPU computing への基礎知識 ~
- PGIコンパイラの使用の実際 ~新しいOpenACCによるプログラミング~
- 上記の講演内容は Youtube の NVIDIA Japan チャネルにて公開中
http://www.youtube.com/user/NVIDIAJapan
2012年7月
2013年7月
(PGI Accelerator Compilers with OpenACCスタータ・ガイド)
- OpenACC Getting Started Guide
- (PGI Insiderコラム)The PGI Accelerator Compilers with OpenACC
- OpenACC Features in the PGI Accelerator Fortran Compiler—Part 1
- OpenACC Features in the PGI Accelerator C Compiler—Part 1
- OpenACC Kernels and Parallel Constructs
- PGI C++ with OpenACC
- OpenACC Interoperability Tricks
- Using the OpenACC Routine Directive
- PGI C++ and OpenACC
- OpenACC and CUDA Unified Memory
- OpenACC for Multicore CPUs
- Performance Portability from GPUs to CPUs with OpenACC
(Rob Farber's OpenACC article series published on DrDobbs.com)
(プログラムの一例)
- PGIアクセラレータによるヤコビ反復法のGPU性能高速化
- PGIアクセラレータによる姫野ベンチマークの最適化手順(その1)
- PGIアクセラレータによる姫野ベンチマークの最適化手順(その2)
- PGIアクセラレータを使用した行列積の計算とGPU性能
(Applications and Programming Information )
(仕様書 OpenACC プログラミングモデル)
- OpenACC Specification (ver. 2.5 Oct. 2015)
- OpenACC Specification (ver. 2.0a Aug. 2013)
- OpenACC Specification (ver. 1.0 Nov. 2011, 725KB)
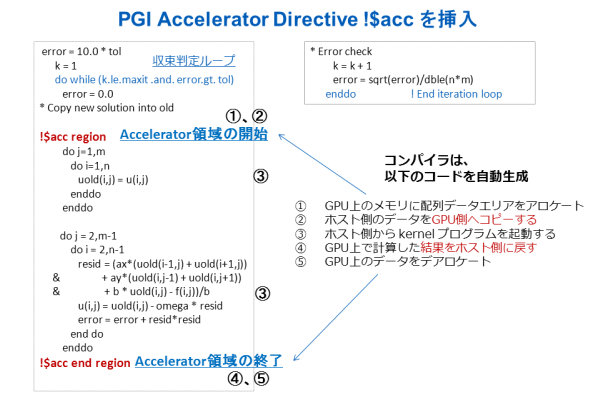
以下のように、-Minfo=accel オプション指定で、CUDA並列化対象ループのコンパイラ翻訳情報により、CUDA並列化の実装詳細が理解できます。

(2) PGI CUDA Fortran プログラミングの例(明示的なCUDA APIの利用)
CUDA™ は NVIDIA 社の GPU のアーキテクチャですが、NVIDIA 社からの CUDA 開発環境は、CUDA C として知られている拡張 C コンパイラとツール群のみが提供されております。CUDA C は、高級言語上から GPU のために CUDA API を使用して明示的にプログラミングすることができるものです。PGI とNVIDIA社は共同で CUDA Fortran の開発を行い、CUDA C と同等な機能を PGI Fortran 95/Fortran 2003 コンパイラに実装しました。すなわち、Fortran 上の CUDA 関数呼び出しと言語拡張を行うことにより、GPU への汎用数値演算処理カーネルをマッピングすることや、x64 プロセッサと GPU 間のデータの移動と配置を明示的に制御できます。PGI CUDA Fortran コンパイラは、ネイティブ Fortran 環境で CUDA C と同等レベルの制御と最適化を実現し、PGI CUDA Fortran とCUDA C の相互運用を可能にします。
(プログラムの一例)
- PGI CUDA Fortran による CUBLAS 4.0 以降の使用方法
- CUDA Fortran による CUDA 4.0 Multi-GPU プログラミング (1) - GPUdirect -
- CUDA Fortran による CUDA 4.0 Multi-GPU プログラミング (2) - UVA -
- CUDA Fortran による CUDA 4.0 Multi-GPU プログラミング (3) - Host Memory -
- PGI CUDA Fortran から CUDA CUFFT ライブラリを呼ぶ
- PGI CUDA Fortran を使用した行列積の計算とGPU性能
- PGI Fortran と CUDA CUBLASを使用した行列積の計算とGPU性能
(CUDA Fortran プログラミングガイド)
(PGI 社 CUDA Fortran に関する記事)
- Introduction to CUDA Fortran article
- CUDA Fortran Data Management article
- CUDA Fortran Device Kernels article
- CUDA Fortran Asynchronous Data Transfers article
- Tuning a Monte Carlo Algorithm on GPUs tutorial article
- Porting the SPEC Benchmark BWAVES to GPUs with CUDA Fortran tutorial article
- Using the CULA GPU-enabled LAPACK Library with CUDA Fortran article
- Using GPU-enabled Math Libraries with PGI Fortran article
- Calling Thrust from CUDA Fortran article
- CUDA Fortran Quick Reference Card (307KB PDF)
- Fortran on GPUs Dr. Lars Koesterke, Texas Advance Computing Center Feb. 2011.
- NVIDIA's Parallel Programming with CUDA Fortran presentation from SC10.
- PGI Accelerator Files examples
- NVIDIA CUDA Zone website

PGI CUDA C for Multi-core x86 コンパイラ (CUDA-x86)
NVIDIA CUDA C プログラムを PGI C コンパイラでコンパイルして、この実行バイナリを x86 (x64) プロセッサ上で実行できる実行モジュールを生成します。この実行モジュールは、x86 (x64) のシステム上に、NVIDIA GPU ボードがない場合、x86(x64) CPU側のマルチコア並びに SSE 機構を使用して動作します。NVIDIA CUDA C プログラムのポータビリティ、汎用性を高めるためのコンパイル・ツールとなります。この機能は、C/C++言語をバンドルした PGI Accelerator 製品にて使用できます。なお、PGI 2011 リリースでは、「機能」のみのリリースであり、性能を最適化したコンパイル機能のリリースは、PGI 2012 リリースの時点で予定されています。(PGI 11.9 において、性能を最適化したベータ版 CUDA-x86 機能がリリースされました。)
(PGI 社 PGI CUDA-x86 説明ページ)
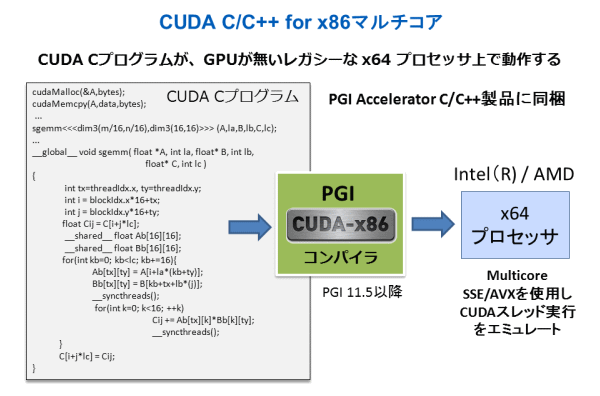
各機能を使用するには、コンパイラ・コマンドのオプションで機能を切り替えるだけ!
PGIコンパイラの各翻訳機能は、コマンドのオプションで指定することによって切り替えることができます。x64+GPU 用実行モジュールを生成するために、複雑なコマンド操作は必要ありません。

アプリケーション・ポーティングを段階的に行うプログラミングモデル
現在、お持ちのアプリケーションを GPU コンピューティングを行えるようにポーティングする際、段階的に性能を向上させてゆくプログラミング方法は必ず必要です。過去には、こうしたアクセラレータ・ボードが開発・リリースされ、そして一瞬で消えてゆく運命を辿ったものが数多くありますが、これは全てソフトウェア開発環境の未成熟性に問題がありました。その中の大きな問題は、プログラミングが難し過ぎたと言う点、すなわち、プログラミングの敷居が高いと言う点でした。また、過去のプログラミング・スタイルの多くは、アクセラレータ用に用意された機能 API、機能関数等を使用したファンクション・コールにより、自身のプログラムを大幅に書き換える必要がありました。しかしこれは、アプリケーション資産の継続性やポータビリティの観点で、多くのユーザの支持を得ることができませんでした。また、この種の API にしても、よりハードウェアに近いレベル(低レベル)で制御しなければならないハードウェア API 的な性格なのか、あるいは、プログラマから見た場合、ハードウェアの抽象化の度合いが高くアプリケーションが書き易い API が提供されているかによっても、ユーザ側の取っ付きやすさは変わります。最近の話題の OpenCL は、CPU-GPU だけでなく混在環境での C プログラミングモデルの標準化ですが、この仕様はハードウェアに近いローレベルな API であり、ITプロフェッショナル以外のユーザが、これを直接プログラミングするのは標準化されたと言えども至難の業です。一方、NVIDIA社の CUDA C 言語や PGI CUDA Fortran は、高いレベルの C / Fortran 言語でプログラムを記述でき、さらにハードウェアを抽象化した API を使用するため、より身近な言語体系で GPU上の SIMD-並列処理の動作を記述できると言う利点があります。とは言え、これでも一般的な科学技術計算、HPC のユーザがプログラミングすることは、やはり難しいと言えましょう。今までの GPU / GPGPU 開発環境は、こうした状況にありました。
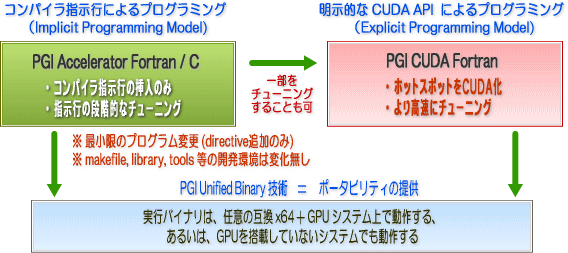
PGIアクセラレータ™ コンパイラは、ユーザに対してさらに身近なプログラミング言語体系を提供します。これは、アプリケーションのポーティングのしやすさにも繋がり、科学者自体が GPGPU を直接使用する機会を高めます。PGIアクセラレータ™を使用すると、以下の図のような「段階的なプログラム移行と最適化」が可能となります。
- 最初に、PGIアクセラレータのディレクティブ/プラグマを挿入し、GPUへのオフロード化を図る。既存の makefile 等の開発環境はそのまま使用可能。その後、性能のチューニングのために、段階的にディレクティブの「句」の調整を行う。これで、ポーティングを終了することも可能。
- さらに、プログラムのホットスポット部分だけを CUDA Fortran で、明示的に CUDA API を使用してコーディング、チューニングを行うことも可能。
- 生成した実行バイナリは、PGI Unified Binary 技術により、任意の x64 (+ GPU) システム上で動作する。バイナリのポータビリティも確保される。
PGIアクセラレータ™ に関する技術情報、FAQ
| PGI Accelerator™ FAQ |
| PGI Accelerator™ TIPS |
▶ ソフテック・テクニカル情報コラム by Kato, SofTek Systems Inc.
